
我们被困住了。哪种情况下应该使用 go?在工程领域,学术派喜欢默认的技术,让工程师自己审阅论文,然后在一两周后分享他们的结论。我认为这是浪费时间,因为大多数人可能根本没看过,或者在最后一秒匆忙完成。
我们有一个“早期融合”策略,它涉及在我们阅读论文之前就将我们的大脑融合在一起……我们还有一个“晚期融合”策略,它是在我们完成阅读后融合我们的结论。
在这篇文章中,希望我们“放大”早期融合,了解它是什么,“选项”是什么,何时做/不做,并对此有一个很好的理解。
什么是早期融合?
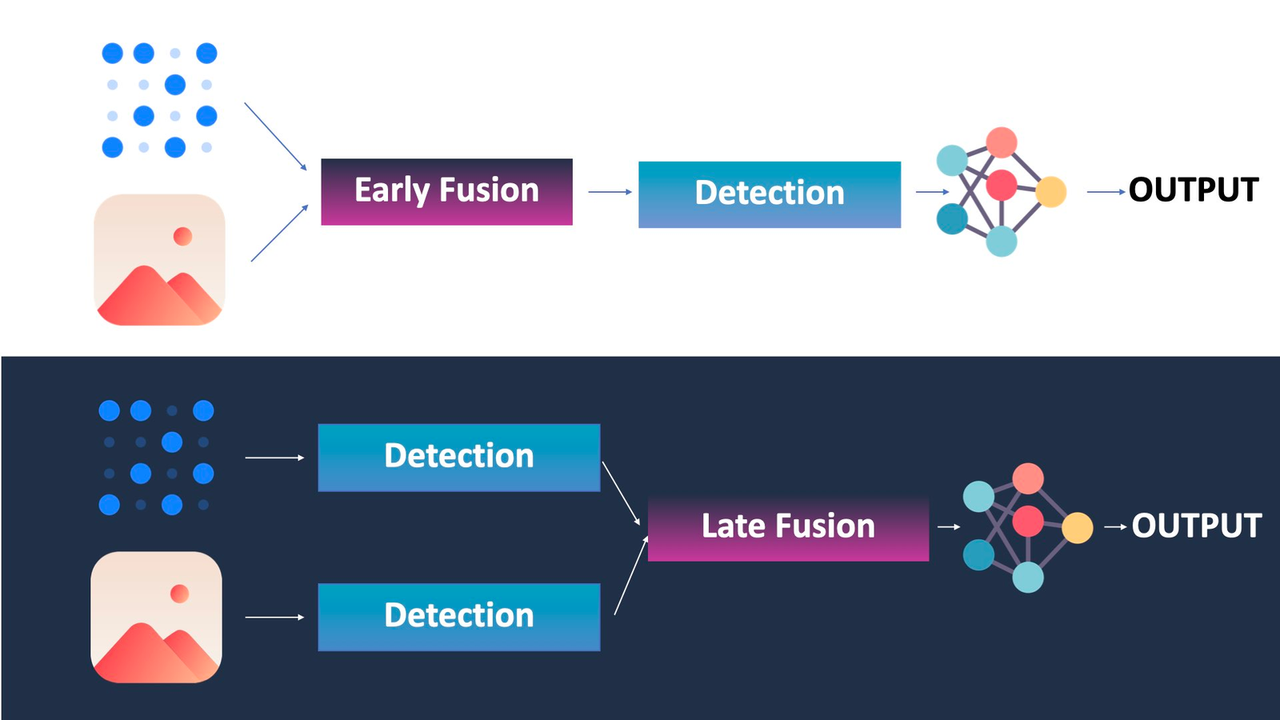
激光雷达和相机的早期与晚期传感器融合
实际上,还有其他类型的融合,比如中间融合,它涉及融合特征(在一些卷积神经网络和提取之后——通常用于图像识别),或者顺序融合,这是卡尔曼滤波器方法,你将考虑激光雷达,然后是相机,然后是激光雷达…
在这篇文章中,我们关注早期融合。
早期融合的两种方法
有两种方法可以进行早期融合:
几何方式
神经网络方式
