
自动泊车端到端算法ParkingE2E介绍
一、算法介绍:
输入:1. 去完畸变的RGB图 2. 目标停车位
输出:路径规划

论文精读博客参考链接:https://blog.csdn.net/qq_45933056/article/details/140968352
源代码:https://github.com/qintonguav/ParkingE2E
二、算法部署后的demo效果展示
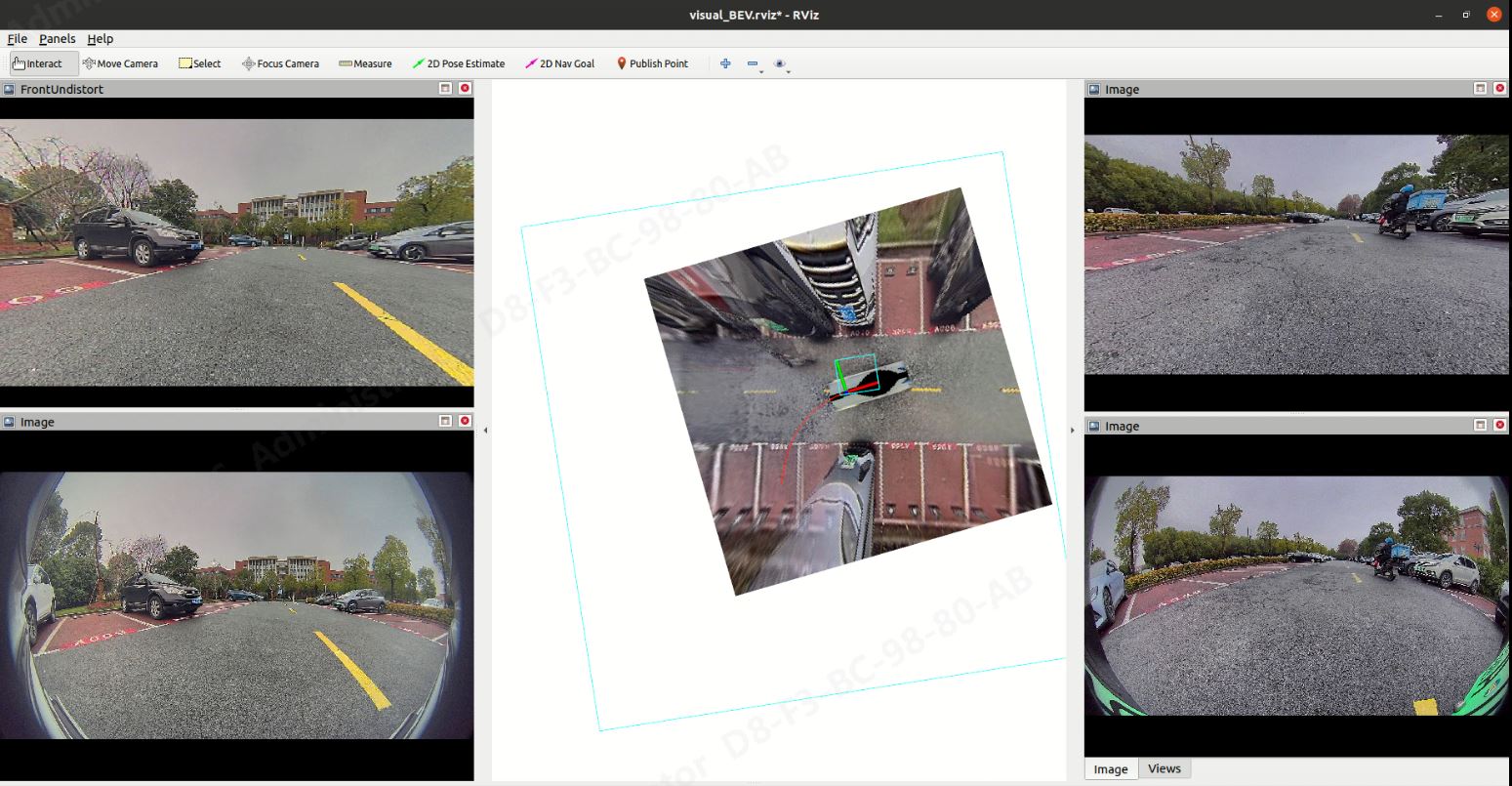
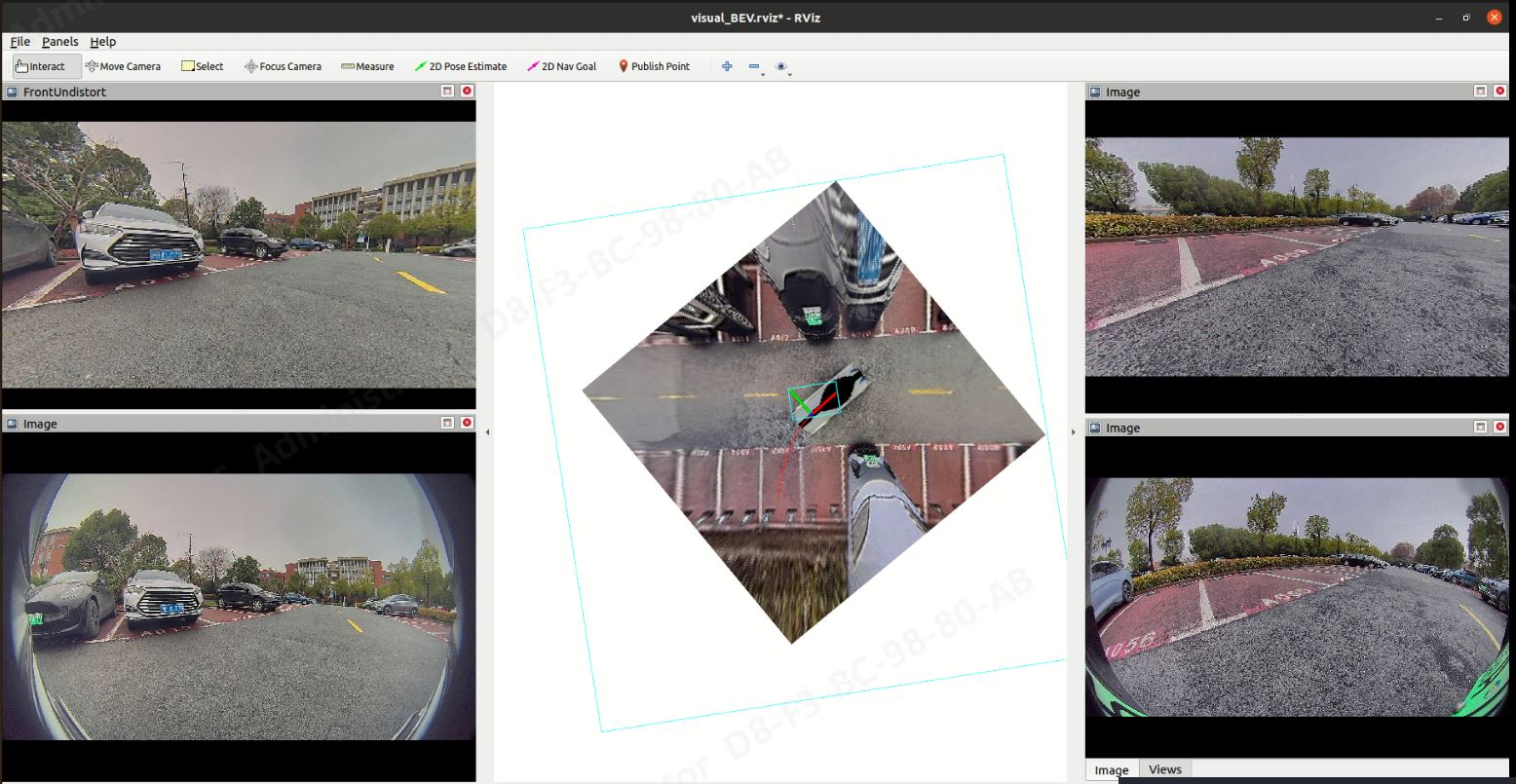
三、实现过程
