
在拍摄一部电影时,我们自己能拍一镜到底吗,或者一个场景呢?几年前,我和我前女朋友在影院里观看了《La La Land》的开场场景--“Another Day of Sun ”这个开场的场景制作非常精良。
长达 6 分钟的开场几乎没有 “剪辑”,是由一个不间断的镜头,场景从一个演员移动到另一个演员,从一辆车移动到另一辆车,并且所有镜头都是在高速公路上拍摄的。而这能顺利实现,是因为剪辑可以实现透视、缩放、变换角度、比例等等.......
深度学习和卷积也是如此。当你使用标准卷积时,你可以获得不间断的特征图流。但这是在 “困难模式 ”下玩游戏。当你学会 “切割 ”后,你可以缩放特定的特征图,旋转它,改变视角,等等......
在深度学习中,这种“切割”是通过空间变换器网络(Spatial Transformer Networks)的算法实现的。
自 2015 年以来,空间变换网络(STN)一直是计算机视觉和感知等领域最实用的算法之一。主要特点是可以直接在特征空间而非输入图像中应用变换,这让我们可以非常方便的轻松 “插入 ”任何网络;从透视变换到点云处理。
在本文中,我们将探讨空间变换网络,了解它们的工作原理和应用领域,并尝试作为工程师可以利用这些知识做些什么。
什么是空间变换网络?
简单地说,空间变换网络相当于电影中的 “剪辑”。与其每次都从同一个角度观察图像或场景,不如应用变换,从而获得这些剪辑。