让我们从传统的方式开始。
几何方式
以激光雷达和相机为例,它们不仅传感器完全不同,而且它们在不同的维度上(相机是 2D 的,激光雷达是 3D 的)。
第一种方法涉及将一个数据投影到另一个数据上。例如,可以在图像上投影点云。或者“可以”在 3D 空间中投影像素。第一种方法更常见,但第二种方法也越来越多,特别是在密集 SLAM 和 3D 重建中。无论如何,它看起来像这样:

几何早期融合是什么样子的
当然,理解如何做到这一点并不“容易”,因为点云是 3D 的,但是像素是 2D 的。然而,如果上过 3D 计算机视觉课,你可能听说过相机标定、内在和外在矩阵、坐标空间,可能看到有一些数学方程允许我们从一个矩阵移动到另一个矩阵。
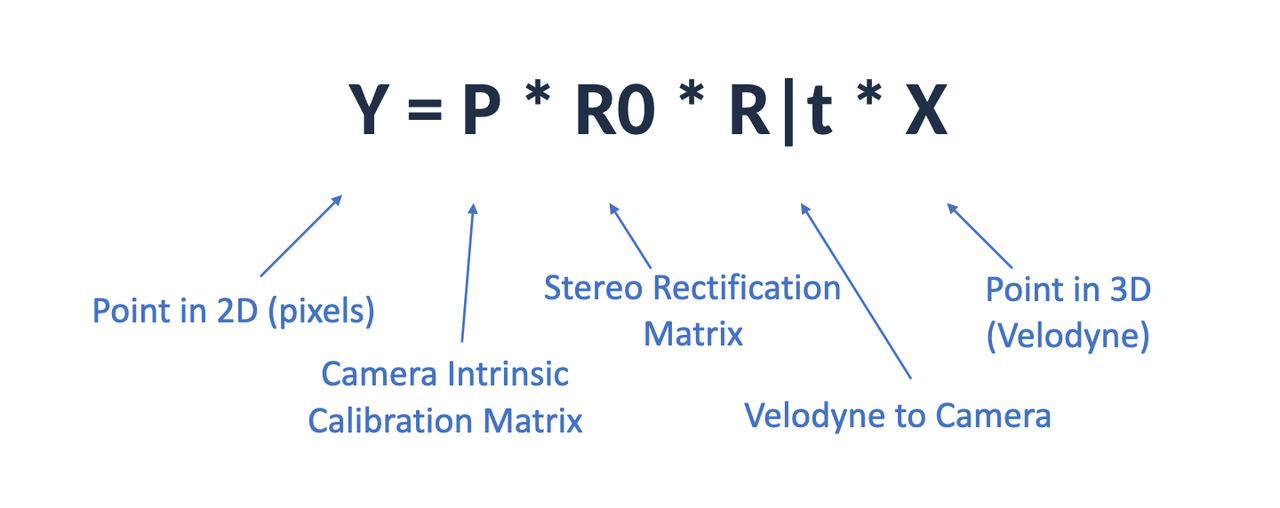
将 3D 点投影到 2D 像素的公式
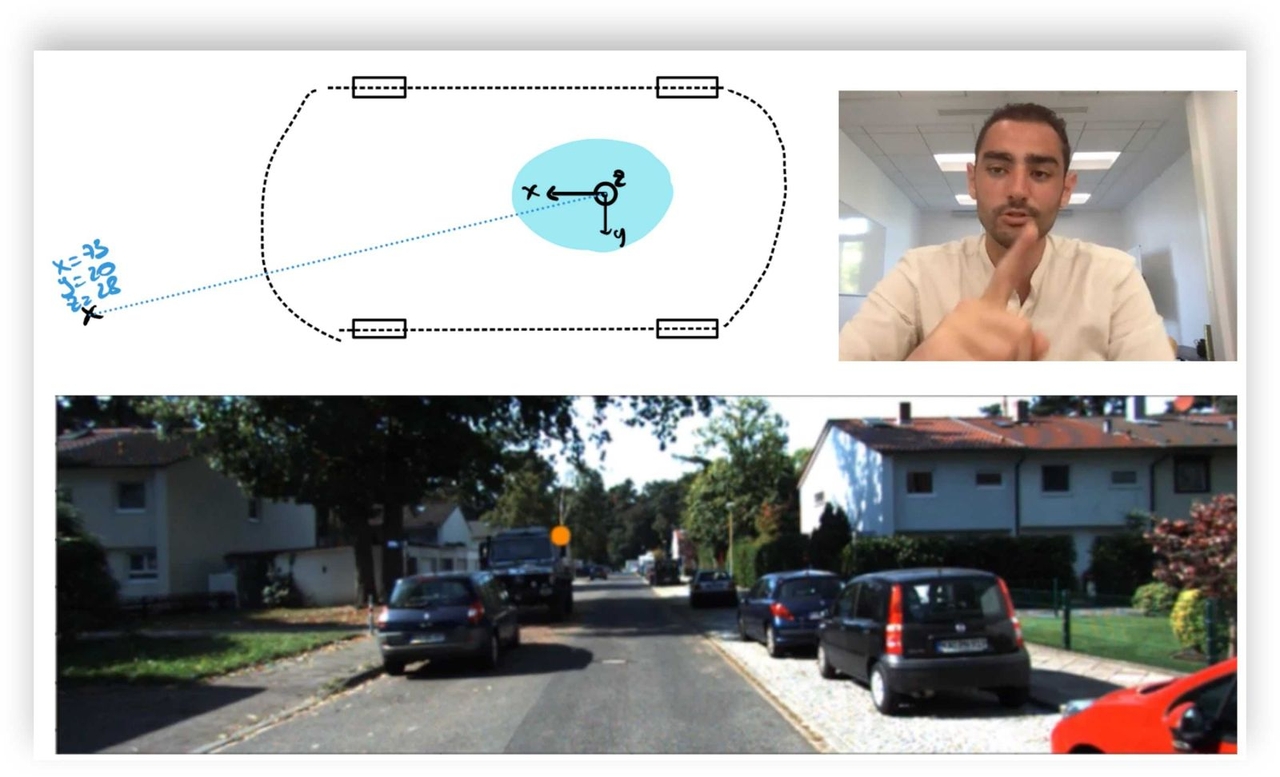
将单个 3D 点投影到图像上——真正“获得”视觉融合所需的理解水平
