
该示例为参考算法,仅作为在J6上模型部署的设计参考,非量产算法。
1.简介
QCNet(Query-Centric Network)引入了一种query-centric的预测机制,通过对query进行显式建模,增强了对未来轨迹的预测能力。首先,通过处理所有场景元素的局部时空参考框架和学习独立于全局坐标的表示,可以缓存和复用先前计算的编码,另外不变的场景特征可以在所有目标agent之间共享,从而减少推理延迟。其次,使用无锚点查询来周期性检测场景上下文,并且在每次重复时解码一小段未来的轨迹点。这种基于查询的解码管道将无锚方法的灵活性融入到基于锚点的解决方案中,促进了多模态和长期时间预测的准确性。
本文将介绍轨迹预测算法QCNet在地平线征程6平台上的优化部署。
2.性能精度指标


3. 公版模型介绍
QCNet主要由编码器和解码器组成,其作用分别为:
- 编码器:对输入的场景元素进行编码,采用了目前流行的factorized attention实现了时间维度attention、Agent-Map cross attention和Agent与Agent间隔的attention;
- 解码器:借鉴DETR的解码器,将编码器的输出解码为每个目标agent的K个未来轨迹。
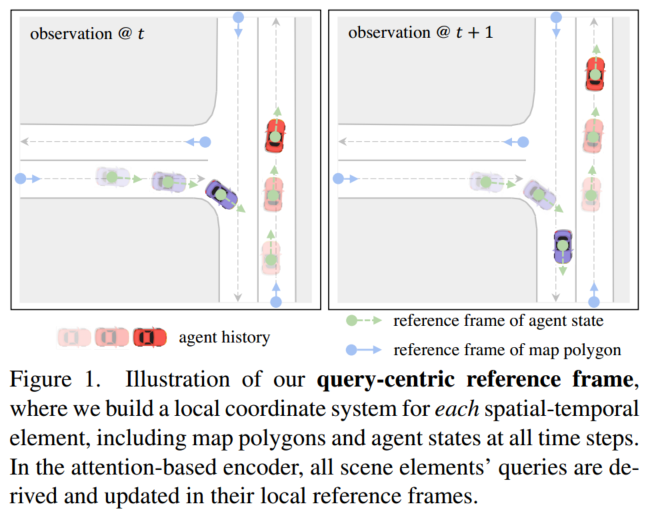
3.1 以查询为中心的场景上下文编码
QCNet首先进行了场景元素编码、相对位置编码和地图编码,对于每个agent状态和map上的每个采样点,将傅里叶特征与语义属性(例如:agent的类别)连接起来,并通过MLP进行编码,为了进一步生成车道和人行横道的多边形级表示,采用基于注意力的池化对每个地图多边形内采样点进行。这些操作产生形状为[A, T, D]的agent编码和形状为[M, D]的map编码,其中D表示隐藏的特征维度。为了帮助agent编码捕获更多信息,编码器还考虑了跨agent时间step、agent之间以及agent与map之间的注意力并重复多次。如下图所示:

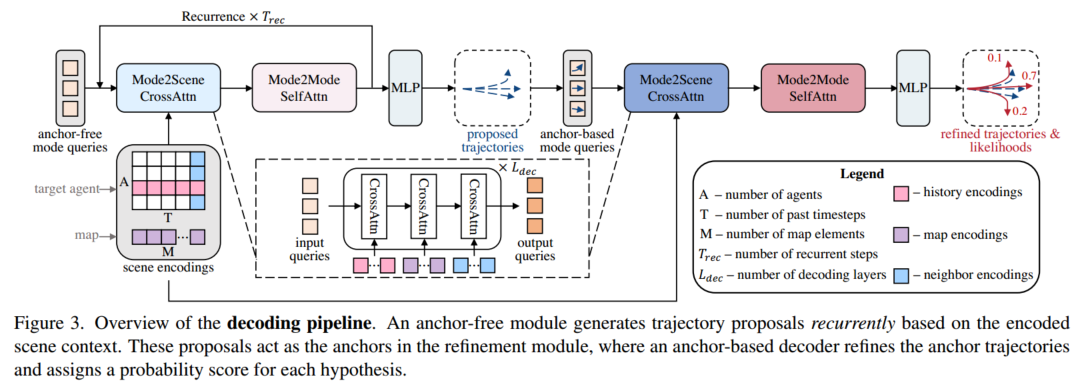
3.2 基于查询的轨迹解码