举个例子?

空间变换网络缩放和调整交通标志
就像放大交通标志一样,“缩放”只是可以进行的众多空间变换之一,还可以改变透视、旋转等。关键在于输入图像,然后输出变换后的图像。
这是在网络中发生的事情,并非总是需要,但在特定情况下可能非常有用。比方说,如果你有一个数字分类器,那么 STN 就可以将交通标志分类为 120。另一个例子是,当你需要对特征地图进行空间转换时,比如将它们转换到鸟瞰空间。
我们将在文章最后讨论这些例子,但现在有一个问题:
空间变换网络是如何工作的?
根据他们的原始论文,这就是 STN:
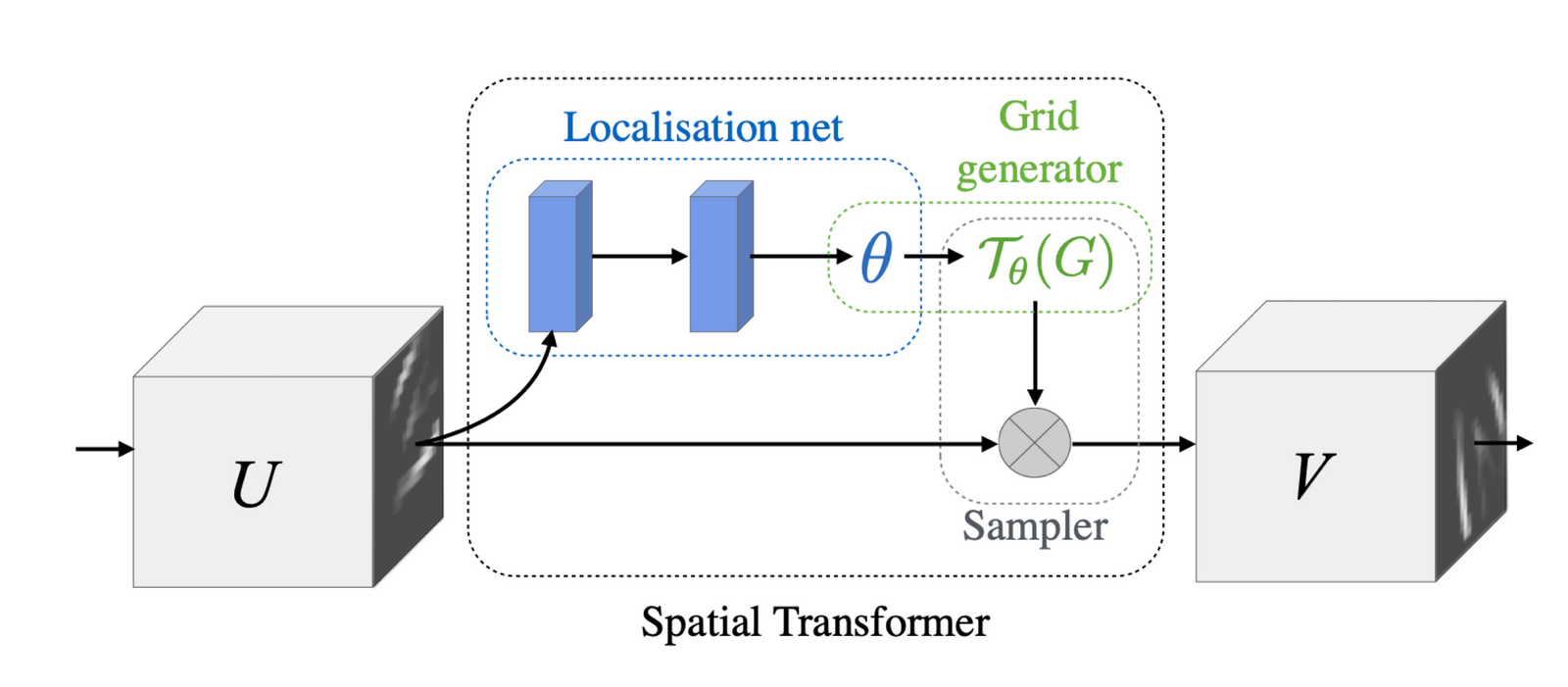
空间变压器网络架构
请注意其中的 5 个关键部分:
U - 输入
定位网
网格生成器
采样器
V - 输出
首先,请注意这里的 U 和 V 都是特征图。这意味着通常不会在图像上应用空间变换器,而是在特征图上应用空间变换器。输出也是一样,都是特征图!
定位网
定位网络是一个回归 Theta θ 值的神经网络。 不要试图搜索非常复杂的架构,它可能只是两个完全连接的层,试图预测一个数字 Theta。θ就像是我们接下来要使用的 “旋转 ”参数。在代码中,它可以像这样简单:
这样一个简单的东西最后却能预测出 6 个值(3*2),那么 Theta 是由什么组成的?这就是二维仿射变换的 6 个参数,这些参数控制着缩放、旋转、平移以及沿 x 和 y 方向的剪切:
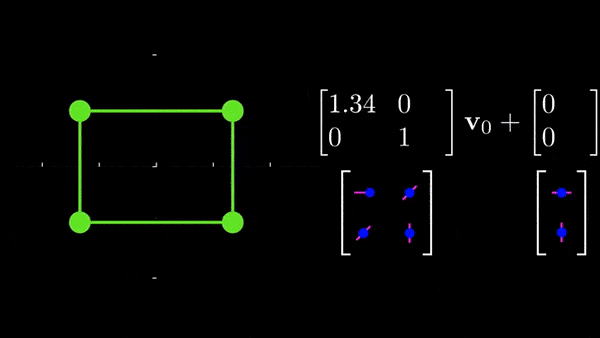
仿射变换的 6 个参数
现在我们有了一个网络,它可以 “学习 ”如何将特征图从一个平面修改到另一个平面......然后我们需要应用转换--这就是网格和采样器。
网格生成器
网格生成器是一个函数,用于创建一个网格,使用 Theta 矩阵将输入特征图中的像素重新映射到输出中的像素。
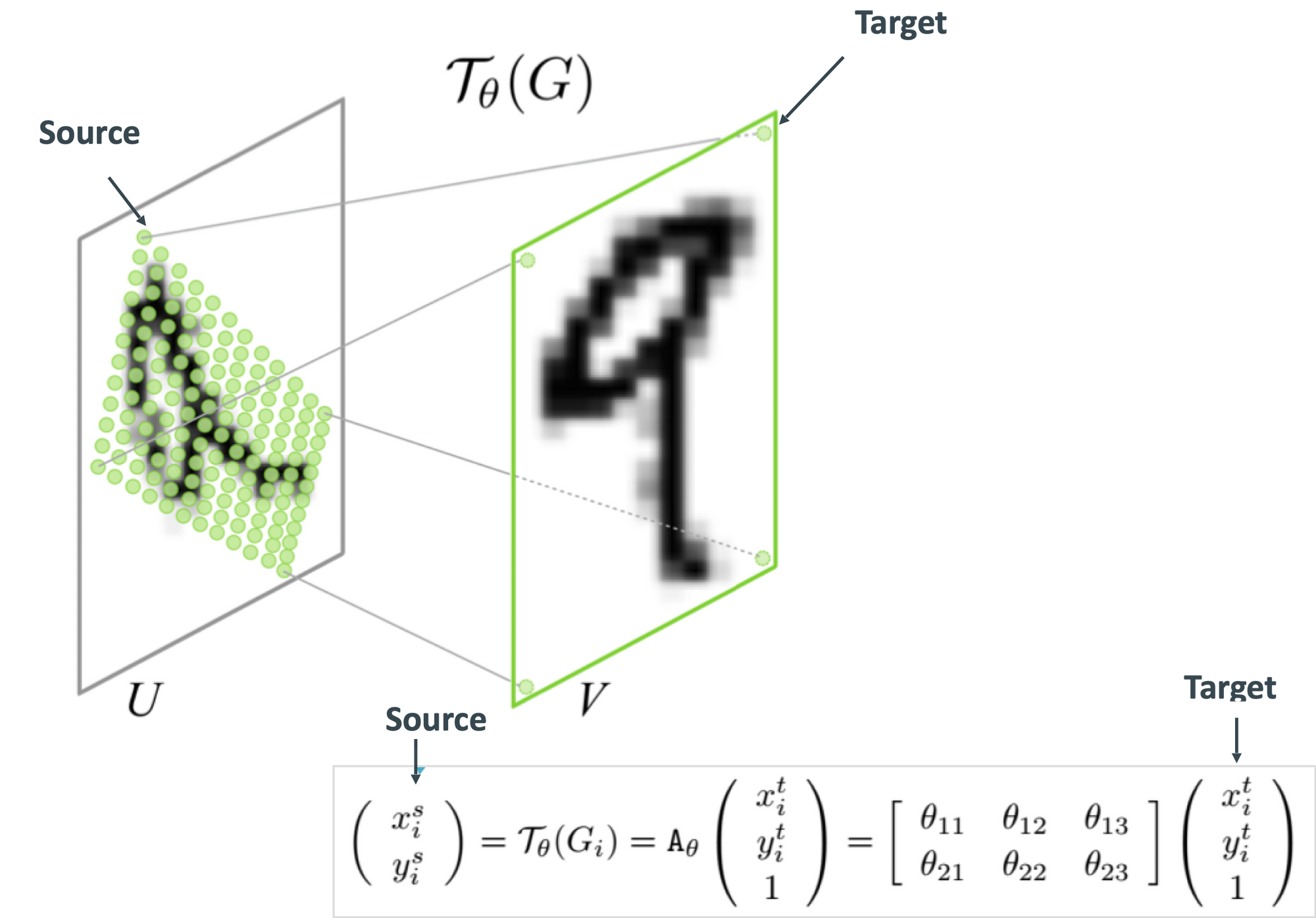
网格的工作原理(根据源文件修改)
现在我们已经知道了目标和 theta 矩阵,因此我们基本上是构建了一个空白图像(称为采样网格),然后尝试找到源像素并将其粘贴到空白图像中(是逆向工作的)。
最后:
采样器
采样器是我们用来转换的工具。如果我们没弄错的话:
定位网计算所需的平移、旋转等...
网格生成器计算每个像素的源像素和目标像素
因此,采样器将同时接收输入的特征图和采样网格,并使用双线性插值等方法输出变换后的特征图。
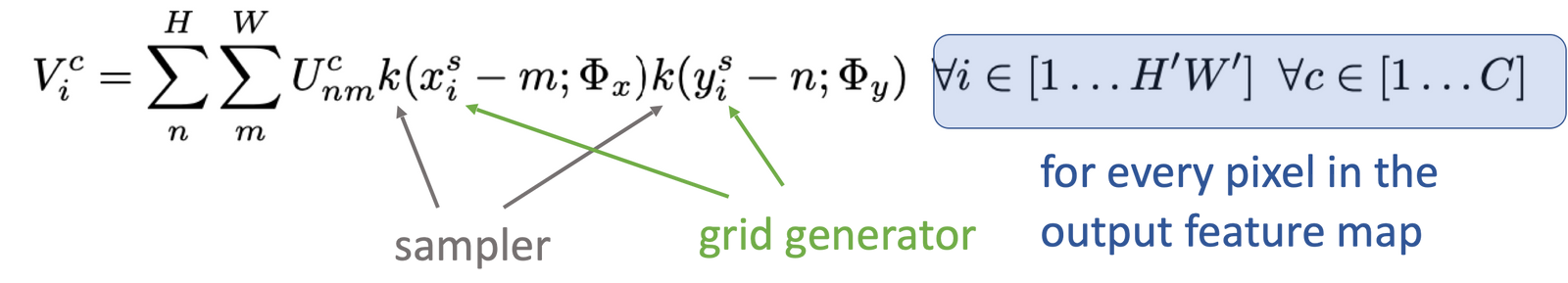
检索 “V ”特征图的最终公式
在代码中,这些仿射变换甚至不需要我们手动完成,只需调用 PyTorch 函数,它就会完成。类似这样
现在明白空间变换器的作用了吧,可以看看代码示例:
现在,让我们来看两个例子...
