
原标题:One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
论文链接:https://arxiv.org/pdf/2409.06366
代码链接:https://github.com/nico-bohlinger/one_policy_to_run_them_all
作者单位:达姆施塔特工业大学 波兹南理工大学 German Research Center for AI (DFKI) IDEAS NCBR Hessian.AI Centre for Cognitive Science

1.论文思路:
2.论文设计:
在过去的几年里,机器人社区已经掌握了鲁棒步态生成的问题。在深度强化学习(Deep Reinforcement Learning, DRL)技术的帮助下,腿部机器人可以展示出令人印象深刻的运动技能。有许多高灵活性的四足机器人运动的例子,比如学习以高速奔跑、跳过障碍、在崎岖地形上行走、做倒立和完成跑酷课程[1, 2, 3, 4, 5, 6]。实现这些灵活运动通常依赖于在许多并行的仿真环境中进行训练,并使用精心调整或自动生成的任务难度课程[7, 8]。即使是在真实机器人上直接学习简单的运动行为也是可能的,但需要更高效的学习方法[9, 10]。类似的方法也被应用于生成双足和人形机器人的鲁棒行走步态[11, 12, 13]。通过在训练过程中广泛使用域随机化(Domain Randomization, DR)[14, 15],学习到的策略可以有效地迁移到现实世界,并能够在各种地形上工作。此外,像学生-教师学习[1, 16]这样的技术,或者在学习过程中加入基于模型的组件[17, 18]或约束[19, 20, 21],可以进一步提高学习效率和策略的鲁棒性。
同时,计算能力的新进展、大规模数据集的可用性以及基础模型的发展正在为人工智能开辟新的前沿,允许本文实现和学习更复杂和智能的代理行为。未来的机器人将需要将这些模型融入控制流程中[22, 23]。然而,要充分利用基础模型,本文需要能够将这些高层次策略与机器人的低层次控制集成起来。长期目标是开发用于运动的基础模型,允许零样本(或少样本)部署到任何任意平台。然而,要实现这一目标,必须使底层学习系统适应不同的任务和形态。