这里一个非常明显(但值得一提)的注意事项是传感器需要同步。
这不是唯一的方法,因为你也可以将像素投影到 3D 空间。这里指的是像素,但它也可以是视觉特征。在视觉 SLAM 中,我们经常将这些技术称为稀疏和密集 3D 重建,或者直接和间接。
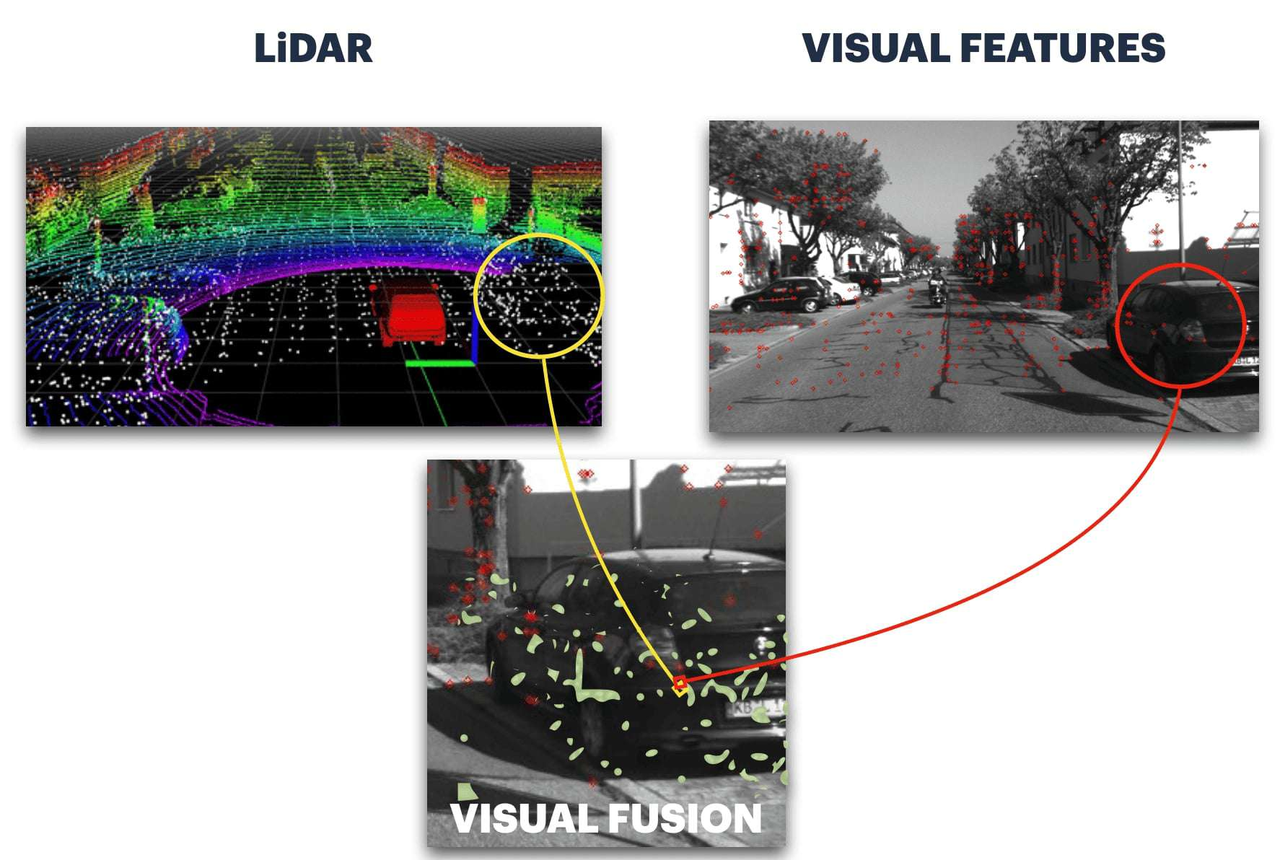
视觉特征融合-我们已经在中间融合,但仍处于几何水平
将像素与点融合并不容易,但将特征与点融合更有意义
想想看,我们可以融合:
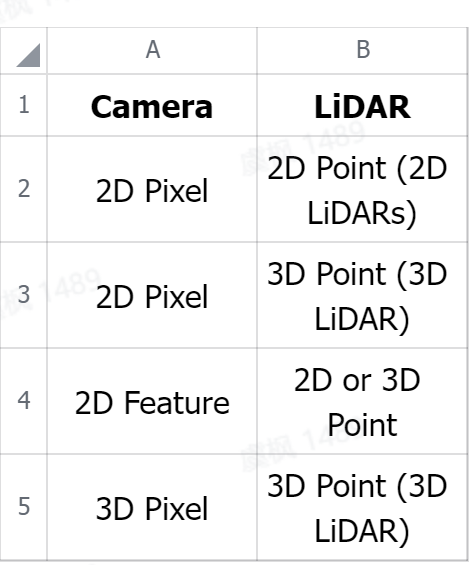
所以这是所有几何方式,没有任何机器学习。可以看到使用这些,已经可以实施复杂的早期融合策略。这里还谈到了激光雷达和相机,但也可以融合雷达和相机、可以融合 IMU 和 GPS、可以早期融合多种模式。
现在让我们看看如何使用神经网络。
早期融合机器学习
当使用深度学习时,我们增加了一层复杂性…在融合什么?特征?经过多少层?第一层?3 层?10 层?这重要吗?2D 与 3D 问题呢?还在将一个投影到另一个吗?
