
1. 引言
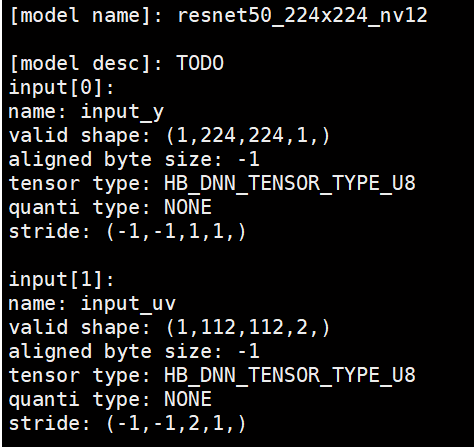
对于初学者,可能会存在一些疑问,比如:
nv12是什么?
明明算法模型是一个输入,为什么看hbm模型,有y和uv两个输入?
为什么uv的valid shape不是 (1,224,224,2) ,而是(1,112,112,2)
stride中为什么有-1?如果需要自己计算,计算公式是什么?
为什么aligned byte size是-1,而不是一个具体的值?如果需要自己计算,计算公式是什么?
相信阅读完本文,可以帮助大家理解上面5个问题,下面来一起看一下。
NV12 属于 YUV 颜色空间中的一种,采用 YUV 4:2:0 的采样方式。主要特点是将亮度(Y)与色度(UV)数据分开存储,地平线使用的NV12,U 和 V 色度分量交替存储。
在深入理解 NV12 之前,我们首先需要对 YUV 颜色空间有基本的了解,YUV理论介绍参考地平线社区文章:常见图像格式 中的部分章节。
2. YUV
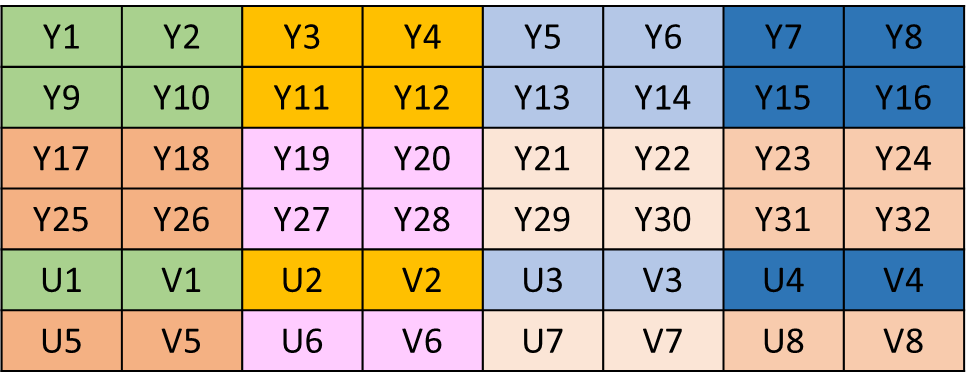
YUV是一种彩色图像格式,其中Y表示亮度(Luminance),用于指定一个像素的亮度(可以理解为是黑白程度),U和V表示色度(Chrominance或Chroma),用于指定像素的颜色,每个数值都采用UINT8表示,如下图所示。YUV格式采用亮度-色度分离的方式,也就是说只有U、V参与颜色的表示,这一点与RGB是不同的。
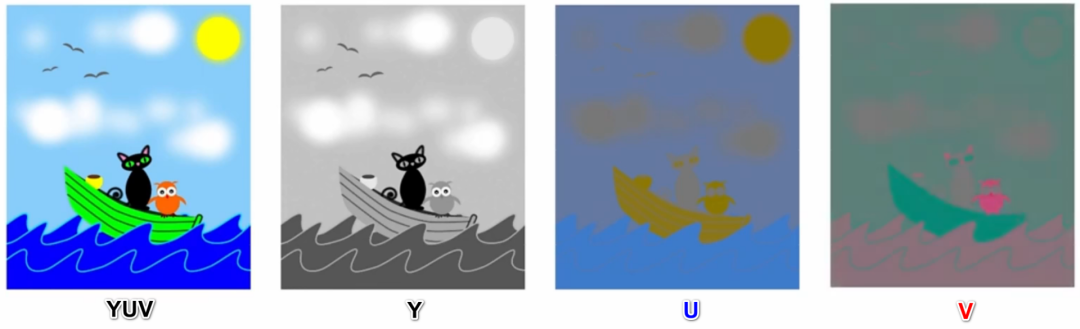
不难发现,即使没有 U、V 分量,仅凭 Y 分量我们也能 “识别” 出一幅图像的基本内容,只不过此时呈现的是一张黑白图像。而 U、V 分量为这些基本内容赋予了色彩,黑白图像演变为了彩色图像。这意味着,我们可以在保留 Y 分量信息的情况下,尽可能地减少 U、V 两个分量的采样,以实现最大限度地减少数据量,这对于视频数据的存储和传输是有极大裨益的。这也是为什么,YUV 相比于 RGB 更适合视频处理领域。
2.1 YUV常见格式
用三个图来直观地表示不同采集方式下Y和UV的占比。
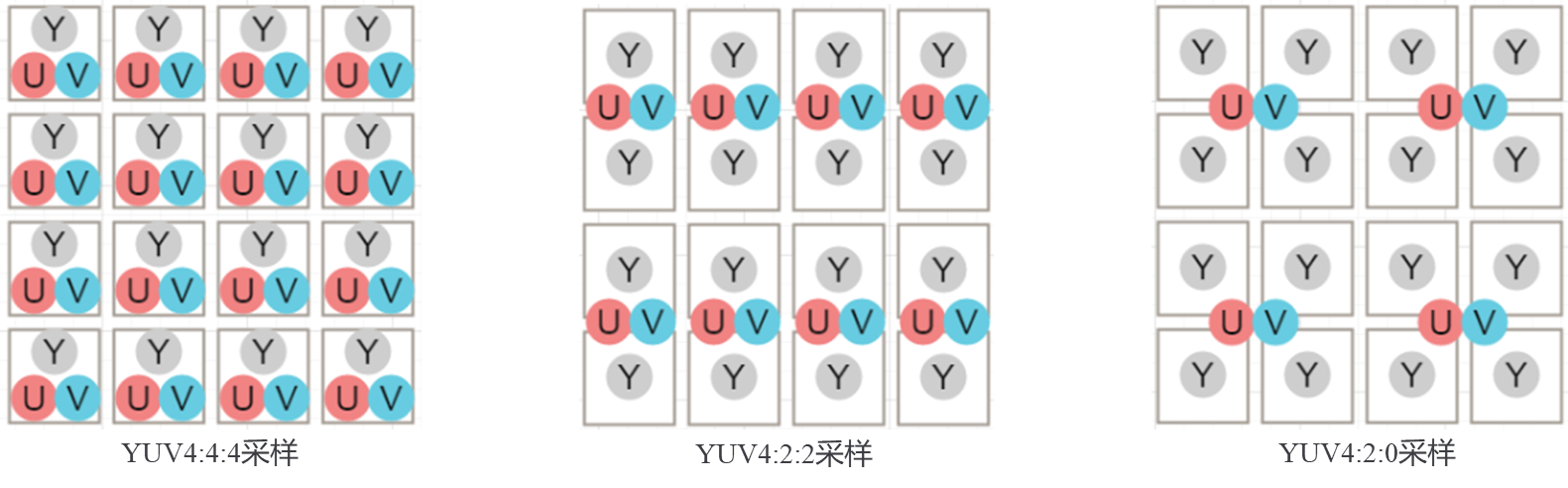
YUV422:每两个 Y 分量共用一对 UV 分量,每像素占用 2 字节(Y + 0.5U + 0.5V = 8 + 4 + 4 = 16bits);
