参考标题:PoliFormer: Transformer赋能的室内导航革新
原标题:PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
论文链接:https://arxiv.org/pdf/2406.20083
项目链接:https://poliformer.allen.ai/
作者单位:PRIOR @ Allen Institute for AI
论文思路:
本文提出了 POLIFORMER(Policy Transformer),这是一种仅使用RGB信息的室内导航代理,通过大规模端到端强化学习训练,尽管仅在仿真环境中训练,却能够无缝泛化到现实世界,而无需额外适配。POLIFORMER采用了基础的vision transformer编码器和causal transformer解码器,赋予了其长期记忆和推理能力。它通过数亿次的交互,在多样化的环境中进行训练,利用并行化的多机回合(multi-machine rollouts) 实现高吞吐量的高效训练。POLIFORMER是一个卓越的导航器,在两个不同的实体机器人——LoCoBot和Stretch RE-1,以及四个导航基准测试中,展现了当前最先进的性能。它突破了以往工作的瓶颈,在CHORES-S基准测试的目标物体导航任务中取得了前所未有的85.5%的成功率,绝对提升了28.5%。此外,POLIFORMER还可以轻松扩展至多种下游应用,如目标跟踪、多物体导航和开放词汇导航,无需微调。
主要贡献:
(i) POLIFORMER,一个基于transformer的策略模型,通过大规模仿真中的RL训练,跨越四个仿真基准测试以及现实世界的两个具身机器人实现了最先进的(SoTA)结果。
(ii) 一个训练方法,使得能够通过基于策略的RL使用大规模神经模型进行有效的端到端策略学习。
(iii) 一个通用的导航器 POLIFORMER-BOXNAV,能够零样本应用于多个下游导航任务。
论文设计:
强化学习(Reinforcement Learning, RL)已被广泛用于训练具身机器人代理执行各种室内导航任务。通过使用基于DDPPO [1]的大规模、基于策略的端到端RL训练,采用浅层的基于GRU的架构[2]可以实现接近完美的PointNav1性能。然而,这种方法在更难的导航问题上,如物体目标导航(Object Goal Navigation, ObjectNav [3])中,未能取得同样的突破。在ObjectNav任务中,代理需要探索环境以定位并导航到指定类型的目标物体。由于训练不稳定性和更宽、更深的模型(例如扩展的transformer模型[4])需要过长的训练时间,RL方法在ObjectNav任务中通常未能超越浅层的GRU架构。