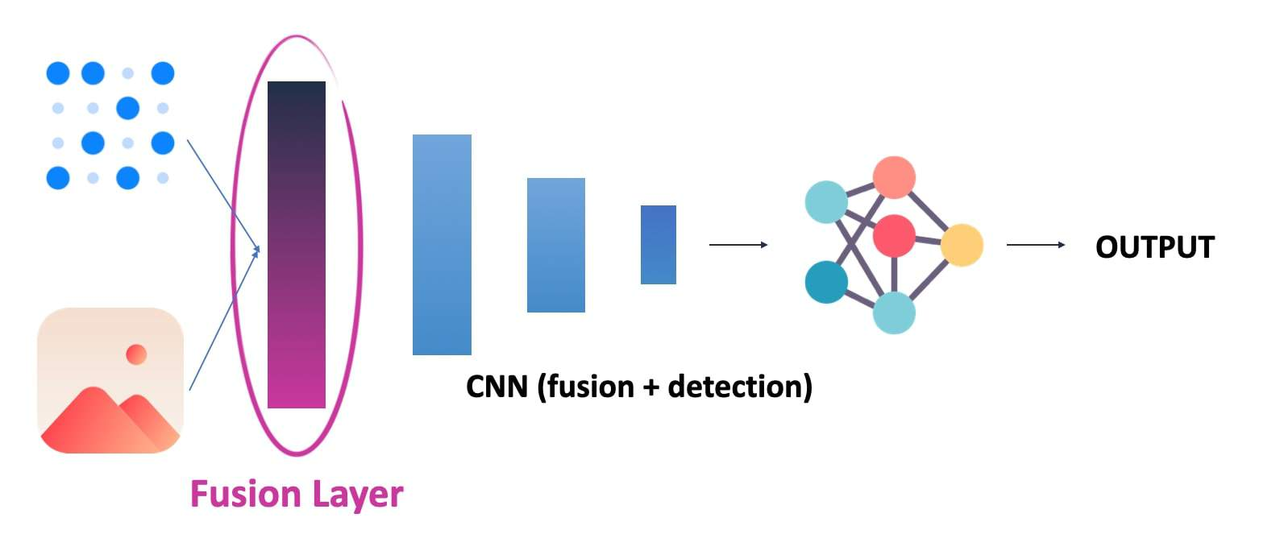
深度早期融合
注意这里如何融合来自第 1 层的原始数据,这是一个“真正”的早期融合。
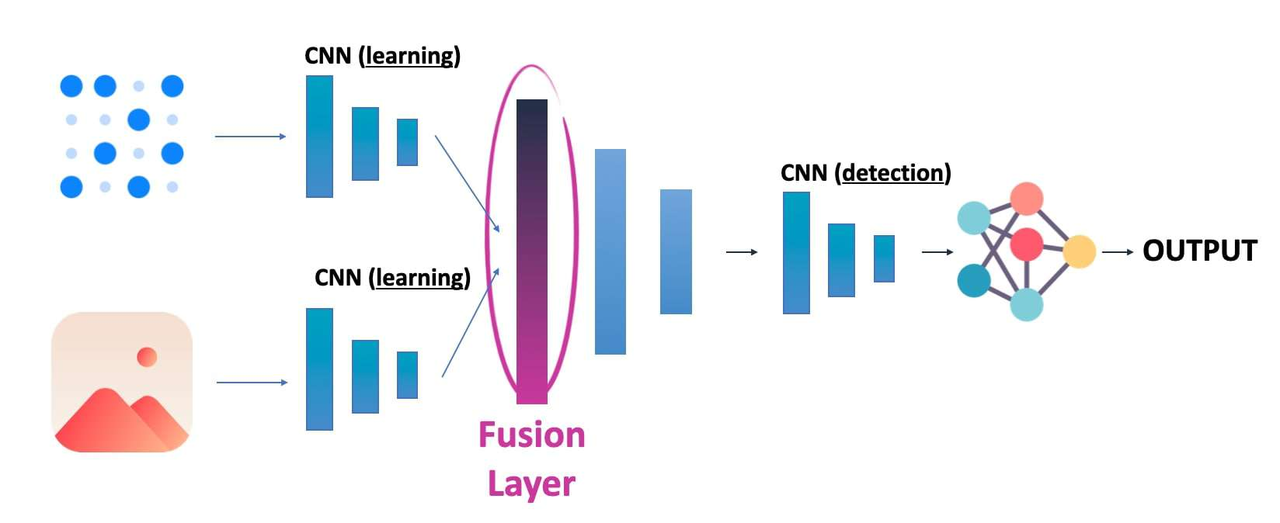
深度中融合-它只发生在特征级别
但这将不再是“早期”融合,更应该称之为“中期”或“中期融合”。它与之前的“特征融合”想法非常相似,这是因为我们可以使用传统或学习深度技术进行“直接”融合或“特征”融合。
现在是实际融合的问题。如果你混合鸡蛋和巧克力会发生什么?它不起作用。你需要先混合鸡蛋,让巧克力融化,然后做蛋糕。融合是相同的想法,我们不会“学习”,但我们仍然会处理事情。