因此,本文认为多任务强化学习(Multi-Task Reinforcement Learning,MTRL)问题是未来机器人运动研究的一个基本主题,实际上,这一表述最近已经引起了社区的兴趣,使用了结构化[24]和端到端学习方法[25]。MTRL算法在任务之间共享知识,并学习一个通用的表示空间,可以用来解决所有任务[26, 27]。为了将不同大小的观测和动作空间映射到共享表示空间内外,通常的实现方法是用零填充观测和动作以适应最大长度[28],或者为每个任务使用一个单独的神经网络头[26]。这些方法允许高效的训练,但在尝试迁移到新任务或环境时可能会受到限制:对于每个新机器人,训练过程必须从头开始,因为不同的具身智能需要不同的超参数、奖励系数、训练课程等。即使在相同的机器人形态情况下,例如四足机器人,当机器人关节数量不同时,训练的策略也不能轻松迁移。这在尝试跨不同类型的形态重用学习到的步态时更为明显。这一问题与机器人学中的基本对应问题密切相关[29],因为策略必须学习不同动作和观测空间以及具身智能本身之间的内部映射,这定义了机器人的运动学。在实践中,腿部机器人关节和脚的数量决定了其动作和观测空间的大小,每个新机器人可能有所不同。这通常会阻碍现有策略的直接迁移,因为学习架构完全依赖于特定的机器人平台。
为了解决这个问题,并迈向更强大和通用的策略,使其可以作为运动基础模型使用,本文提出了一种新颖的多任务强化学习(MTRL)框架,该框架能够轻松有效地同时学习具有多种不同形态的运动任务。本文的方法基于一种新颖的神经网络架构,能够处理不同大小的动作和观测空间,使策略能够轻松适应各种机器人形态。此外,本文的方法还允许将策略零样本部署到未见过的机器人上,并在新目标平台上进行少样本微调。本文首先通过理论分析,然后通过在16个机器人上训练单一的运动策略,展示了本文方法的有效性,这些机器人包括四足机器人、六足机器人、双足机器人和人形机器人。最后,本文将学习到的策略零样本迁移到两个仿真机器人和三个实际机器人上,展示了本文方法的可迁移性和鲁棒性。

图1:上图 – 本文在仿真中为多个机器人具身智能训练单一的运动策略。下图 – 通过在训练过程中随机化具身智能和环境动态,本文可以将该策略迁移并部署到三个现实世界的平台上。
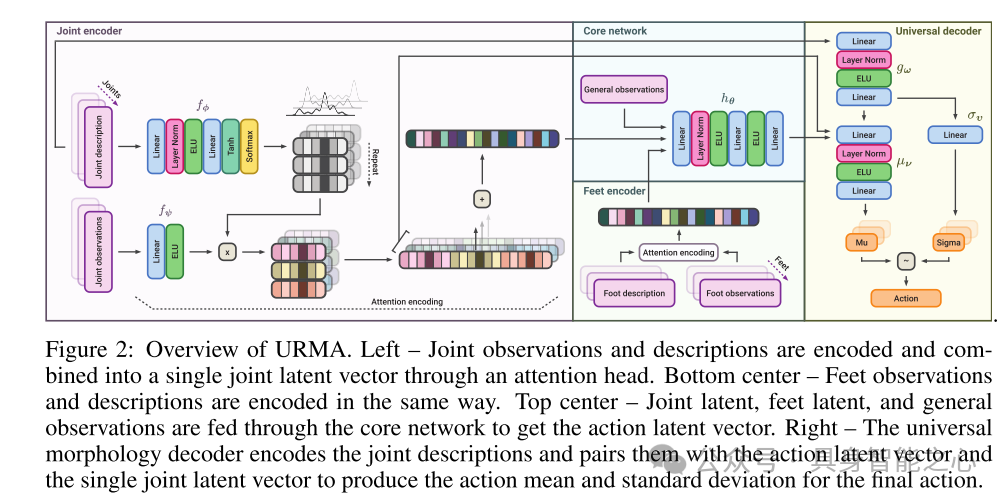
3.实验结果:
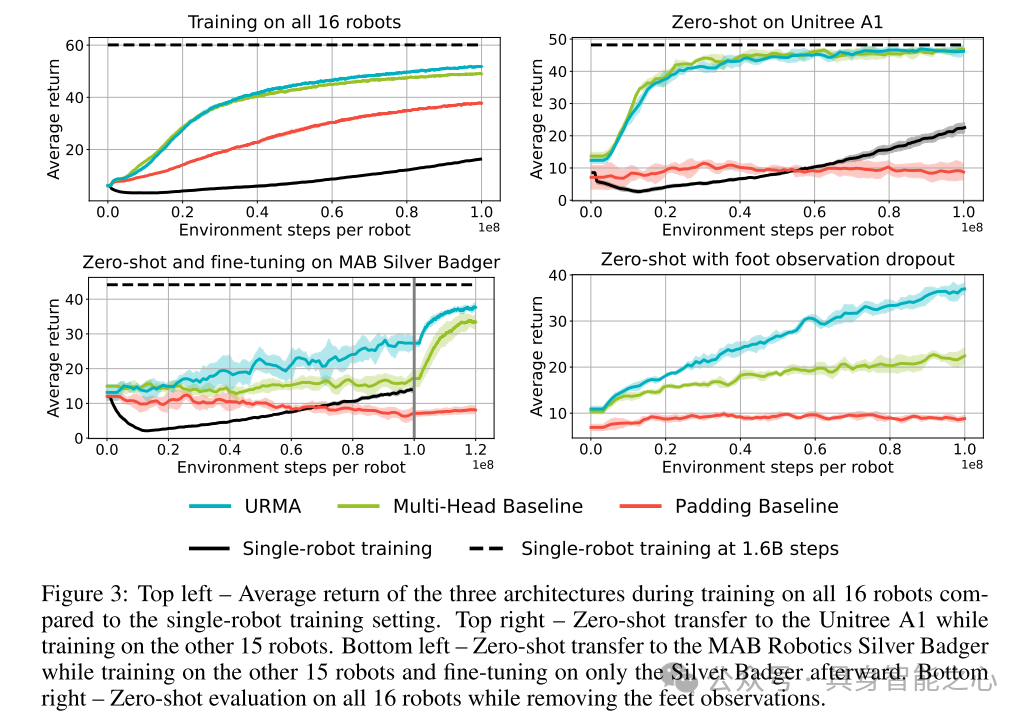