算法整体架构:
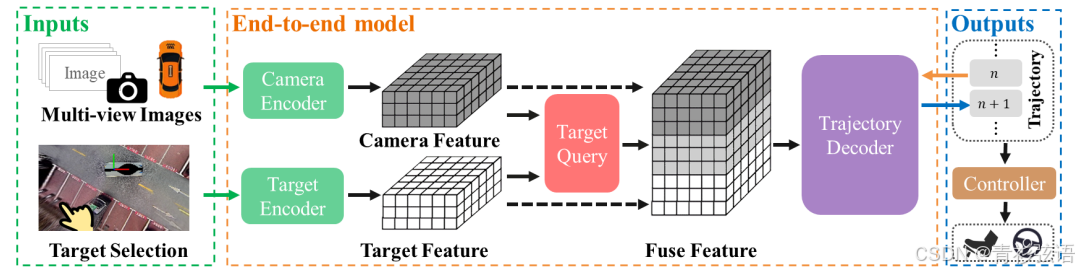
多视角 RGB 图像被处理,图像特征被转换为 BEV(鸟瞰图)表示形式。使用目标停车位生成 BEV 目标特征。我们通过目标查询将目标特征和图像 BEV 特征融合。然后我们使用自回归的 Transformer 解码器逐个获得预测的轨迹点。
训练过程:
注:训练数据集是去完畸变的图像,在数据处理时需要对4路鱼眼相机进行标定,获取相机内外参,对鱼眼图进行去畸变,去完畸变的图像会被制作成训练集
1.获取去完畸变的RGB图像和目标停车位做为输入
去完畸变的RGB图像示例:

目标停车位坐标示例:
使用EfficientNet从RGB图像中提取特征
将预测的深度分布 ddep 与图像特征 Fimg 相乘,以获得具有深度信息的图像特征
将图像特征投影到 BEV 体素网格(特征的大小为200×200,对应实际空间范围x∈[−10m, 10m], y∈[−10m, 10m],分辨率为0.1米)中,生成相机特征 Fcam
BEV视图示例:

使用深度 CNN 神经网络提取目标停车位特征 Ftarget
在BEV空间,将相机特征 Fcam和目标停车位特征 Ftarget 进行融合,获取融合特征 Ffuse
使用 Transformer 解码器以自回归方式预测轨迹点
实现过程图标表示:

推理过程:
1.在RViz界面软件中使用“2D-Nav-Goal”来选择目标停车位
2.获取起始位姿,将以起始点为原点的世界坐标转化为车辆坐标
3.组合数据输入到transformer进行推理,预测轨迹序列
4.将预测的轨迹序列发布到rviz进行可视化

四、评估指标
端到端实车评估:在实车实验中,我们使用以下指标来评估端到端停车性能。
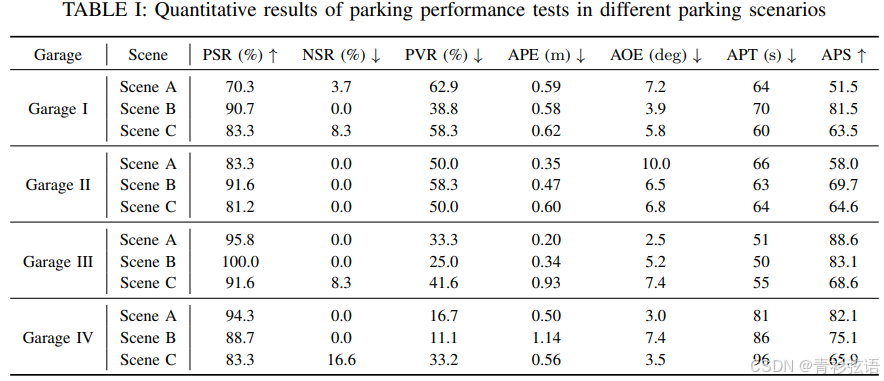
关键词解释:
PSR:停车成功率 NSR:无车位率 PVR: 停车违规率 APE:平均位置误差 AOE:平均方向误差
APS:平均停车得分 APT: 平均停车时间
五、局限性
由于数据规模和场景多样性的限制,我们的方法对移动目标的适应性较差
训练过程需要专家轨迹
与传统的基于规则的停车方法相比仍有差距


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)