范围视图融合(在这种情况下是中期,但可以提前完成)
所以这是另一种方式;不是实际的融合代码,将在连接或添加层中;这是因为我们希望将 2D 范围视图与 2D 图像或类似的东西融合在一起,可以添加或连接。
鸟瞰融合
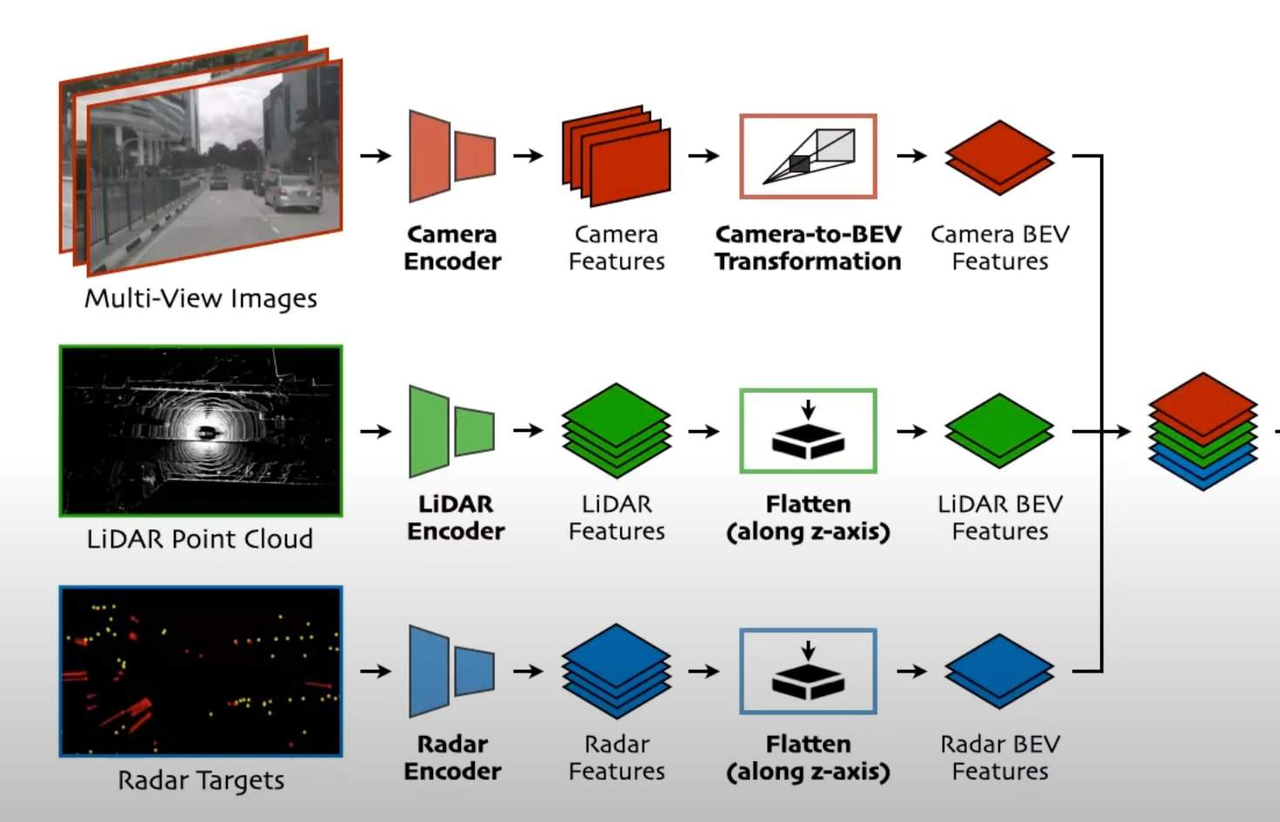
鸟瞰融合(来源)
这可能看起来像一个“中融合”(确实如此),但至少它显示了到 Bird Eye View 空间的各个变换,并且这些变换被融合了。我们使用 Bird Eye View 是因为这样,一切都是通用的。显示车辆的像素与显示相同车辆的点云位置完全相同,依此类推…在这个例子中,数据进入卷积神经网络,然后转换为 Bird Eye View。
快速回顾?