图3:左上 – 三种架构在所有16个机器人上训练期间的平均回报,与单机器人训练设置相比。右上 – 在训练其他15个机器人时零样本迁移到Unitree A1。左下 – 在训练其他15个机器人时零样本迁移到MAB Robotics Silver Badger,并随后仅在Silver Badger上进行微调。右下 – 移除足部观测后对所有16个机器人进行零样本评估。
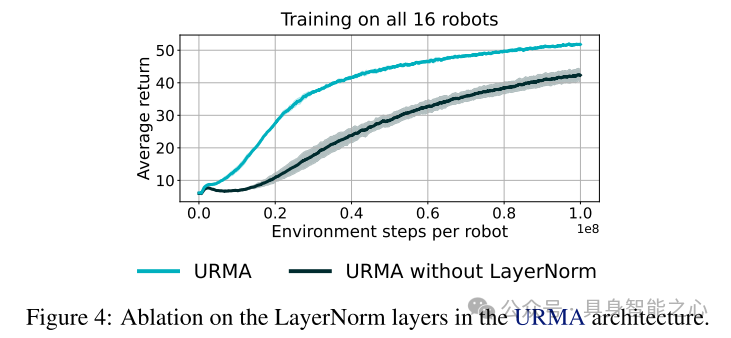
图4:URMA架构中LayerNorm层的消融实验。
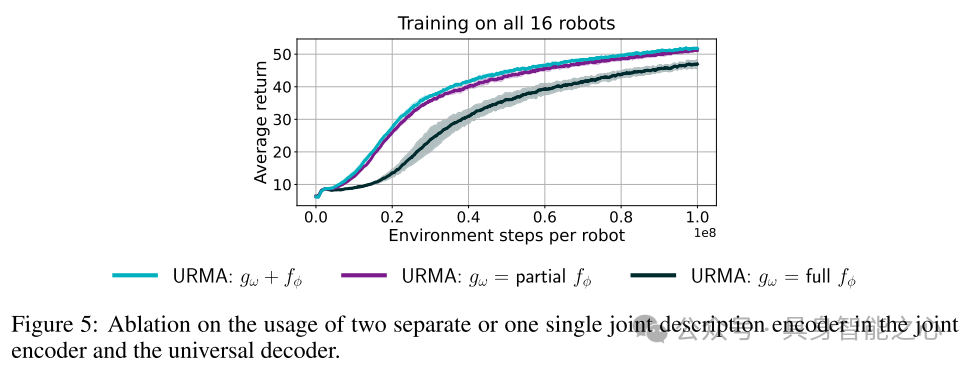
图5:在关节编码器和通用解码器中使用两个独立的关节描述编码器或一个单一关节描述编码器的消融实验。
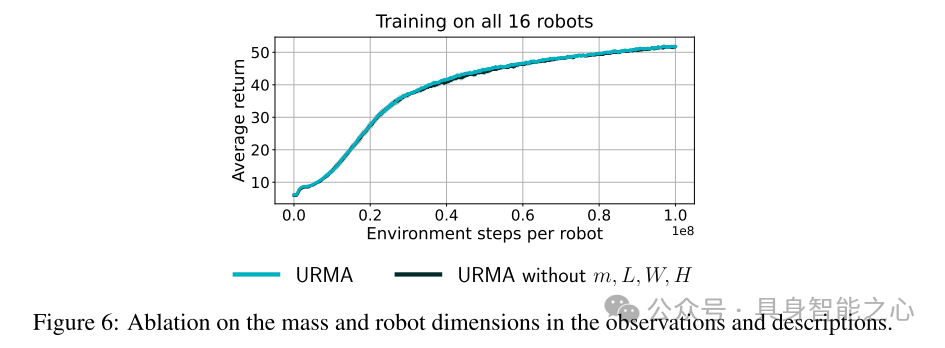
图6:对观测和描述中的质量和机器人尺寸进行的消融实验。
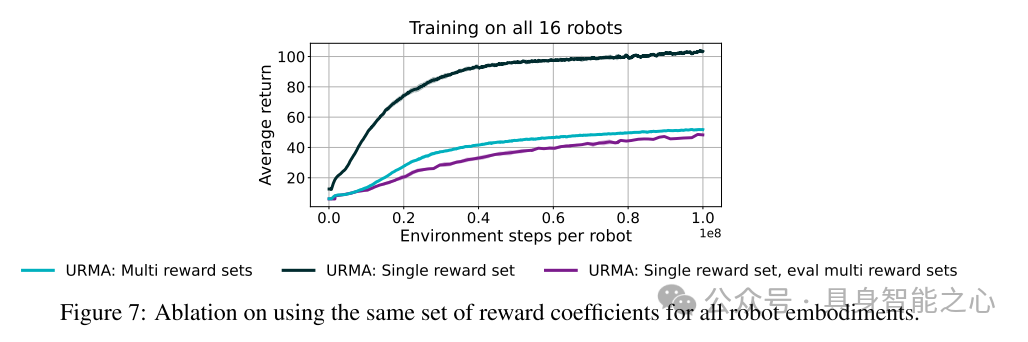
图7:对所有机器人具身智能使用相同奖励系数的消融实验。
4.总结:
本文提出了URMA,一个开源框架,用单一的神经网络架构端到端学习不同类型机器人形态的鲁棒运动。本文的灵活学习框架和高效的编码器和解码器使URMA能够为来自三种不同腿型机器人形态的16种不同具身智能学习单一控制策略。本文通过对任务平均风险界的理论分析,强调了URMA的学习效率,并将其与之前的工作进行了比较。在实践中,URMA在所有机器人上的训练中达到了更高的最终性能,显示出更高的观测丢失鲁棒性,并且在新机器人上的零样本能力优于MTRL基线。此外,本文在现实世界中将相同的策略零样本部署到两个已知和一个未知的四足机器人上。本文认为,这种多具身智能学习设置可以轻松扩展到更复杂的场景,并可以作为运动基础模型的基础,这些模型可以在机器人控制的最低层次上运行。最后,URMA架构足够通用,不仅可以应用于任何机器人具身智能,还可以应用于任何控制任务,使任务泛化(包括非运动任务)成为未来研究的一个有趣方向。
引用:
本文转载自公众号:具身智能之心
原文链接:https://mp.weixin.qq.com/s/fcjYdOWBeW45MZdZyjRXeA

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)