示例 1:鸟瞰网络
有一个项目可以让你学习创建一个空间转换器模块,将特征图转换到鸟瞰空间,就像下面这样:

使用 STN 将特征地图带入鸟瞰空间
现在你应该知道一旦有了鸟瞰图特征图,工作就基本完成了。我们甚至可以使用多个空间变换器模块(每个图像一个),然后将多个鸟瞰图融合到一个完整的 360° 场景中,最终形成像这里这样的多视图鸟瞰感知系统:
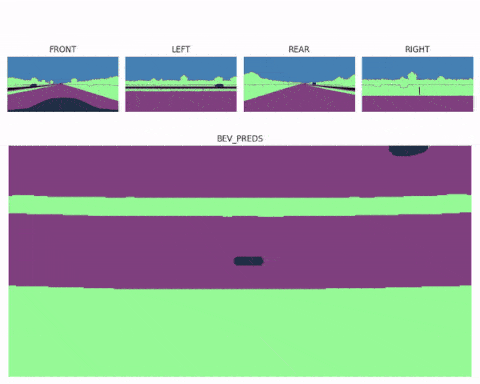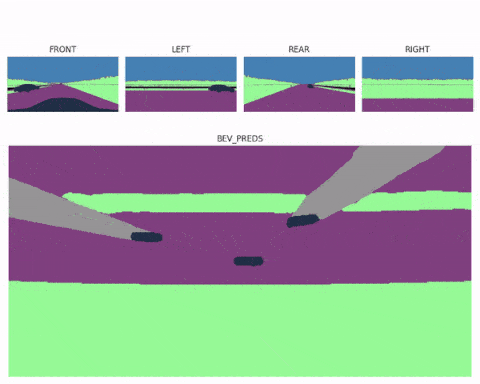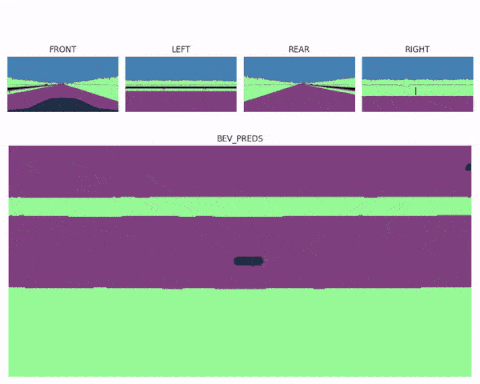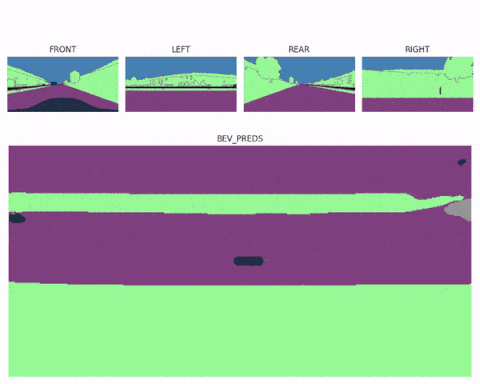
鸟瞰图分割不仅有助于构建精确的上下文地图,而且也是在内部直接执行运动规划的理想格式
接下来,让我们看第二个例子...
