
夏洛克 · 福尔摩斯蒙着眼睛坐在椅子上。突然,有人摘下他的兜帽,一个60多岁的男人托马斯爵士正坐在一个宏伟的办公室面对他。
“福尔摩斯先生”那人开始说。“很抱歉这样叫你来。我相信你在哪里、我是谁,是个谜。”他自豪地开始说。
小罗伯特·唐尼饰演的福尔摩斯沉默了一会儿,然后开始说:“至于我在哪里——我在查林十字和霍尔本之间迷失了一会儿。但路过藏红花山的面包店时得救了,因为这是唯一一家在面包上使用某种法国糖霜的面包店。之后,马车左转,然后右转,越过舰队管道——我还需要继续吗?”
在震惊中,他的绑架者听着夏洛克发表了剩下的演讲,直到笑话的结尾:“唯一的谜团是你为什么要费心蒙住我的眼睛”。
夏洛克 · 福尔摩斯在这个场景中最好的技能之一是他的能力——甚至蒙上眼睛也准确理解他在哪里,这是通过计算他开车到一个地方的时间,识别他何时转弯,识别特定的线索,比如面包店的气味。
这正是自动驾驶中视觉里程计的原理,在本文中,我们将讨论机器人如何使用摄像头(视觉=基于摄像头)来识别它们在哪里,以及它们如何在3D场景中移动,我们将看到传统和新的基于深度学习的方法。
本文将讨论3个话题:
视觉里程计:根据您看到的内容估计您的姿势的想法
惯性里程计:根据您的移动方式估计您的姿势的想法
视觉惯性里程计:两者的融合
视觉测距
“视觉测距”意味着…如果夏洛克没有被蒙住眼睛怎么办?如果他在一个未知的地方,没有地图,被绑架到其他地方怎么办?
那么他会用眼睛识别一些关键的地方,他转弯的街道、面包店,一个特定的标志,以及类似的任何东西。在SLAM语言中,这被称为地标。但在计算机视觉中,你不会真正检测到面包店之类的东西。
相反,你将使用视觉特征。视觉特征是一个关键组件,使用特征来估算姿势的原理是这样的:
运行特征检测、跟踪
查找旋转、平移矩阵
运行特征检测和跟踪
我们检测特征(角、边、渐变等纯模式识别),然后逐帧匹配它们。SURF、SIFT、BRISK、AKAZE等算法用于检测和编码,其他算法如Brute Force或FLANN可用于特征匹配。最终得出结果:

从帧到帧的特征匹配
现在我们知道了特征是如何移动的,然后呢?
查找旋转、平移矩阵
从匹配的特征中,我们希望通过旋转和平移矩阵来提取摄像机的运动轨迹。这是一个流行的3D重建概念 —— 运动结构(Sfm),其想法是使用计算机视觉原理,例如基本和基本矩阵;或RANSAC的8点算法来恢复R和T。
什么是 R 和 T?它们是旋转(R)- 一个 3x3 矩阵,和平移(T)- 一个 3x1 向量,需要从第一组特征转换到第二组特征。理论上,8 点算法(8-Point algorithm)等算法使用奇异值分解法(Singular Value Decomposition)从 8 个跟踪特征中找出基本矩阵。在实践中,我们可以使用一些 OpenCV 函数从匹配的特征中恢复位置:
p1=#计算特征
p2=#计算特征
K=#内在矩阵
1)求本质矩阵E
E, asked=cv2.findEssentialMat(p1,p2,K,cv2.RANSAC,0.999,1.0);
2)恢复旋转R和平移T
点,R,t,掩码=cv2. recverPose(E,p1,p2)
这就是视觉测距的原理,我们计算特征,跟踪特征,然后恢复姿势。
惯性测距
另一种轨迹测量法是惯性测量法。
让我们回到夏洛克,想象一下,这次他被蒙住了眼睛,但他在走路,或者说,他很清楚绑架他的那辆车开得有多快。现在,他可以测量自己走过的距离。如果他向前走了 20 步,然后向右转,再走 20 步,他就知道自己在哪里了。
这就是 “惯性 ”测距,因为你通常使用一个或多个惯性测量单元(IMU)来计算。惯性测量单元将使用陀螺仪、磁力计(测量地球磁场值)和加速度计来计算你移动了多少、速度有多快、方向如何。
那什么是视觉惯性测距仪?两者的融合?