不同于采样效率低且常常需要复杂的 reward shaping 和辅助损失的基于策略的强化学习(RL)[5],模仿学习(Imitation Learning, IL)在物体目标导航(ObjectNav)任务中近期显示出良好前景。Ehsani等人(2023)[6]展示了基于transformer的SPOC代理,当被训练模仿启发式最短路径规划器时,能够稳定训练,具有较高的样本效率,并且在其基准测试中显著优于先前的RL方法。然而,SPOC最终未能达到完全掌握,其成功率停滞在约57%。重要的是,正如本文在实验中所展示的,SPOC的性能在进一步扩展数据和模型深度时似乎没有显著提升;本文怀疑这是由于状态空间探索不足所致,因为专家轨迹数据集通常包含的错误恢复案例较少,可能导致由于误差累积[7]或推理期间复杂的域偏移而产生次优表现。
与模仿学习(IL)不同,强化学习(RL)要求代理通过交互式的试错过程进行学习,从而能够深入探索状态空间。这种探索有可能使代理学习到比专家演示中更优越的行为。这引发了一个问题:本文是否能够结合SPOC类架构的建模洞见与RL的探索能力,训练出一个出色的导航代理?不幸的是,由于RL的样本效率低下以及在RL算法中使用深层(如transformer)架构的复杂性,这一目标不能简单实现。在本工作中,本文提出了一种有效的方法,利用RL训练大型的基于transformer的架构,突破了过去工作的瓶颈,并在四个基准测试中取得了最先进的(SoTA)结果。
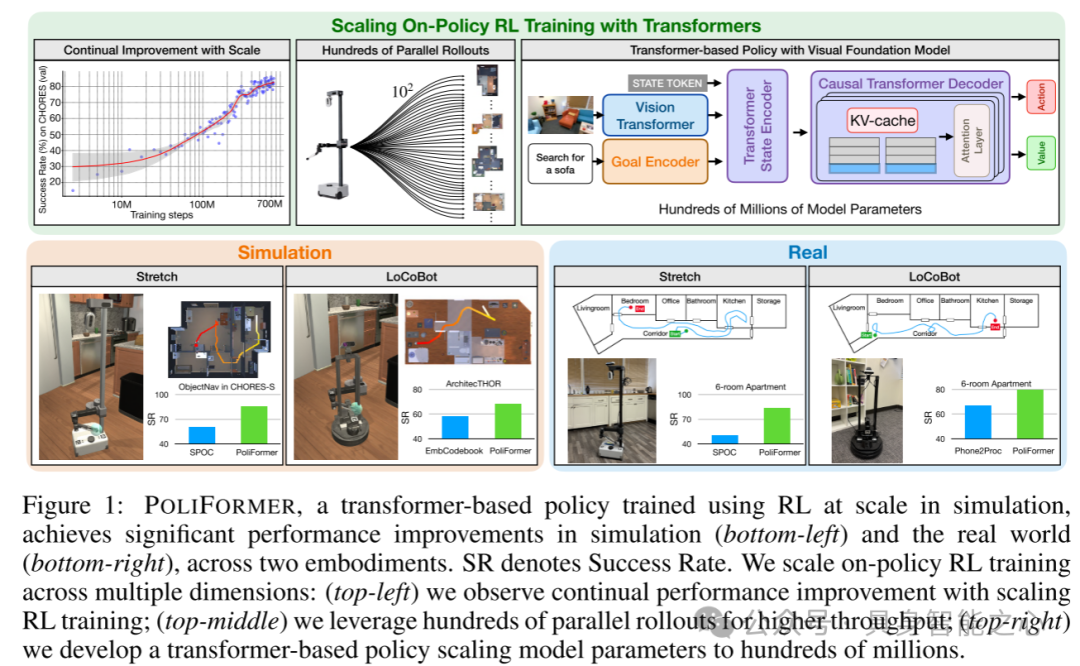
图1:POLIFORMER,一个通过大规模仿真中的RL训练的基于transformer的策略模型,在仿真(左下角)和现实世界(右下角)的两个具身机器人中都取得了显著的性能提升。SR表示成功率。本文在多个维度上扩展了基于策略的RL训练:(左上角)本文观察到随着RL训练规模的扩展,性能持续提升;(中上方)本文利用数百个并行回合以提高训练吞吐量;(右上方)本文开发了一个基于transformer的策略,模型参数扩展至数亿。
