
1. 前言
horizon_j6_open_explorer 发布物的 samples/ucp_tutorial/dnn/basic_samples/ 路径下有很多的示例,本文会使用samples/ucp_tutorial/dnn/basic_samples/code/00_quick_start/resnet_rgb示例,这个示例会运行resnet50_224x224_rgb.hbm分类模型,读取一张jpg图片,进行一次模型推理,在后处理中计算得到Top5的分类结果。
开发者在编写板端部署代码前,需要先熟悉地平线提供的板端部署API,这部分可以查看工具链手册的模型推理API概览,这个章节主要介绍了模型推理相关的API、数据、结构体、排布及对齐规则等,可以在Horizon开发板上利用API完成模型的加载与释放,模型信息的获取,以及模型的推理等操作。建议一边阅读示例代码,一边翻看用户手册进行学习。
2. 程序结构
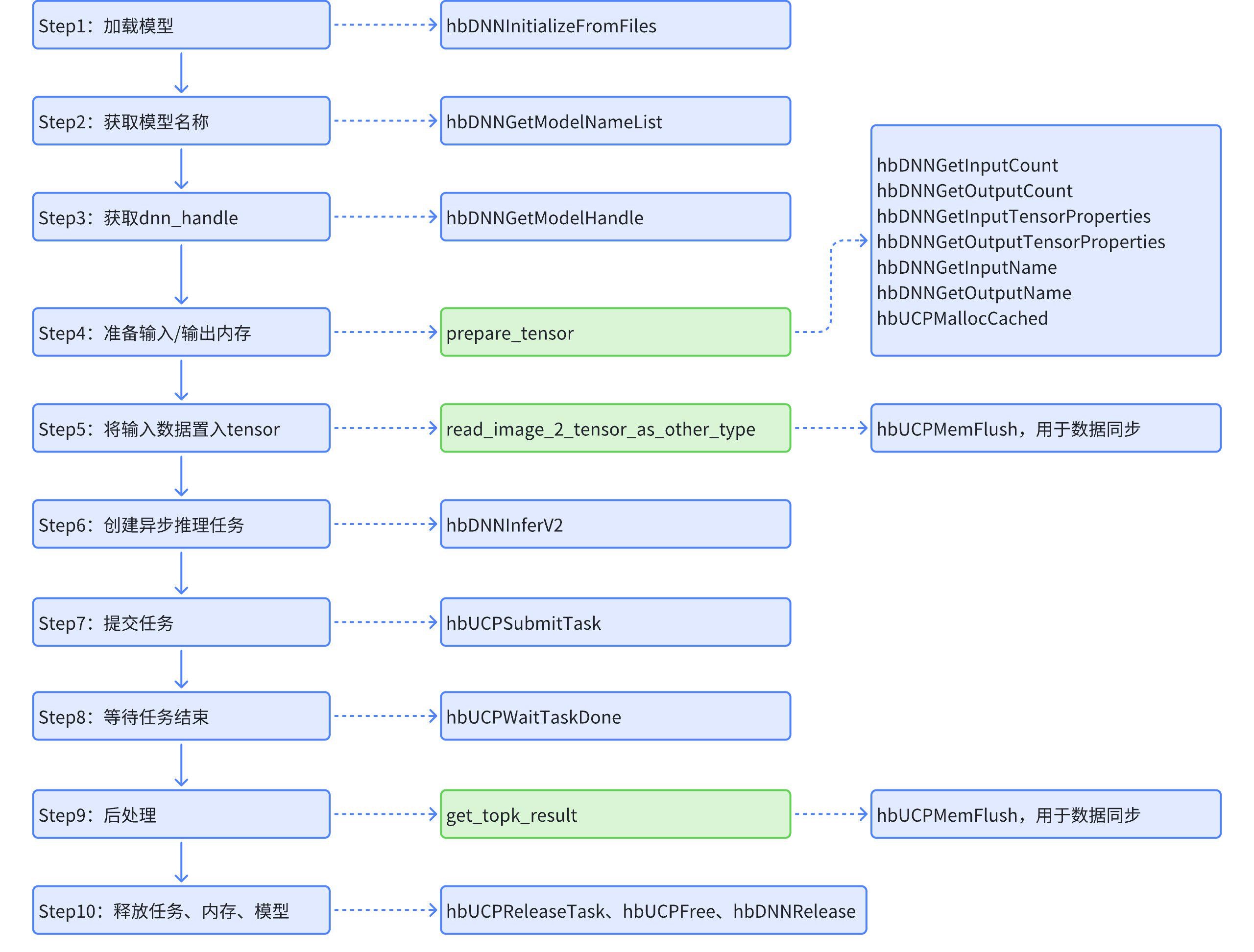
3. 代码解读
samples/ucp_tutorial/dnn/basic_samples/code/00_quick_start/resnet_rgb/src/main.cc
3.1 预定义结构
定义字符串,代表 板端/X86仿真 运行脚本run_resnet_rgb.sh的命令行参数定义,即需要解析的输入参数,包括模型文件路径、图片文件路径,以及分类结果TopK的参数设置,这里的TopK默认是Top5。
定义一些用于日志打印的宏,方便在代码中输出调试信息(Debug)、信息日志(Info)、错误信息(Error)、警告信息(Warning)等,每个日志信息都与一个模块名称关联。通过定义不同级别的日志宏,开发者可以轻松在代码中插入日志,方便调试和排错,同时还可以附带模块名称来区分不同的日志来源。
定义HB_CHECK_SUCCESS(value, errmsg)这个宏,用于判断函数是否成功执行,参数value处填写执行的具体函数,函数返回值为0代表成功执行,执行失败则会返回错误码并在终端打印显示,用户可根据错误码对照工具链手册的《错误码》章节查看报错原因,也可以使用hbDNNGetErrorDesc接口打印错误原因。
#define HB_CHECK_SUCCESS(value, errmsg): 宏定义,value 和 errmsg 是宏的参数,
do-while :保证至少执行一次循环体,与 while 循环(先判断条件)的主要区别在于,do-while先执行,后判断条件。用来保证宏展开时的语法安全性。
auto ret_code = value;: 宏的第一步是执行 value,并将结果赋值给变量 ret_code。
if (ret_code != 0): 在 C/C++ 编程中,通常 0 表示成功,而非零值表示失败或错误。
Classificaton结构体主要定义了三个变量,分别是分类序号id,分类得分score,以及类别名class_name,会在后处理计算TopK的时候使用,友元函数重载的>运算符是为了配合TopK计算中优先级队列的优先级设置,后文分析TopK代码的时候会进行详细介绍。
3.2 解析命令行参数、初始化日志
3.3 获取模型句柄
加载模型相关变量定义
hbDNNPackedHandle_t packed_dnn_handle:hbDNNPackedHandle_t 是一个数据结构,表示打包的模型句柄,packed_dnn_handle 是这个句柄的变量名。用于加载和管理模型的句柄,通过该句柄可以访问和操作多个模型。
hbDNNHandle_t dnn_handle:hbDNNHandle_t 是单个模型的句柄,表示一个具体的模型。
const char **model_name_list:指向字符指针的指针,表示一个字符串数组,用于存储模型的名称列表。通过这个列表可以获取打包模型中的所有模型名称。
auto modelFileName = FLAGS_model_file.c_str();:
使用 auto 自动推导变量类型,modelFileName 是一个 const char*,表示模型文件名。
FLAGS_model_file 是通过命令行参数传入的模型文件的路径,c_str() 将 FLAGS_model_file 转换为 C 风格的字符串(const char*),方便后续调用 C 库函数。
int model_count = 0;表示模型的数量,初始值为 0。在加载打包模型时,可以通过模型计数来进行遍历和操作。