轨迹预测的第二步是利用编码器输出的场景编码来解码每个目标agent的K个未来轨迹。受目标检测任务的启发,采用类似DETR的解码器来处理这种一对多问题。QCNet使用可学习的、无锚点的query来提出初始轨迹。初始轨迹在refine模块中充当锚点。与Multipath和DenseTNT密集采样的手动设置anchor相比,QCNet在propose模块用数据驱动的方式生成k个自适应anchor。为了减轻query的上下文提取负担并提高anchor的质量,将类似DETR的解码器推广为循环方式。通过 $T_{rec}$个循环,具有上下文感知的模态query仅通过每个循环末尾的MLP解码$T^’/T_{rec}$未来的waypoints。在随后的循环中,这些query再次成为输入,并提取与接下来几个路径点预测相关的场景上下文。相关流程如下所示:
4. 地平线部署优化
改动点:
相对于公版网络结构,在不大幅影响精度的情况下,对网络进行了裁剪,实现了性能的提升,相关细节见 4.1.1 章节;
优化FourierEmbedding结构,去除其中的所有edge_index,直接计算形状为[B, lenq, lenk, D]的相对信息r;
重构代码,将AttentionLayer中的query形状设为[B, lenq, 1, D] , key形状为[B, 1, lenk, D], r形状为[B, lenq, lenk, D],利于性能提升;
适当减少了相对位置编码RAttentionLayer中的Layermorm操作,对精度影响不大;
decoder 复用 agent encoder 的 feature,并去除了decoder propose 阶段a2m的RAttention;
- 适配流式推理:预测算法QCNet的两种推理方式,一是对所有历史帧数据并行encode后送入decode预测下一帧;二是流式推理按照时序,逐帧encode后,最后一帧将前面encoder的结果拼接后送入decoder。流式推理符合实际部署的逻辑,但hbminfer速度会变慢。实际部署数据按时序逐帧给出,应当采用流式推理方案。
## 4.1 性能优化
### 4.1.1 网络裁剪
为了更优异的性能表现,参考算法相对于公版做了裁剪,主要为以下参数:
### 4.1.2 代码重构
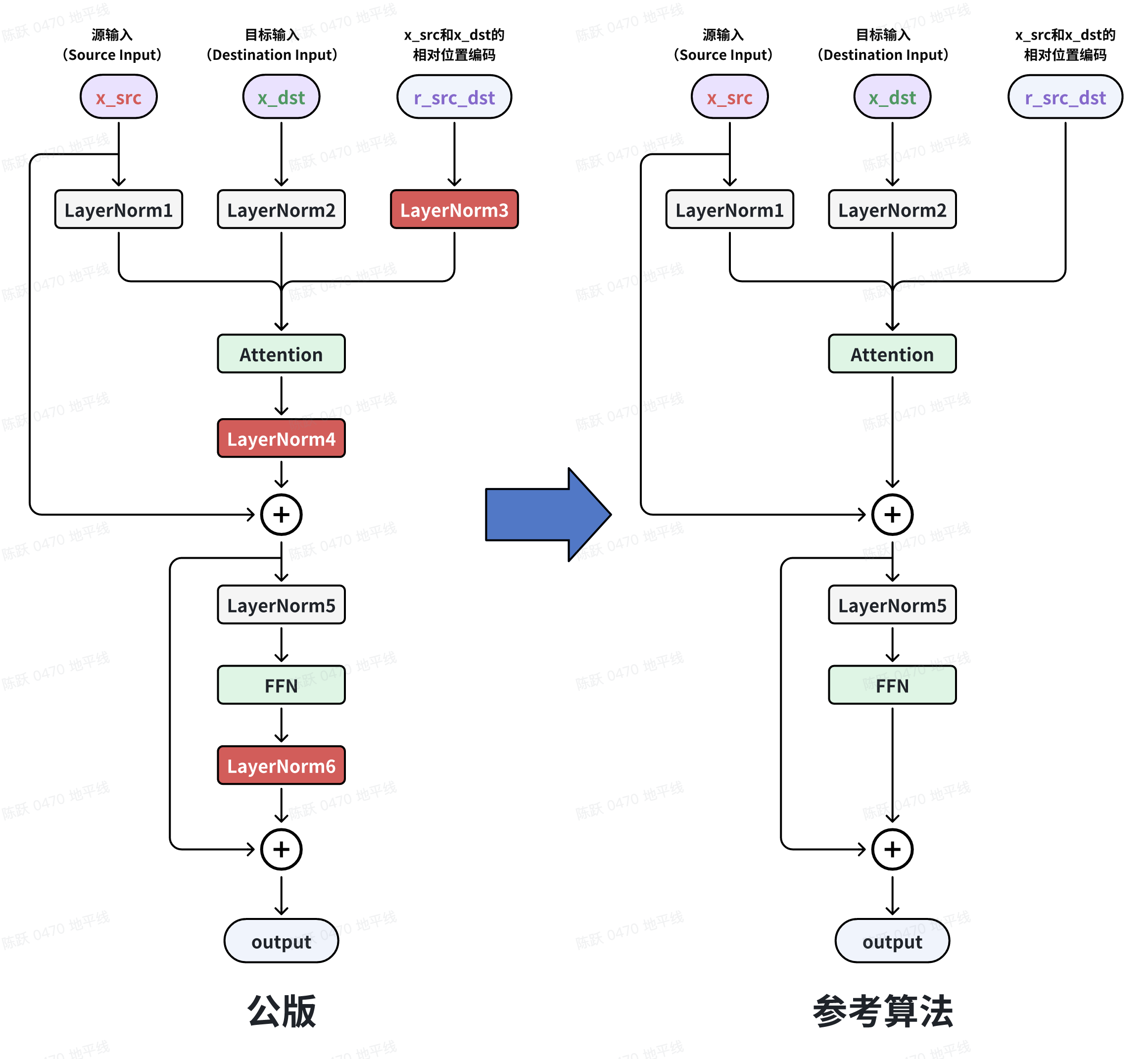
FourierEmbedding将每个场景元素的极坐标转换成傅里叶特征,以方便高频信号的学习。 但是公版QCNet 使用了大量edge_index索引操作, 使得模型中存在大量BPU暂不支持的index_select、scatter等操作。QCNet参考算法重构了代码,去除了FourierEmbedding中的所有edge_index,agent_encoder编码器注意力层的query形状设为[B, lenq, 1, D] , key形状为[B, 1, lenk, D], r形状为[B, lenq, lenk, D],相关代码如下所示:
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/rattention.py
4.1.3 FourierConvEmbedding
为了提升性能,主要对FourierEmbedding做了以下改进:
Embedding和Linear层全部替换为了对BPU更友好的Conv1x1;
删除self.mlps层中的LayerNorm,对精度基本无影响;
- 将公版代码中的torch.stack(continuous_embs).sum(dim=0)直接优化为了add操作,获得了比较大的性能收益。
对应代码如下所示代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/fourier_embedding.py
4.1.4 RAttentionLayer
从实验结果来看,浮点精度反而略有提升。相关代码如下:
代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/rattention.py
4.1.5 Decoder
为了优化性能,去除了decoder中proposal阶段a2m的RAttenion操作,相关代码如下:
代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/qc_decoder.p
4.2 量化精度优化
4.2.1 FourierConvEmbedding
QCNetMapEncoder和QCNetAgentEncode的输入中存在距离计算、torch.norm等对量化不友好的操作,为了提升量化精度,将输入全部置于预处理中,相关代码如下所示:
另外, 由于QCNet模型weight init是分算子类型初始化的,embedding改conv后 init weight应当对齐embedding类型,具体为embedding的weight是std=0.02;而且,相对速度,距离等会和角度量一起计算,保持相近的scale更加有利于量化。因此,在预处理时,将position等量输入除以10后输入到模型,相关代码如下所示:
代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/preprocess.py
4.2.2 训练模块不量化