本文的方法,POLIFORMER,是一种基于transformer的模型,使用基于策略的强化学习(RL)在AI2THOR [8]模拟器中大规模训练,能够无需任何适应就能有效地在现实世界中进行导航。本文强调了三个主要的设计决策,使这一结果成为可能。(i) 架构的规模:基于SPOC架构,本文开发了一个完全基于transformer的策略模型,使用强大的视觉基础模型DINOv2 [9](a vision transformer),集成了用于改进状态总结的transformer状态编码器,并采用transformer解码器进行显式的时间记忆建模(图1,右上角)。重要的是,本文的transformer解码器是因果型的,使用KV-cache[10],这使得本文在收集回合数据时避免了巨大的计算成本,使RL训练变得可行。(ii) 回合的规模:本文利用数百个并行回合和大批量,这带来了高训练吞吐量,并允许本文通过大量的环境交互进行训练(图1,中上)。(iii) 多样化环境交互的规模:本文在15万个程序生成的PROCTHOR房屋[11]中,使用优化的Objaverse [12, 13, 14]资产进行RL的大规模训练,使验证集表现持续提升(图1,左上)。
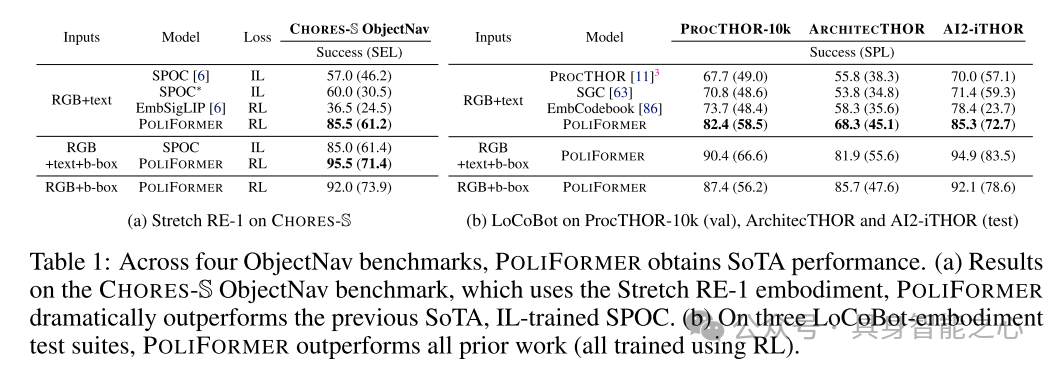
POLIFORMER在多个仿真导航基准测试中取得了卓越的成绩。在CHORES-S上,它达到了令人印象深刻的85.5%成功率,比之前的最先进模型[6]有+28.5%的绝对提升。同样,它在ProcTHOR(+8.7%)、ArchitecTHOR(+10.0%)和AI2-iTHOR(+6.9%)上也获得了最先进的成功率;见图1,左侧。这些结果在两个具身机器人LoCoBot [15]和Stretch RE-1 [16]上保持一致,虽然它们的动作空间不同。在现实世界中(图1,右侧),在从仿真到现实的零样本迁移设置中,使用LoCoBot(+13.3%)和Stretch RE-1(+33.3%),它也优于ObjectNav的基线模型。
本文进一步训练了 POLIFORMER-BOXNAV,它接受一个边界框(例如,从现成的开放词汇目标检测器[18, 19]或VLMs [20, 21]获取)作为其目标规格,取代了给定的类别。这种抽象使得POLIFORMER-BOXNAV成为一个通用的导航器,可以通过外部模型进行“提示”,类似于Segment Anything [22]的设计。它在探索环境时非常高效,一旦观察到边界框,就会直接朝目标移动。POLIFORMER-BOXNAV在向训练导航基础模型的方向迈出了重要一步;无需进一步训练,这个通用的导航器就可以在现实世界中用于多个下游任务,如开放词汇的ObjectNav、多目标ObjectNav、跟随人类以及目标追踪等。
