
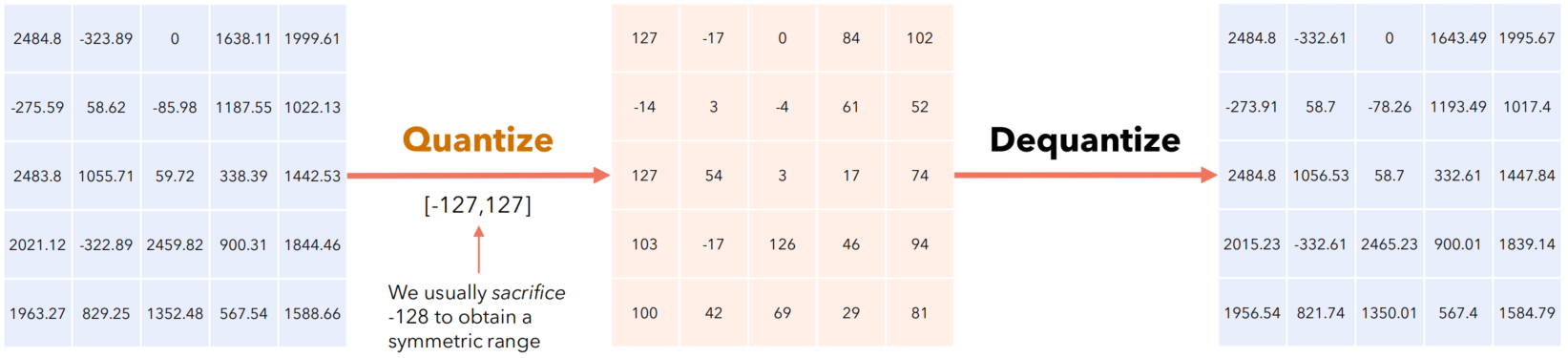
什么是模型参数量化与反量化?其实量化和反量化并不是什么新知识,我们在对图像做预处理时就用到了量化和反量化。回想一下,我们通常会将一张 uint8 类型、数值范围在 0~255 的图片归一成 float32 类型、数值范围在 0.0~1.0 的张量,这个过程就是反量化。类似地,我们经常将网络输出的范围在 0.0~1.0 之间的张量调整成数值为 0~255、uint8 类型的图片数据,这个过程就是量化。所以量化本质上只是对数值范围的重新调整。
网络模型参数量化是一种减少模型大小和提高推理速度的技术,通过降低模型参数的精度(例如,从32位浮点数减少到8位整数)来实现。
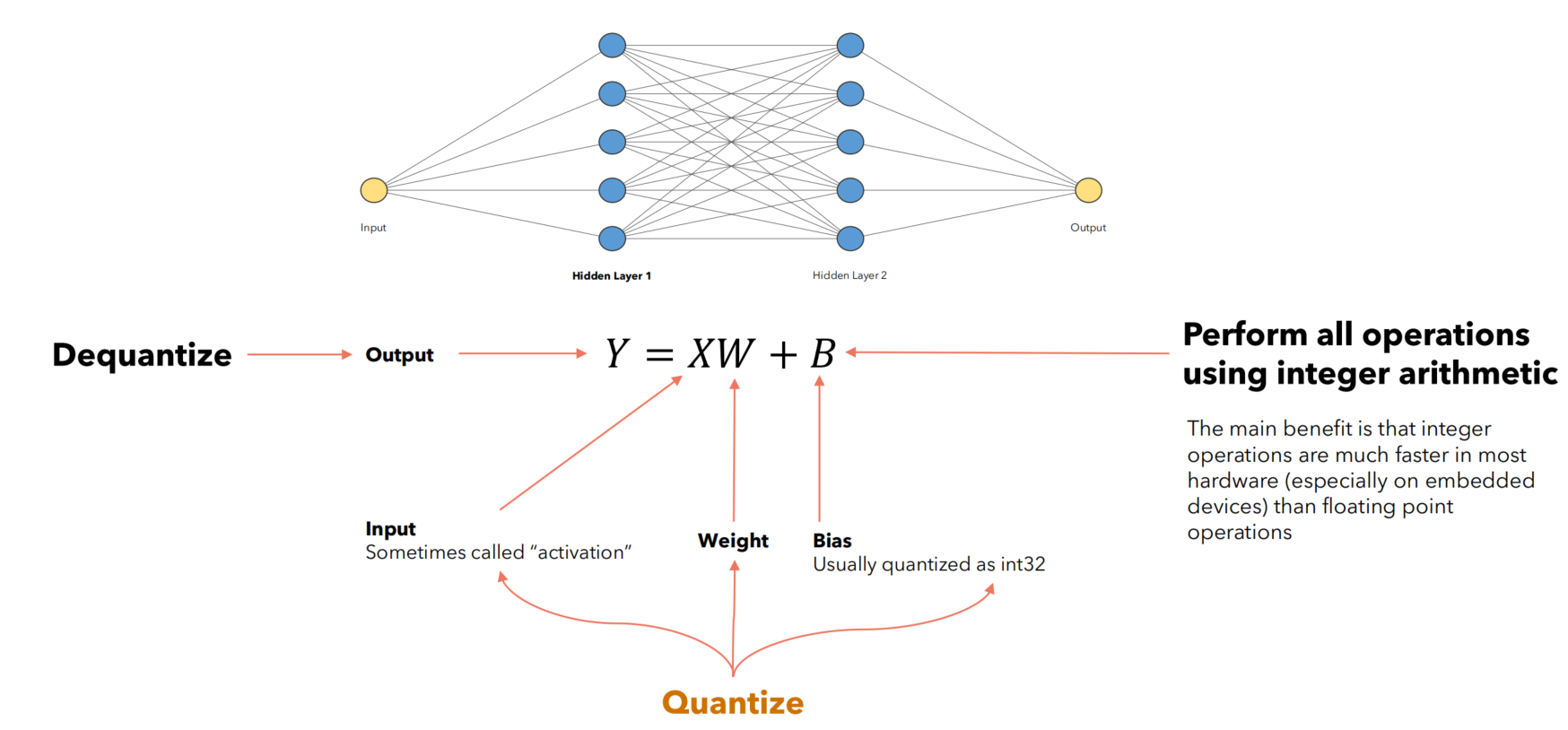
参数量化有三个好处:1,减少内存消耗;2,减少推理时间,因为数据类型更简单计算更快;3,减少能源消耗,因为推理一帧,计算量变少了,推理更快了,能源消耗降低了。
反量化操作是为了让量化后的神经元输出与量化前的输出变化不大,不然整型变换后相乘的参数值会与原本的浮点值差很多,对于后面的神经元来说输入相当于就变了,模型准确率自然大打折扣,所以激活值需要经过反量化,从而使得后面的神经元察觉不到输入发生变化,对于整个神经网络来说,输入什么就输出什么,仿佛没有量化操作参与,精度自然能保持。
在量化方法中,非对称量化和对称量化是两种常见的量化策略,它们各有特点和应用场景。白话说就是对称量化时0点对齐。