YUV420:每四个 Y 分量共用一对 UV 分量,每像素占用 1.5 字节(Y + 0.25U + 0.25V = 8 + 2 + 2 = 12bits);
此时来理解 YUV4xx 中的4,这个4,实际上表达了最大的共享单位!也就是最多4个Y共享一对UV。
2.2 YUV420详解
YUV420P是先把U存放完,再存放V,排列方式如下图:
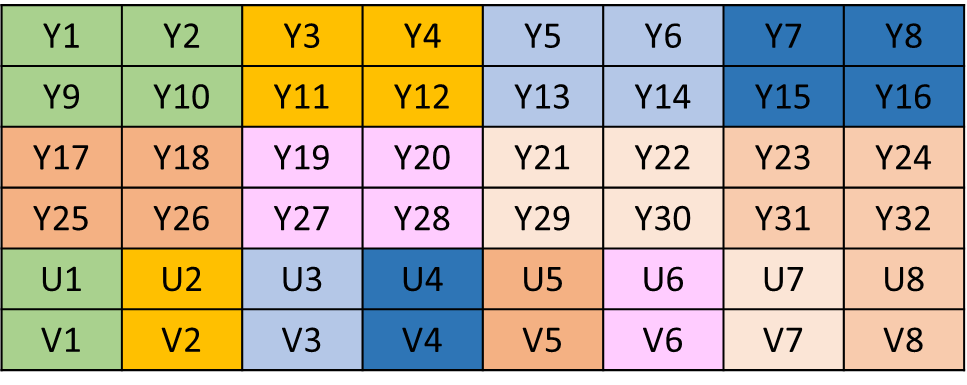
YUV420SP是UV、UV交替存放的,排列方式如下图:
此时 ,相信大家就可以理解 YUV420 数据在内存中的长度应该是:width * height * 3 / 2 。
3. NV12代码示例
地平线使用的 NV12图像格式属于YUV颜色空间中的YUV420SP格式,每四个Y分量共用一组U分量和V分量,Y连续存放,U与V交叉存放,下面介绍两种常见库将图像转为nv12的代码。
3.1 PIL将图像转为nv12
3.2 cv2将图像转为nv12
阅读到这儿,相信前3个疑问,已经介绍清楚了,下面再来看剩下 2 个问题。
4. 对齐规则
有效数据排布和对齐数据排布用validShape 和 stride 表示。
validShape 是有效数据的shape。
stride 表示 validShape 各维度的步长,描述跨越张量各个维度所需要经过的字节数。当数据类型为NV12(Y、UV)时比较特殊,只要求W方向32对齐。
BPU对模型输入输出内存首地址有对齐限制,要求输入与输出内存的首地址 32 对齐。
使用 hbUCPMalloc 与 hbUCPMallocCached 接口申请的内存首地址默认 32 对齐。
当用户申请一块内存,并使用偏移地址作为模型的输入或输出时,请检查偏移后的首地址是否 32 对齐。
完了,没看懂,什么有效数据?步长?W方向32对齐?首地址32对齐?没看懂?举个例子:

相信到这儿,你懂了。
5. 动态输入-1介绍
当模型输入张量属性 stride 中含有 -1 时,代表该模型的输入是动态的,需要根据实际输入对动态维度进行填写。此时需要大家想起来:
W方向保证32对齐。
stride[idx] >= stride[idx+1] ∗ validShape.dimensionSize[idx+1],其中 idx 代表当前维度。
举个例子,如文章最上方的截图:
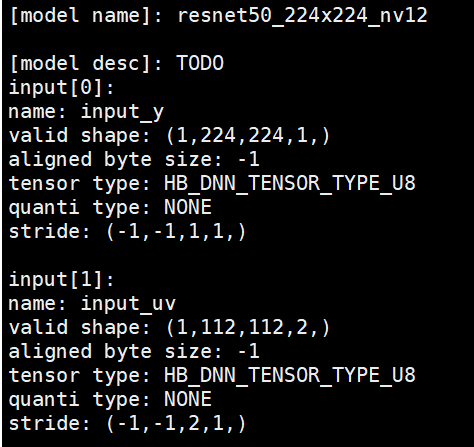
input_y : validShape = [1,224,224,1],stride = [-1,-1,1,1]
input_uv : validShape = [1,112,112,2],stride = [-1,-1,2,1]
stride 计算如下所示,保证动态维度32对齐,其中 ALIGN_32 代表32字节对齐:
input_y :
stride[3] = 1,结合tensor type看,每个元素 8bit也就是 1byte 大小;
stride[2] = 1;
stride[1] = ALIGN_32(stride[2] * validShape.dimensionSize[2]) = ALIGN_32(1 * 224) = 224;
stride[0] = ALIGN_32(stride[1] * validShape.dimensionSize[1]) = ALIGN_32(224 * 224) = 50176;
input_uv :
stride[3] = 1,结合tensor type看,每个元素 8bit也就是 1byte 大小;
stride[2] = 2;
stride[1] = ALIGN_32(stride[2] * validShape.dimensionSize[2]) = ALIGN_32(2 * 112) = 224;
stride[0] = ALIGN_32(stride[1] * validShape.dimensionSize[1]) = ALIGN_32(224 * 112) = 25088;
在准备输入时,就需要按照上面的stride和validshape准备数据了。
但此时,无法解释为什么nv12输入时,这里的stride为什么必须是-1,毕竟可以通过公式计算得到啊,为什么工具不计算好直接提供出来呢?别问,问就是还没理解透彻,这是甲鱼的臀部——“规定”。
看到这儿,第4个问题也解决了。
6. aligned byte size 如何计算
在别的输入格式时,可能会遇到alignedByteSize > stride[0] 的情况,这就是另外的故事了,下次再聊~

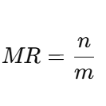
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)