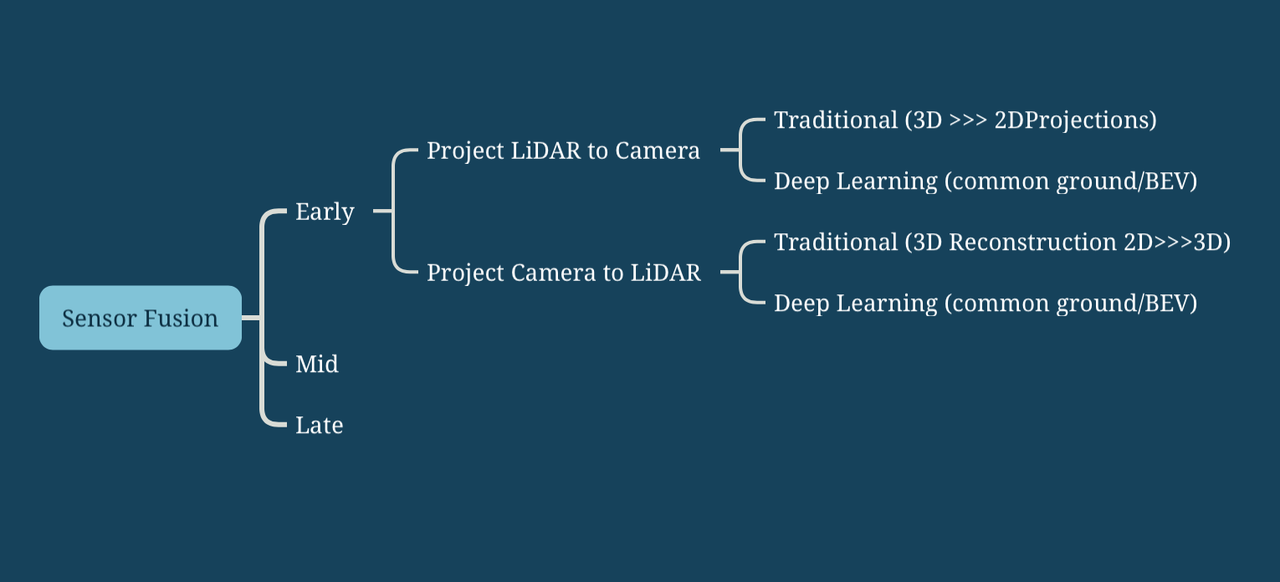
现在问题变成了…如果我们想看中期或晚期融合呢?
何时使用早期融合…何时使用中期和晚期融合?
何时使用早期融合…何时使用中期和晚期融合?
所以,你可能会想:“好的,但是早期融合比晚期融合更好吗?或者有没有应该使用一个而不是另一个的情况?”
但在实践中,早期融合可能更好
或者,这取决于什么吗?
理论上的晚期融合
为了进行后期融合,存在许多可能性,可以使用诸如 IOU 之类的标准 3D 或通过构建代价函数来融合边界框。
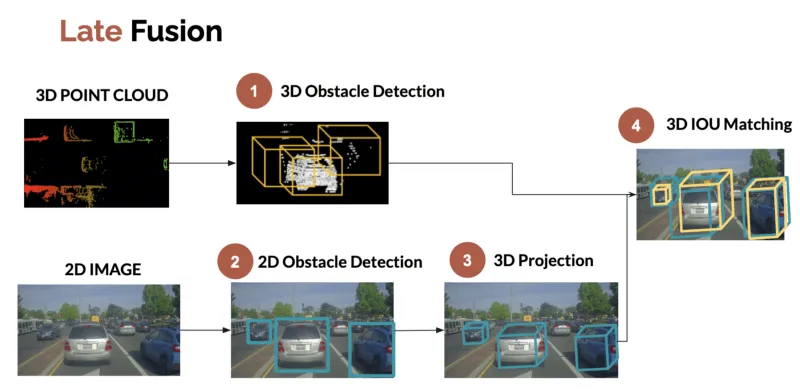
晚期融合过程
这只是理论。
在实践中,早期融合更好吗?
晚期融合可能效果不佳的第一个原因是你的一个传感器不太好。早在 2018 年,我就在研究带有 4 层 2D 激光雷达 SICK 的自主航天飞机。探测器在那里,但它并不是我们今天看到的 3D 的边界盒。

后期融合的问题——一个有故障的传感器可能会毁掉一切
激光雷达:绿色|相机;红色
看到了吗?这里的后期融合非常困难,因为其中高一个传感器不是很好。
第二个原因可能是算法本身。如果你使用的是激光雷达物体检测器,而它无法检测到物体,那么在进行融合你就有麻烦了,如果在相机上进行 3D 物体检测也是如此。

晚期融合问题:算法可以告诉不同的事情。如果无法获得地面实况,你会信任谁?宁愿跳过行人,还是无缘无故地闯入高速公路?