这里涉及到了“pack”打包的概念,做个解释:工具链支持将多个转换后hbm模型整合成一个文件,如果hbDNNInitializeFromFiles接口解析的是没有打包的单个模型,那么packed_dnn_handle指向的就是那一个模型,如果该接口解析的是打包了之后的整合模型,那么packed_dnn_handle会指向打包的多个模型,model_name_list列表会包含所有的模型,model_count为所有模型的总数。
hbDNNInitializeFromFiles:表示从指定的模型文件中加载模型
&packed_dnn_handle: 这是一个指向打包模型句柄的指针,hbDNNInitializeFromFiles 会通过它返回打包模型的句柄。
&modelFileName: 这是一个指向模型文件名的指针,告诉函数要加载哪个模型文件。
1: 模型文件的数量。这里传入的是一个模型文件,因此数量是 1。
hbDNNGetModelNameList: 用于获取已经加载的模型的名称列表和模型的数量。
&model_name_list: 指向模型名称列表的指针,函数通过它返回模型的名称。
&model_count: 指向模型数量的指针,函数会通过它返回模型的数量。
packed_dnn_handle: 之前 hbDNNInitializeFromFiles 函数返回的打包模型句柄,用于标识加载的模型。
hbDNNGetModelHandle: 用于获取特定模型的句柄。
&dnn_handle: 指向模型句柄的指针,函数通过它返回该模型的句柄。
packed_dnn_handle: 这是已经初始化的打包模型的句柄。
model_name_list[0]: 这是从之前获取的模型名称列表中选择的第一个模型名称,用来从打包模型中指定要获取句柄的模型。
3.4 准备输入输出tensor
声明用于存储输入和输出张量的变量,以及用于记录输入和输出数量的计数器
std::vector input_tensors;
这是一个用于存储输入张量的动态数组。
std::vector 是 C++ 的标准容器,可以动态调整大小。它能够存储多个 hbDNNTensor 对象,这里的 hbDNNTensor 是 地平线dnn 库中表示张量(Tensor)的数据结构。
在 DNN 推理过程中,输入张量用于存储输入数据,比如图片或者其他数据形式,供模型处理。
std::vector output_tensors;
同样是一个 std::vector 容器,不过它是用于存储输出张量的。
输出张量用于存储 DNN 推理之后的结果,比如分类的概率、目标检测的框坐标等。
为模型推理准备输入和输出张量。通过hbDNNGetInputCount获取输入输出的数量,通过resize调整张量数组的大小,最终调用函数 prepare_tensor 来进一步准备这些张量。
hbDNNGetInputCount: 用于获取模型的输入张量数量。
&input_count: 一个指向 int 类型的指针,用于存储输入张量的数量。
dnn_handle: 模型的句柄,在前面的步骤中已经获取到了。
hbDNNGetOutputCount: 用于获取模型的输出张量数量。
input_tensors.resize和output_tensors.resize:这两行代码通过 resize 函数调整 input_tensors 和 output_tensors 动态数组的大小,使它们分别能够容纳 input_count 个输入张量和 output_count 个输出张量。
prepare_tensor: 用于进一步准备输入和输出张量。
input_tensors.data(): 获取 input_tensors 中底层数组的指针,传递给函数以便操作。
output_tensors.data(): 获取 output_tensors 中底层数组的指针。
dnn_handle: 模型的句柄,用于根据模型的需求准备张量。
其中,prepare_tensor函数的主要作用有3点:
为输入和输出张量分配所需的内存。
获取每个张量的属性,如内存大小和名称。
初始化张量内存,为后续的推理过程做准备。
hbDNNGetInputTensorProperties和hbDNNGetOutputTensorProperties用于从模型中解析输入输出张量的属性。
input_memSize和output_memSize表示某个输入/输出张量的shape对齐后的字节大小。
prepare_tensor具体代码如下:
首先使用 hbDNNGetInputCount() 和 hbDNNGetOutputCount() 来获取模型的输入和输出张量的数量,这两步在前面已经介绍过,是重复的,一般已经提前知道输入输出张量的数量。
接下来,代码遍历每个输入张量,通过 hbDNNGetInputTensorProperties() 获取每个输入张量的属性,包括 alignedByteSize,即为该张量所需的内存大小。然后通过 hbUCPMallocCached() 为每个输入张量分配内存。
