
该示例为参考算法,仅作为在J6上模型部署的设计参考,非量产算法
简介
BEVFormer是当前热门的自动驾驶系统中的3D视觉感知任务模型。BEVFormer是一个端到端的框架,BEVFormer可以直接从原始图像数据生成BEV特征,无需依赖于传统的图像处理流程。它通过利用Transformer架构和注意力机制,有效地从多摄像头图像中学习生成高质量的鸟瞰图(Bird's-Eye-View, BEV)特征表示。相较于其他的BEV转换方式:
- 时空注意力机制:模型结合了空间交叉注意力(Spatial Cross-Attention, SCA)和时间自注意力(Temporal Self-Attention, TSA),使网络能够同时考虑空间和时间维度上的信息。融合历史bev特征来提升预设的BEV空间中的query的自学能力,得到bev特征。
- Deformable attn:通过对每个目标生成几个采样点和采样点的offset来提取采样点周围的重要特征,即只关注和目标相关的特征,减少计算量。
- transformer架构:能够有效捕捉序列中的长期依赖关系,适用于处理图像序列。
性能精度指标
模型参数:

性能精度表现:
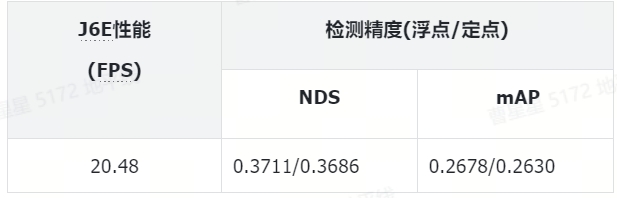
模型介绍
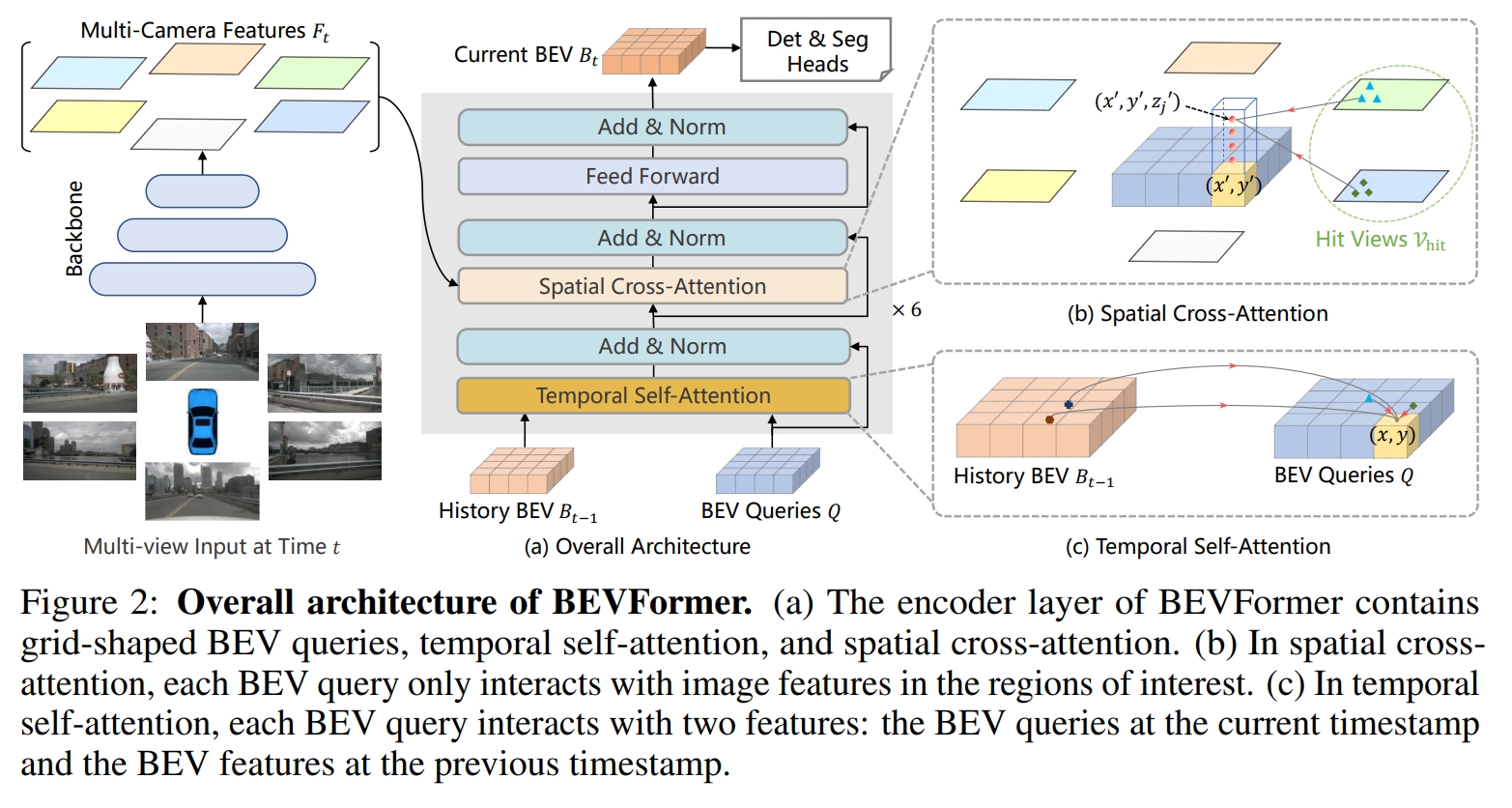
公版BEVFormer模型主要可以分为以下几个关键部分:
- Backbone网络:用于从多视角摄像头图像中提取特征,本文为tiny版本,因此为ResNet50。
- 时空特征提取:BEVFormer通过引入时间和空间特征来学习BEV特征。具体来说,模型包括:
- Temporal Self-Attention(时间自注意力):利用前一时刻的BEV特征作为历史特征,通过自注意力机制来计算当前时刻的BEV特征。
- Spatial Cross-Attention(空间交叉注意力):进行空间特征注意力,融合多视角图像特征。
- Deformable Attention(可变形注意力):BEVFormer使用可变形注意力机制来加速运算,提高模型对不同视角图像特征的适应性。
- BEV特征生成:通过时空特征的融合,完成环视图像特征向 BEV 特征的建模。
- Decoder:设计用于3D物体检测的端到端网络结构,基于2D检测器Deformable DETR进行改进,以适应3D空间的检测任务。
地平线部署说明
公版bevformer在J6上部署相比于J5来说更简单了,需要考虑的因素更少。J6对非4维的支持可以和4维的同等效率,因此J6支持公版的注意力实现,不再限制维度,因此无需对维度做Reshape,可直接支持公版写法。但需注意的是公版的bev_mask会导致动态shape。J6不支持动态输入,因此bev_mask无法使用。在精度上,我们修复了公版的bug已获得了精度上的提升,同时通过对关键层做int16的量化精度配置以保障1%以内的量化精度损失。