在 VIO 中,我们将从视觉特征中获得的信息与从 IMU 中获得的信息进行融合,从而实现精确的状态估计。我们如何做到这一点呢,我们如何通过融合两个输出来估计某物的状态?
“扩展卡尔曼滤波器!"一位读者在后台喊道。
对扩展卡尔曼滤波器!这是我们用来将 IMU 的输出与视觉轨迹测量的输出相结合的主要算法。如何结合?让我们来看看:
视觉惯性测距的过滤技术
这个原理我称之为 “顺序融合”,或顺序传感器融合,因为它是按顺序进行的:
从传感器 A(或算法 A)获取数据,然后运行 “预测”;
从传感器 B(或算法 B)获取数据,然后运行更新。
这就是卡尔曼滤波器的工作原理。我们说 EKF 是解决方案,但它并不是唯一的解决方案。事实上,如今许多算法都使用了另一种基于图-SLAM 的技术:优化。
VIO 的优化技术
第二组是优化技术,在这里,我们要最小化包含所有信息的成本函数。这类似于图形 SLAM 技术,我们试图将所有信息都包含在内,并尽可能降低成本。
举个例子:
想象一下,IMU 说 “我们移动了 2 米”,而摄像头说 “我们移动了 2.5 米”,谁是正确的?在卡尔曼滤波器中,这(几乎)是一个简单的选择。我们将进行预测/更新循环,为每次测量添加 “权重 ”或协方差,然后在中间某个位置得出答案。但如果使用优化技术,就不会这样做。
取而代之的是解决最小平方问题。这通常被称为非线性优化,一般会参考 Levenberg-Marquardt 或 Gauss-Newton 等算法。这种 “优化 ”是为了最小化成本函数。
我们希望满足每个测量值,因此,我们将绘制地图,并试图为每一个可能的地标保留不确定性和假设。
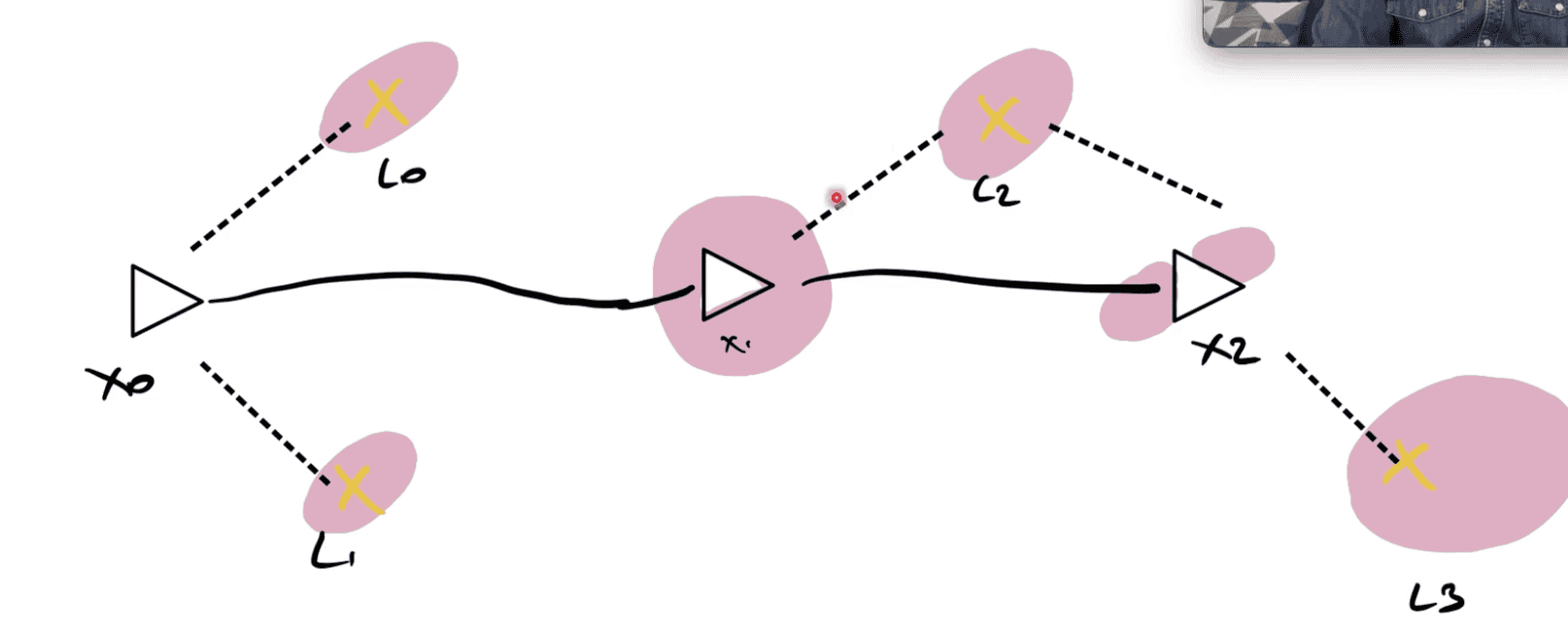
如何找到一个位置来满足所有这些假设?