输出张量的处理过程与输入类似,首先使用 hbDNNGetOutputTensorProperties() 获取每个输出张量的属性,并分配内存。
3.5 将输入数据置入输入tensor
将rgb图像数据存放到输入张量对应的内存空间中
调用函数 read_image_2_tensor_as_rgb,从指定的图片文件(FLAGS_image_file)中读取图像数据,并将其以 RGB 格式存储到输入张量(input_tensors[0])中。输入张量 input_tensors.data()是指向 input_tensors 容器的指针,指向模型的第一个输入张量 input_tensors[0],对于多输入模型,除了 input_tensors[0],还需要根据模型的其他输入属性,分别读取和设置其他输入数据
read_image_2_tensor_as_rgb是将一张图片读取并转换为适合推理的 RGB 图像张量,同时为模型输入数据做好预处理,包括调整图像大小、格式转换、填充等。
add_padding,主要功能是给输入张量添加填充(padding)。它通过递归的方式,在每个维度上计算填充后的张量,并将数据从输入内存复制到输出内存。
add_padding_core参数:
output_ptr:填充后的输出数据指针。
input_ptr:原始输入数据指针。
dim_num:剩余的维度数量。
dim:当前维度数组。
stride:步长,用来计算输出数据的对齐方式。
element_size:每个元素的字节大小。
add_padding_core递归处理:
当 dim_num == 1 时,意味着已经到达最低维度(最小元素),这时直接通过 memcpy 复制数据。
否则,循环遍历该维度的每个元素,递归调用 add_padding_core 处理下一维度的数据。
add_padding_core函数会根据给定的 stride 值,将数据进行正确的对齐和填充。
add_padding参数:
output:输出数据指针,指向填充后的张量。
input:输入数据指针,指向原始张量。
dim_num:维度数量。
dim:维度数组,表示输入张量的大小。
stride:步长数组,用来确定每一维度的内存对齐方式。
element_size:单个元素的字节大小。
3.6 执行推理
hbUCPTaskHandle_t task_handle{nullptr}:创建任务句柄 task_handle,用于管理一次推理任务的生命周期,此为异步执行的创建句柄方式。
hbUCPSchedParam 是调度参数结构体,通过HB_UCP_INITIALIZE_SCHED_PARAM(&ctrl_param)宏定义初始化参数,backend重新给了HB_UCP_BPU_CORE_ANY,ctrl_param.backend = HB_UCP_BPU_CORE_ANY 指定任务可以在任意可用的 BPU(Brain Processing Unit)核上执行。hbUCPSubmitTask 函数提交UCP任务至调度器。最后调用 hbUCPWaitTaskDone 函数,等待任务完成。其中,0表示不设定超时时间,一直等待任务完成。
关于hbDNNInferV2的解读如下:
int32_t hbDNNInferV2(hbUCPTaskHandle_t *taskHandle,
hbDNNTensor *output,
hbDNNTensor const *input,
hbDNNHandle_t dnnHandle);
参数解读:
[out] taskHandle 任务句柄指针。
[in/out] output 推理任务的输出。
[in] input 推理任务的输入。
[in] dnnHandle DNN句柄指针。
关于同步与异步执行,task_handle如何配置,解释如下:
如果 taskHandle 置为 nullptr,则会自动创建同步任务,接口返回即推理完成。
如果 *taskHandle 置为 nullptr,则会自动创建异步任务,接口返回的 taskHandle 可用于后续阻塞或回调。
如果 *taskHandle 非空,并且指向之前已经创建但未提交的任务,则会自动创建新任务并添加进来。最多支持同时存在32个模型任务。
#define HB_UCP_INITIALIZE_SCHED_PARAM(param)
{
(param)->priority = HB_UCP_PRIORITY_LOWEST;
(param)->deviceId = 0;
(param)->customId = 0;
(param)->backend = HB_UCP_CORE_ANY;
}
int32_t hbUCPSubmitTask(hbUCPTaskHandle_t taskHandle, hbUCPSchedParam *schedParam);