这只是一个例子,但是可能会发生数百个不同的传感器不同意的例子;因此,必须构建复杂的多模态融合策略来处理未知对象或表示不足的对象等…
这取决于?
另一方面,早期要么是将点投影到图像上,要么是深度学习特征提取,这可能会变得非常复杂。因此,上下文很重要,你的工程师对几何足够熟悉吗,对深度学习?还是他们主要坚持基本的模式识别和分类任务?
那么今天在研究中是怎么做的?
示例 1:Waymo 的晚到早融合
2023 年末,Waymo 发布了一篇名为 LEF 的新论文:激光雷达 3D 物体检测的晚到早时间融合,论文里将早期和晚期融合结合在一起。现在这是最领先的!
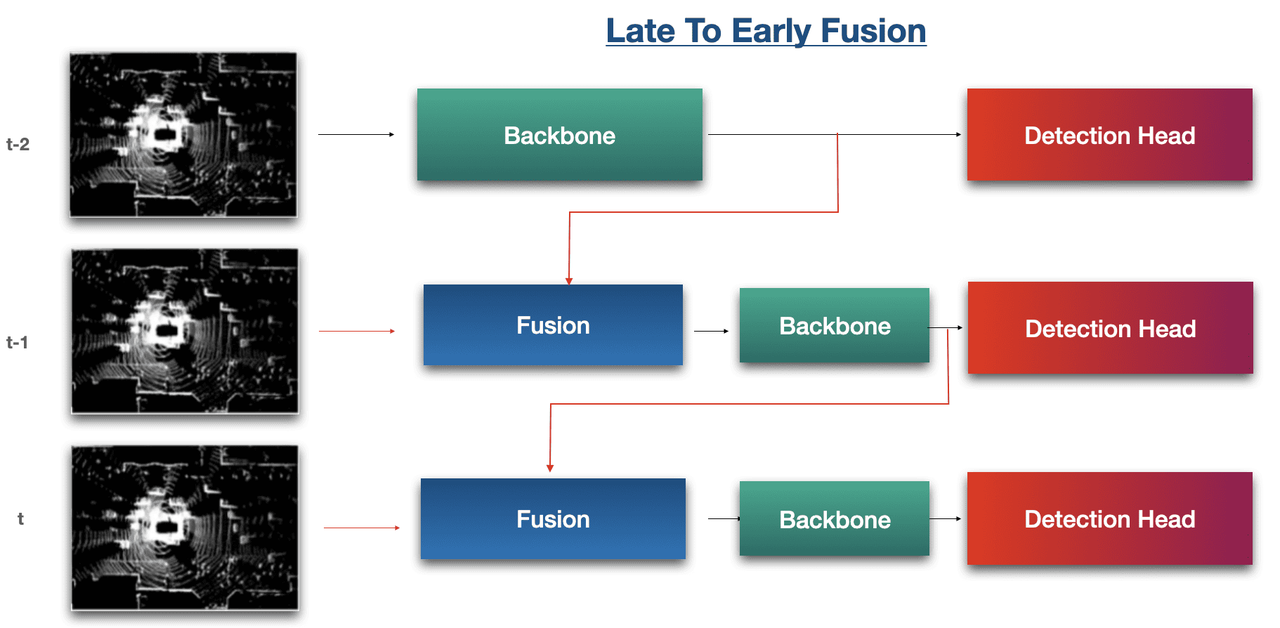
Waymo 的晚到早融合策略
highlights:
早期到早期:我们将原始数据(t-1)与原始数据(t)融合
晚到晚,我们将主干(t-1)与主干(t)融合
从晚到早,我们将主干(t-1)与原始数据(t)融合
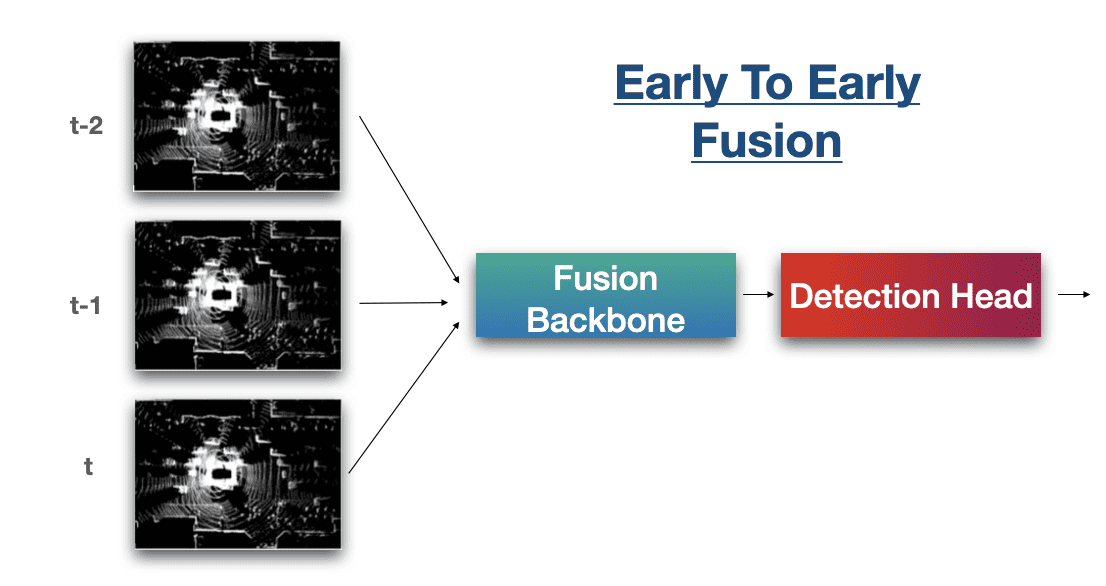
早期到早期融合会是什么样子-时间融合
示例 2:Aurora 的深度融合架构
我已经写了一篇关于 Aurora 传感器融合算法的完整文章,我使用这个例子的次数太多了,以至于我觉得它被夸大了。然而,我相信它是最具代表性的融合算法。