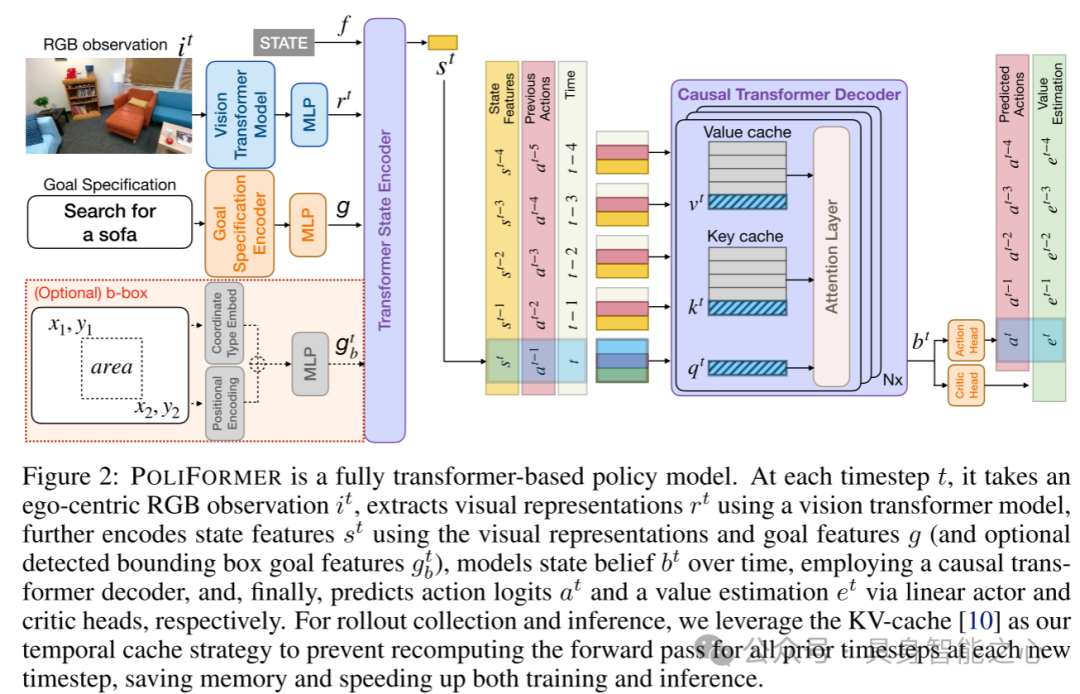
图2:POLIFORMER 是一个完全基于transformer的策略模型。在每个时间步 ,它接收自我视角的RGB观测值 ,使用视觉transformer模型提取视觉表示 ,进一步通过视觉表示和目标特征 (以及可选的检测到的边界框目标特征 )编码状态特征 ,并通过因果transformer解码器建模状态置信度 。最后,通过线性actor和critic头分别预测动作logits 和价值估计 。在回合数据收集和推理过程中,本文利用KV-cache[10]作为时间缓存策略,避免在每个新的时间步重新计算所有先前时间步的前向传递,从而节省内存并加速训练和推理过程。
图3:本文使用 POLIFORMER-BOXNAV 进行零样本任务,包括找到一本特定标题的书、导航到厨房、依次导航到多个物体,以及在办公楼内跟随一辆玩具车移动。
实验结果:
表1:在四个ObjectNav基准测试中,POLIFORMER 取得了最先进的(SoTA)性能。(a)在使用Stretch RE-1具身机器人进行的CHORES-S ObjectNav基准测试中,POLIFORMER显著超越了之前的最先进模型,IL训练的SPOC。(b)在三个LoCoBot具身测试套件中,POLIFORMER超越了所有先前的工作(均使用RL训练)。
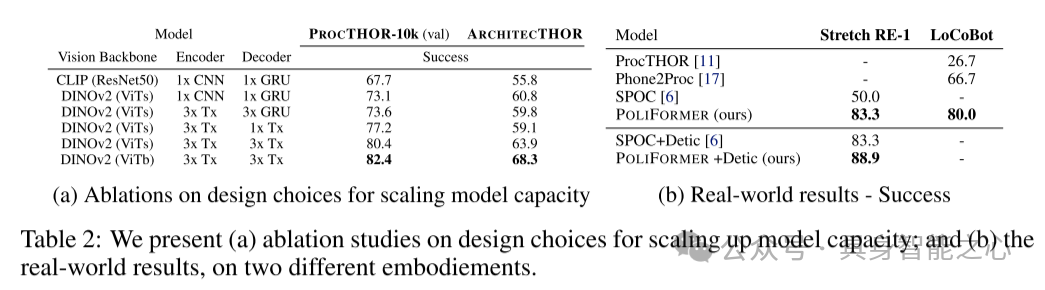
表2:本文展示了(a)关于扩展模型容量设计选择的消融研究;以及(b)在两种不同具身机器人上的真实世界结果。
总结:
本文提供了一种扩展强化学习用于长时导航任务的方案。本文的模型POLIFORMER在四个仿真基准测试和两个现实世界基准测试中,在两种不同具身机器人上都取得了最先进的(SoTA)结果。本文还展示了POLIFORMER在下游日常任务中具有显著的潜力。
引用:
文章转载自公众号:具身智能之心
原文链接:https://mp.weixin.qq.com/s/YGVzK0fWXZS8Qt0Jn2qT5w




'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)