下面将部署优化对应的改动点以及量化配置依次说明。
性能优化
改动点1:
将attention层的add、sum、mean替换为conv计算,使性能上获得提升。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/bevformer/attention.py
改动点2:
由于目前不支持动态shape,因此模型中无bev_mask,query和referencepoint不做mask。会导致额外耗时。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/bevformer/attention.py
精度优化
浮点精度
改动点3:
公版通过can_bus 初始化ref来做时序融合,然而这个时候bev feat并没有对齐,在attention计算时不能简单的concat起来。因此我们换了一种时序对齐的方式,通过前后两帧的ego2global坐标系转换矩阵将当前帧的bev特征和上一帧对齐,此时ref都是一样的。(非J6不支持,为公版bug),精度上获得提升。
改动点4:
量化精度
为量化精度保证,我们将以下的算子配置为int16或int32输出:
总结与建议
训练建议:
浮点和公版一致即可
qat训练需要将lr降低,使用2e-5,下降策略建议使用StepDecayLrUpdater。
部署建议:
遵循硬件对齐规则,一般Tensor对齐到2的幂,conv like的op H对齐到8,W对齐到16,C对齐到32,若不满足规则时会对Tensor自动进行 padding,造成无效的算力浪费。
建议bev size的选择考虑性能影响。J6相比于J5带宽增大,但仍需注意bevsize过大导致访存时间过长对性能的影响,建议考虑实际部署情况选择合适的bevsize做性能验证。
若出现性能问题可以通过优化backbone或者减少层数或者点数的方式来提升性能,但要注意以上操作可能会导致精度损失,请优先考虑对点数的减少等对精度的影响较小性能收益最高的操作。
在注意力机制中存在一些add、sum等ElementWise操作,对于导致性能瓶颈的可以考虑conv替换,对于造成量化风险的可以根据敏感度分析结果合理选择更高的量化精度,以确保注意力机制的部署。
本文通过对Bevformer在地平线征程6上量化部署的优化,使得模型在该计算方案上用低于1%的量化精度损失,得到latency为52.63ms的部署性能,同时,通过Bevformer的部署经验,可以推广到其他模型部署优化,例如包含MSD模型结构、transformer-based BEV的部署。
附录
论文:https://arxiv.org/pdf/2203.17270
公版代码:https://github.com/fundamentalvision/BEVFormer



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