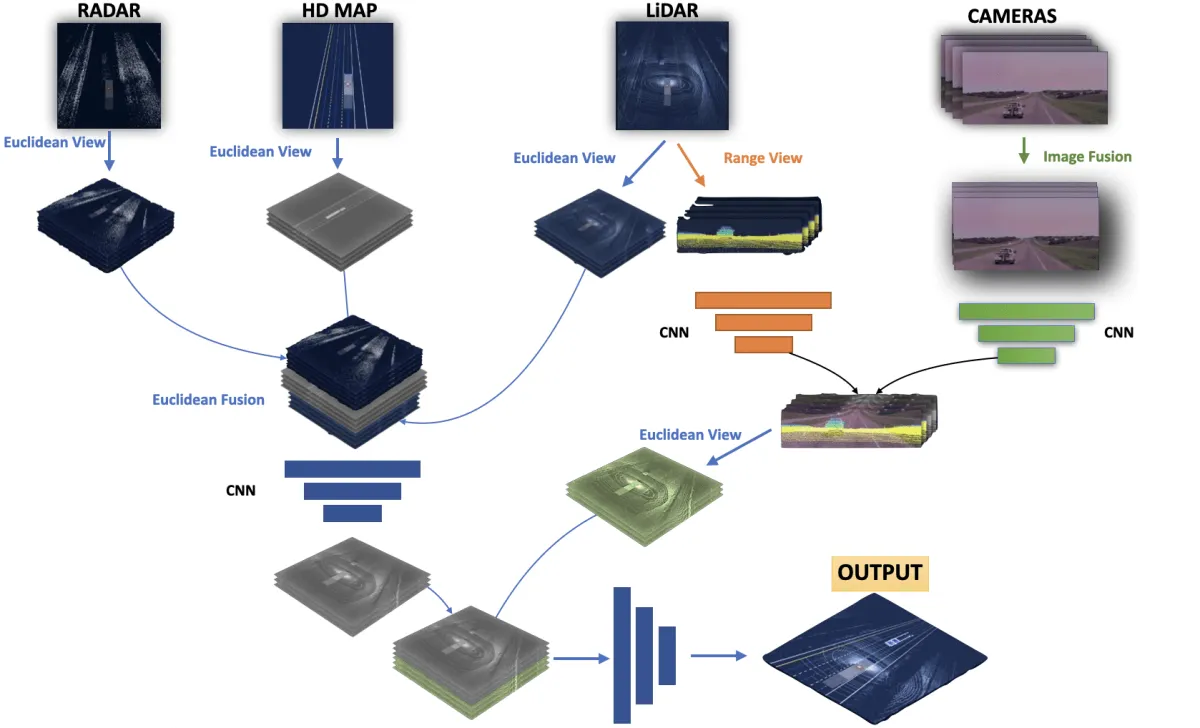
Aurora 的美丽传感器融合管道
highlight:
欧几里得景观"表示鸟瞰景观
「范围视图」就是我们之前提到的 2D LiDAR 视图
融合使用雷达、HD 地图、激光雷达和多个摄像机完成
总结
当使用多个传感器时,我们有许多不同的选择来“何时”融合它们。可以是在数据级别,这将被称为早期融合;或者在特征级别,这将被称为中期融合;或者在对象级别,这将被称为晚期融合。
早期融合包括在处理之前合并数据。可以通过从一帧到另一帧的投影(例如点云到图像空间)或使用神经网络来做到这一点。
经典方式(投影)涉及几何和公式。它可能非常可靠,但高度取决于您的传感器及其校准方式,还涉及到正在“丢失”一个维度,因为将 3D 点投影到 2D 意味着现在正在 2D 中工作。
神经网络的方式可能会感觉更复杂。在实践中,它涉及通过连接层合并数据,然后使用合并的信息。然而,大多数研究人员更喜欢先进行特征提取,或者融合范围视图,然后融合 Bird Eye View 空间中的传感器(中间融合)。
早期和晚期融合都不比另一种更好;它非常依赖于上下文。晚期融合可以解决更容易的问题,而其他人可以尝试两种方法。晚期融合的缺点是高度依赖传感器和检测算法。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)