要点是:我们要使成本函数最小化。
现在我们来看几个例子。
示例 #1:MSCKF(多状态约束卡尔曼滤波器)
这里展示了 MSCKF(多状态约束卡尔曼滤波器)算法背后的过程:
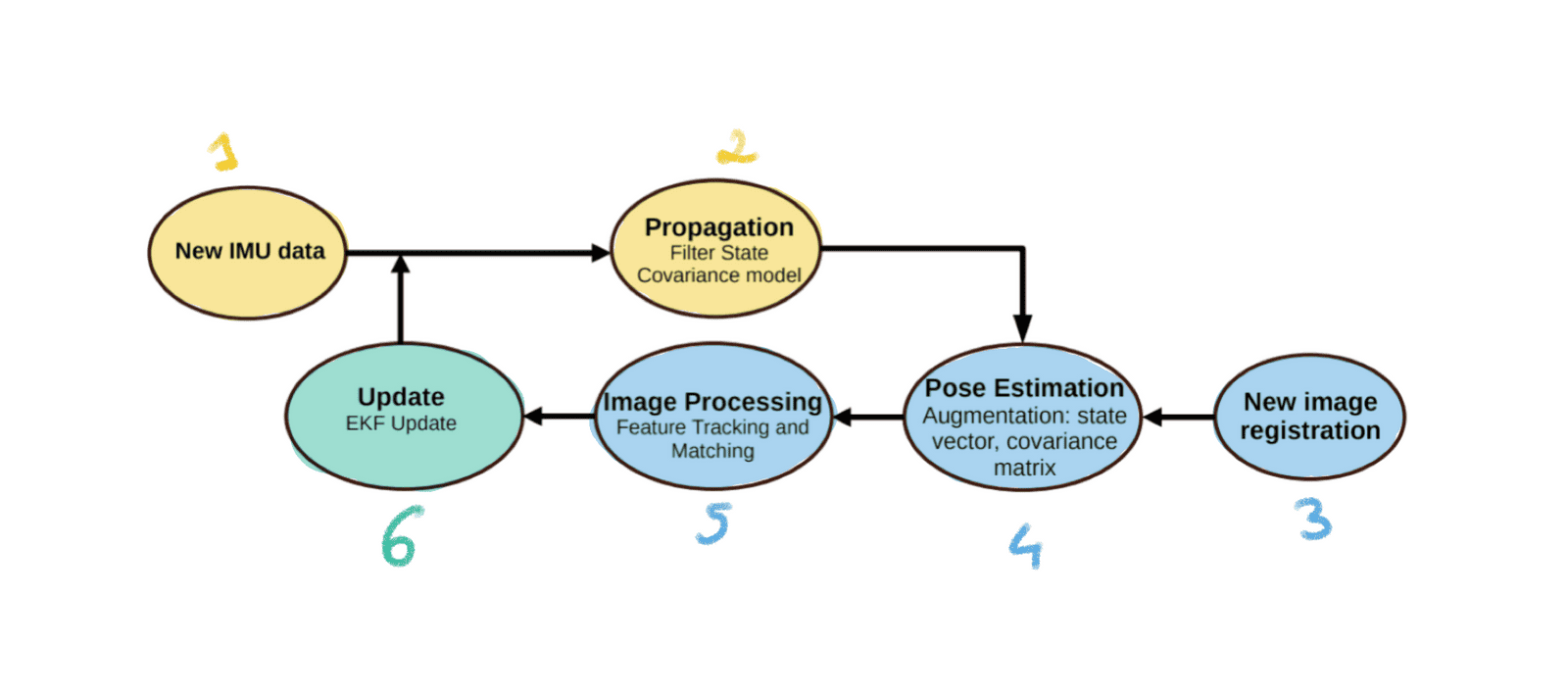
MSCKF 算法图
黄色 = IMU | 蓝色 = 摄像头 | 绿色 = 融合
步骤:
新的 IMU 数据: 总得有个起点,新的惯性测量数据是我们循环的起点。
传播(EKF 预测): 立即运行卡尔曼滤波 “预测 ”步骤。使用新的 IMU 数据,根据 IMU 模型向前传播状态和协方差。
新图像注册: 在 “预测 ”之后,立即添加新图像。
姿势估计增强: 这一步利用从新的相机图像中获得的信息来增强状态向量和协方差矩阵,要为卡尔曼滤波器的 “更新 ”做好准备。
图像处理(特征跟踪和匹配): 从图像中提取特征,进行跟踪和匹配。纯粹的视觉测距。
更新(EKF 更新): 最后,我们根据跟踪到的特征更新状态!滤波器结合视觉信息来修正状态估计并减少不确定性,从而提高姿态估计的准确性。
因为这是卡尔曼滤波器,所以要循环进行。第 7 步是加入新的 IMU 测量值,以此类推......