模型中存在 scale分量只用于计算 loss,建议相关过程不量化,即在其前面插入 Dequanstub,否则会影响 QAT训练。相关代码:
代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/qc_decoder.py
4.2.3 量化配置
首先使用QAT的精度debug工具获取量化敏感节点,然后在Calibration和量化训练时,分别对两个输出的 top86和 top42 的量化敏感节点配置为int16量化;并且在量化训练时固定了激活的 scale,对量化精度更友好。相关代码如下:
4.3 不支持算子替换
4.3.1 cumsum
公版模型的QCNetDecoder中使用了J6暂不支持的torch.cumsum算子,参考算法中将其替换为了Conv1x1,相关代码如下:
/usr/local/python3.10/dist-packages/hat/models/models/task_moddules/qcnet/qc_decoder.py
4.3.2 取余操作
公版代码实现:
代码路径:/usr/local/python3.10/dist-packages/hat/models/models/task_modules/qcnet/utils.py
4.4 其它优化
4.4.1 适配流式推理
QCNet存在两种推理方式:
对所有历史帧数据并行encode后送入decode预测下一帧;
- 按照时序,逐帧encode后,最后一帧将前面encoder的结果拼接后送入decoder的流式推理。
流式推理符合实际部署的逻辑,但推理速度会变慢。但是,实际部署数据按时序逐帧给出,应当采用流式推理方案进行bc模型的推理。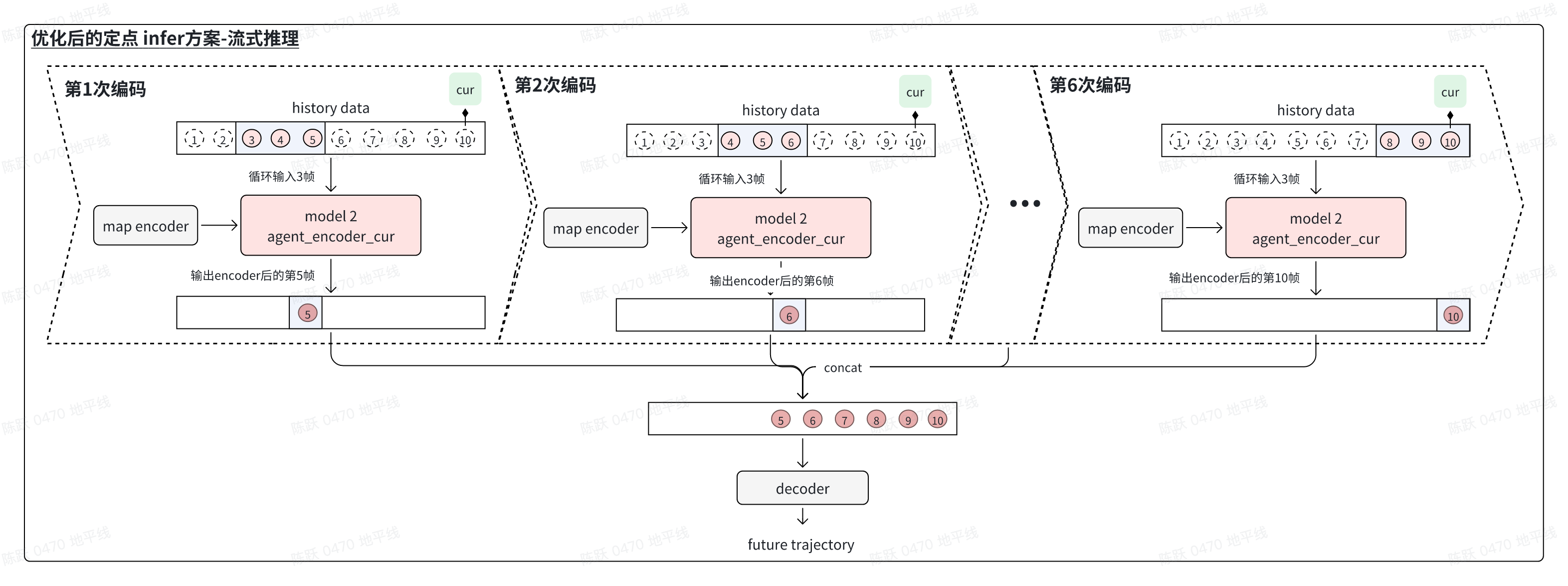
# 5. 总结与建议
## 5.1 性能优化 在不大幅影响浮点精度的情况下对模型进行适当的裁剪,删除若干 LayerNorm,以及其它算子替换,提升部署效率;
- 重构 AttentionLayer,将 query、key、相对信息 r的形状均改为四维,对部署更加友好;
## 5.2 性能评估
QCNet模型中存在索引类操作,建议在使用hrt_model_exec工具进行板端性能评测时使用真实数据输入。
# 附录 - 论文:QCNet
- 参考算法使用指南:J6 参考算法使用指南

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)