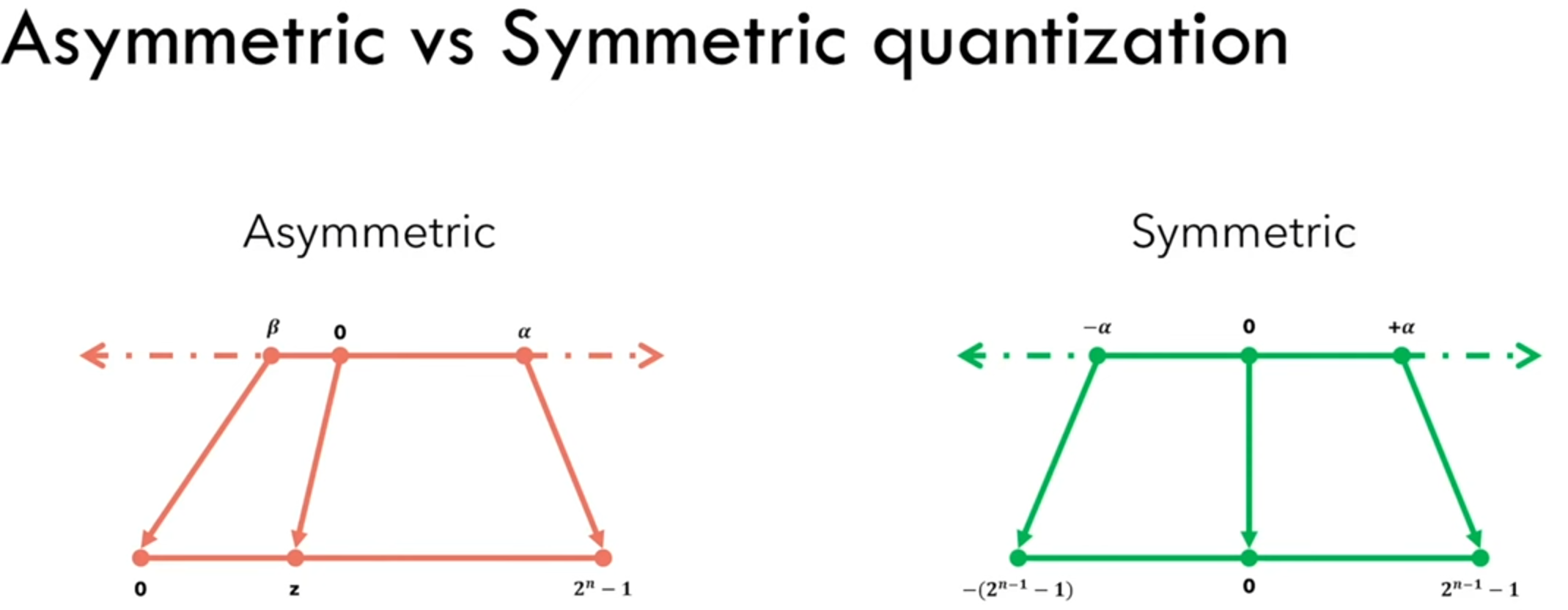
总结对称量化和非对称量化的优点缺点
对称量化的优点:
没有偏移量,可以降低计算量
分布在正负半轴的权值数值均可被充分利用,具有更高的利用率;
对于深度学习模型,可以使用int8类型的乘法指令进行计算,加快运算速度;
能够有效的缓解权值分布在不同范围内的问题。
对称量化的缺点:
对于数据分布在0点附近的情况,量化的位数可能不够;
数据分布的范围过于分散,如果缺乏优秀的统计方法和规律,会导致量化效果不佳。
非对称量化的优点:
通过偏移量可以保证量化数据分布在非负数范围内,可以使得分辨率更高;
适合数据分布范围比较集中的情况。
非对称量化的缺点:
对于偏移量的计算需要额外的存储空间,增加了内存占用;
偏移量计算需要加减运算,会增加运算的复杂度;
对于深度学习模型,要使用int8类型的乘法指令进行计算,需要进行额外的偏置操作,增加了运算量。
其中地平线的工具链PTQ里hb_model_modifier工具的输出内容有可供候选的可删除节点(即模型中的位于输入输出位置的所有Transpose、Quantize、Dequantize、DequantizeFilter、Cast、Reshape、Softmax节点)。
其中Quantize节点用于将模型float类型的输入数据量化至int8类型,其计算公式如下:
qx = clamp(round(x / scale) + zero_point, -128, 127)
- round(x) 实现浮点数的四舍五入。
- clamp(x) 函数实现将数据钳位在-128~127之间的整数数值。
- scale 为量化比例因子。
- zero_point 为非对称量化零点偏移值,对称量化时 zero_point = 0 。
C++的参考实现如下:
static inline float32_t _round(float32_t const input) {
std::fesetround(FE_TONEAREST);
float32_t const result{std::nearbyintf(input)};
return result;
}
static inline int8_t int_quantize(float32_t value, float32_t const scale) {
value = _round(value / scale);
value = std::min(std::max(value, -128.0f), 127.0f);
return static_cast(value);
}
Dequantize节点则用于将模型int8或int32类型的输出数据反量化回float或double类型,其计算公式如下:
deqx = (x - zero_point) * scale
C++的参考实现如下:
目前地平线的BPU只支持对称量化。



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)