因此,要想进一步缩短时间,就必须:
惯性航向测量 >>> 预测 >>> 视觉航向测量 >>> 更新 >>> 重复。
示例 #2:VINS-MONO
LinkedIn 上有一篇点赞数超过 300 的帖子,介绍了 VINS-MONO 的视觉轨迹测量算法。这种 VIO 算法(单目视觉惯性系统 = Mono VINS)的原理非常酷:
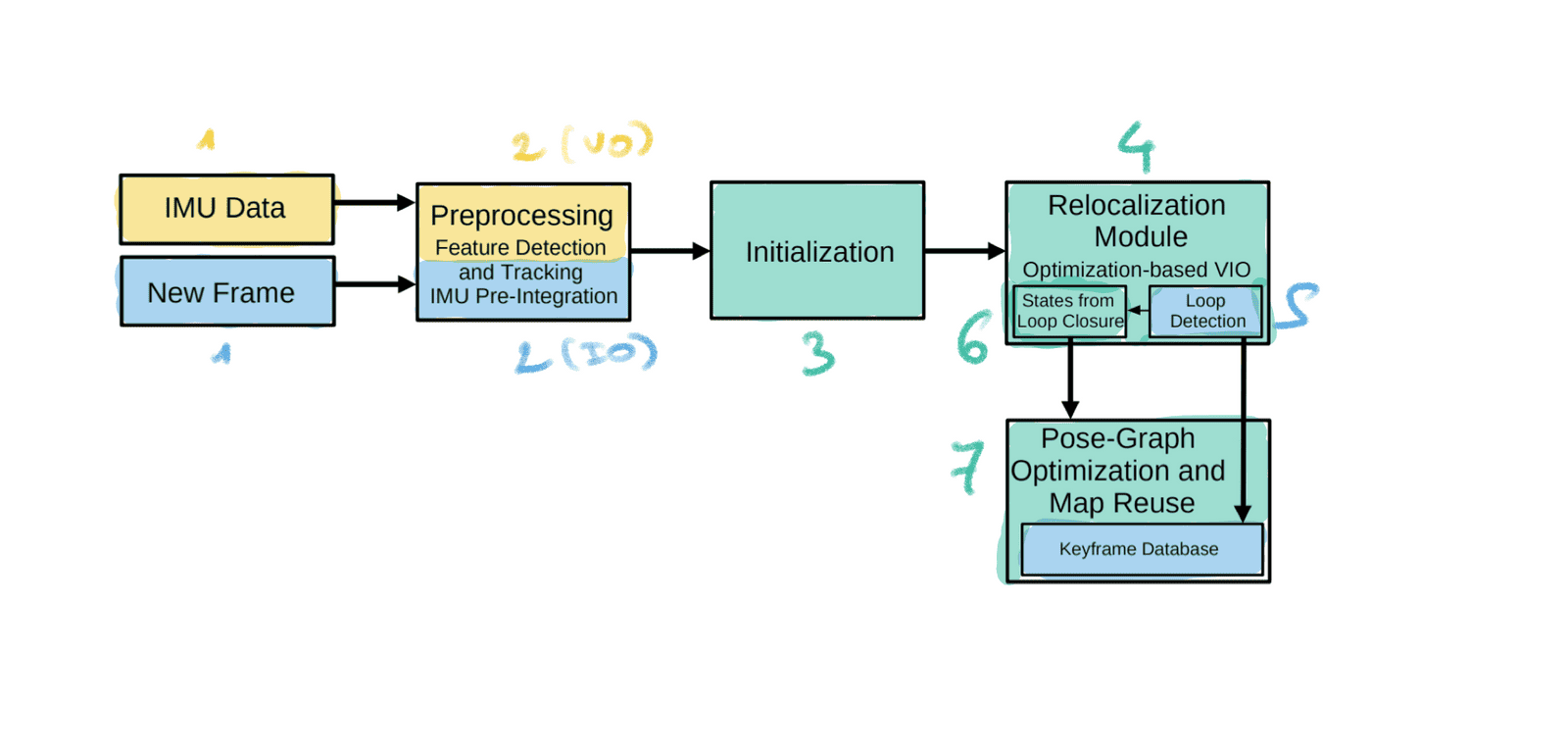
VINS-MONO 算法图
黄色 = IMU | 蓝色 = 摄像头 | 绿色 = 融合
新的 IMU 数据和帧: 并行处理它们。
预处理: 这一步包括视觉测距(用于摄像头)和惯性测距(用于 IMU)。
初始化: 初始化 “图形”,并根据两个测量值将数值放入其中。这一步已经将两个值融合到了共同的地图中。
重新定位: 最后是基于循环闭合检测的 “优化 ”步骤。我不会把这部分称为纯粹的里程测量,它已经包含在 SLAM 的映射部分中了。
姿势图优化: 已经脱离了视觉惯性轨迹测量,实际上是在一个城市中绕几圈后进行全局优化。不过,这一步也会校正位置,所以也算是测距的一部分。