示例 2:点云处理
你发现了吗,点云总是从不同的角度显示出来?假设你想使用深度学习对点云进行分类,就像这样:
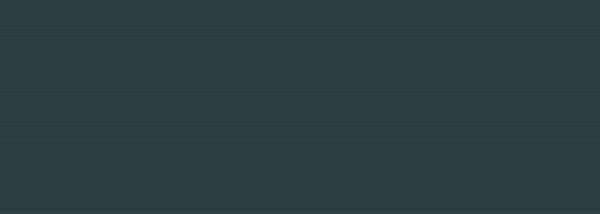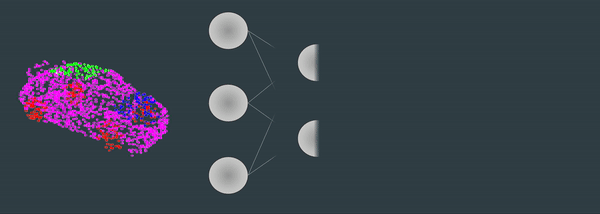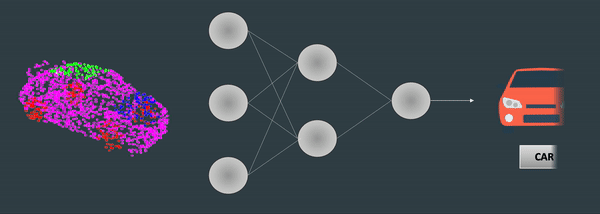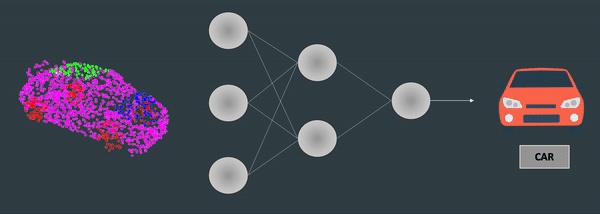
使用 3D 神经网络进行点云分类
如果你的点云是从另一个方向出现的呢,从正面 - 如何处理旋转?在图像中,因为像素有很好的连续性,而且我们有卷积... 但在一系列三维点中,点的顺序是混杂的,无法直接使用卷积。
因此,我们需要使用空间变换网络!在 PointNet 等算法中,空间变换网络通过 1x1 卷积来旋转,正如论文中所说,“将点云对齐到一个标准空间”。这样,在处理点云时,就能始终保持相同的角度,从而使工作变得更轻松。
这种算法(PointNet)在大多数基于点的 3D 深度学习算法中都有使用,因此它无所不在。
但是...
Transformers 不也在这样做吗?
大家可能听说过另一种 Transformers...... Chat-GPT 背后的模式,也是 Vision Transformers 背后的模式--也能这样做吗?
不能。事实上,它们虽然名字相似,但用途不同。
- Transformers : Transformers 源于自然语言处理,旨在处理序列数据,重点是捕捉序列中的依赖关系,而不考虑序列中的距离。它们现在也被用于包括计算机视觉在内的多个领域,但其主要功能是为数据(无论是句子中的单词还是图像中的像素)中的关系建模。
- 空间变换网络(STN): 另一方面,空间变换器网络专门设计用于对数据进行空间变换。允许神经网络学习如何对输入图像进行空间变换,以增强相关特征的提取。这包括缩放、裁剪、旋转或扭曲输入图像等空间操作任务。
因此,它们是不一样的;虽然我们可以训练一个变换器网络来完成这类任务,但如果我们有一个专门为这种特定操作设计的模块,那就没有意义了。
总结
空间变换网络(STN)相当于电影中的 “剪辑”。通过空间变换网络,我们可以始终以自己想要的方式观察场景,每次都能获得理想的视角。
空间变换网络的输入和输出在大多数情况下都是特征图--这说明已经进行了卷积,并处理了现有卷积架构中间的内容。
通过定位网络,我们可以进行旋转、平移、剪切,甚至通过学习仿射变换参数进行缩放。这远远超出了 “切割 ”的范围,θ 值由 6 个参数组成(二维)。
然后,网格生成器会根据 θ 参数计算特征图中每个像素的变换。
最后,采样器将应用变换并生成输出特征图。
我们可以在许多应用中使用 STN,如鸟瞰网络,甚至是利用深度学习处理点云。
空间变换器与变换器不同,用途也不同。STN 专门用于计算特征图从一个平面到另一个平面的变换。
原文链接:https://www.thinkautonomous.ai/blog/spatial-transformer-networks/

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)