提交UCP任务至调度器。
参数解读:
[in] taskHandle 任务句柄指针。
[in] schedParam 任务调度参数。
int32_t hbUCPWaitTaskDone(hbUCPTaskHandle_t taskHandle, int32_t timeout);
参数解读:
[in] taskHandle 任务句柄指针。
[in] timeout 超时配置(单位:毫秒)。
3.7 后处理
对推理的输出进行后处理,具体步骤包括:
刷新输出张量数据缓存:使用 hbUCPMemFlush 将输出张量从内存中刷到 CPU 缓存,以确保数据正确地被 CPU 读取。这个操作特别重要。
- 获取 Top-k 结果:函数 get_topk_result 根据模型的输出数据,从推理结果中提取前 k 个分类结果并存储到 top_k_cls 变量中。
FLAGS_top_k 用来指定提取多少个最高概率的分类结果。 打印 Top-k 结果:通过 LOGI 打印前 k 个分类结果的 id,方便观察推理结果。
std::vector &top_k_cls, int top_k) {
std::priority_queue<Classification, std::vector,
std::greater>
queue;
// The type reinterpret_cast should be determined according to the output type
// For example: HB_DNN_TENSOR_TYPE_F32 is float
// // 将 tensor 数据强制转换为 float 指针
auto data = reinterpret_cast<float *>(tensor->sysMem.virAddr);
auto quanti_type{tensor->properties.quantiType};
// For example model, quantiType is NONE and no dequantize processing is required.
// 检查是否需要反量化
// 如果模型量化类型不是 NONE,可以根据需要实现对应的反量化处理逻辑
if (quanti_type != hbDNNQuantiType::NONE) {
LOGE("quanti_type is not NONE, and the output needs to be dequantized!");
}
// 1000 classification score values
// 模型输出的分类得分数量,这里假设为1000
int tensor_len = 1000;
for (auto i = 0; i < tensor_len; i++) {
float score = data[i];
queue.push(Classification(i, score, ""));
// 保证队列中最多只保存 top_k 个元素
if (queue.size() > top_k) {
queue.pop();
}
}
// 从优先队列中取出结果
while (!queue.empty()) {
top_k_cls.emplace_back(queue.top());
queue.pop();
}
// 倒序排列
std::reverse(top_k_cls.begin(), top_k_cls.end());
}
{
// release task handle
HB_CHECK_SUCCESS(hbUCPReleaseTask(task_handle), "hbUCPReleaseTask failed");
// free input mem
for (int i = 0; i < input_count; i) {
HB_CHECK_SUCCESS(hbUCPFree(&(input_tensors[i].sysMem)),
"hbUCPFree failed");
}
// free output mem
for (int i = 0; i < output_count; i) {
HB_CHECK_SUCCESS(hbUCPFree(&(output_tensors[i].sysMem)),
"hbUCPFree failed");
}
// release model
HB_CHECK_SUCCESS(hbDNNRelease(packed_dnn_handle), "hbDNNRelease failed");
}


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)