只有这两个吗?
通常是的,或许可以找到一个 “深度学习 ”系列,并探索每个系列的子系列,如 Graph-SLAM,但在任何 SLAM 中,一般会提到这些技术:要么解决优化问题,要么使用卡尔曼滤波器。如果看一下迷你图,就会发现它是这样的:
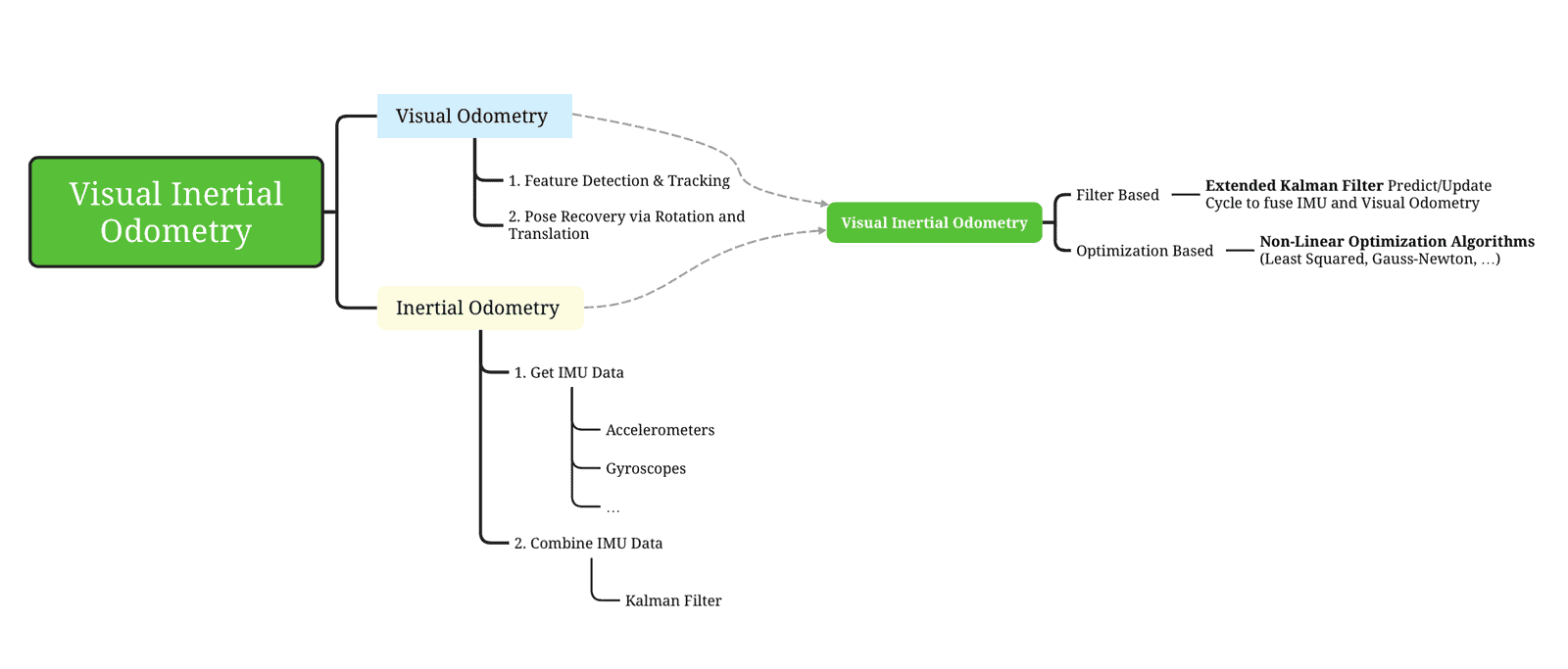
视觉惯性测距图
摘要
视觉惯性轨迹测量是将视觉轨迹测量(来自摄像头)与惯性轨迹测量(来自 IMU:惯性测量单元)相融合的概念。与所有传感器融合算法一样,将二者结合在一起可以产生巨大的优势。
视觉运动轨迹测量通常是通过检测特征,在帧与帧之间进行匹配,然后通过旋转和平移矩阵恢复运动轨迹。
惯性运动轨迹测量是将来自 IMU(陀螺仪、加速度计......)的所有数据进行融合,以获得在一段时间内的运动轨迹。可以恢复三维姿态、加速度、速度、方向等。
要实现 VIO,可以使用基于卡尔曼滤波器的方法。一般会使用扩展卡尔曼滤波器,然后通过精确/更新循环依次融合 IMU 和视觉特征。像 MSCKF 这样的算法就可以做到这一点。
还可以使用非线性优化算法,如 VINS-MONO,通过成本函数最小化来优化对地标的估计和的位置。
结论
视觉惯性轨迹测量(VIO)是 SLAM 领域非常流行的一个想法,因为它是完全没有 GPS 的唯一可行替代方案。如果没有 GPS,就必须使用 IMU 并进行 VIO 处理。在没有激光雷达的情况下,它也是激光雷达测距的理想替代方案。
如今,VIO 系统既可用于自动驾驶汽车、空中机器人(无人机)、户外地面车辆(例如军事应用),也可用于配备 IMU 和一个或多个摄像头的大多数智能机器人。
我们看到的例子中只有一个 IMU 和一个摄像头,但可以使用不同的传感器数据设置。有些算法还可以在立体中工作,从而利用 3D 计算机视觉;还可以使用多个 IMU。
如果要学习 SLAM,可以在学习了 SLAM 和一般的运动轨迹测量后,再开始视觉惯性测距。
原文链接:https://www.thinkautonomous.ai/blog/visual-inertial-odometry/


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)