
问题记录
问题:hrt_model_exec --help # 命令报错如下:
-bash: hrt_model_exec: command not found
解决:可以试下在hrt_model_exec目录下运行以下三条命令export ,换成自己的地址LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/map/output_shared_J6_aarch64/aarch64/lib/
export PATH=$PATH:/map/output_shared_J6_aarch64/aarch64/bin/
chmod 0777 hrt_model_exec
执行完后输入./hrt_model_exec测试是否执行完毕,成功如下图
问题:执行hb_compile --config samples/ai_toolchain/horizon_model_convert_sample/03_classification/03_resnet50/resnet50_config.yaml
命令,对示例模型resnet50_224x224_nv12进行转换,发现用于板端的hbm模型输入变成了1x224x224x3(按照用户手册的说法应该是1x3x224x224和原fp32-onnx模型一致)
解答: 这是,正常的,因为nv12对应的layout是NHWC,和bpu接受的layout对齐,用bgr的数据喂入,图像输入 rt 用nv12,_train和模型训练保持一致,图像用rt更高效。
问题:BEVFormer模型编译时转换进度卡在17%不动了,CPU占用率很低,内存占用一直不动。hb_compile --fast-perf --model bevformer_tiny_resnet18.onnx --march nash-e
解答:将hbdk更新至最新版。
问题:开发机编译出的模型到板子上跑不通,遇到以下问题
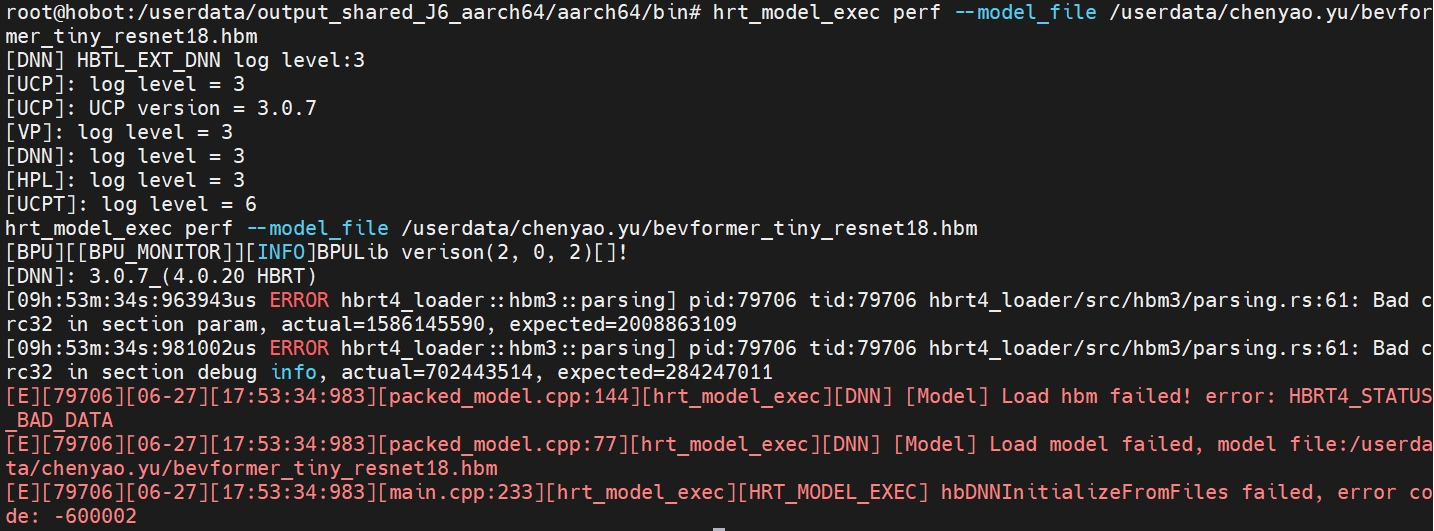
解答:确定md5码开发机和板子里两个文件是否一致
md5sum *查看当前路径下所有文件的md5码,不一致将其下载到本地再粘贴到板子(解决了),
但发现还是有问题
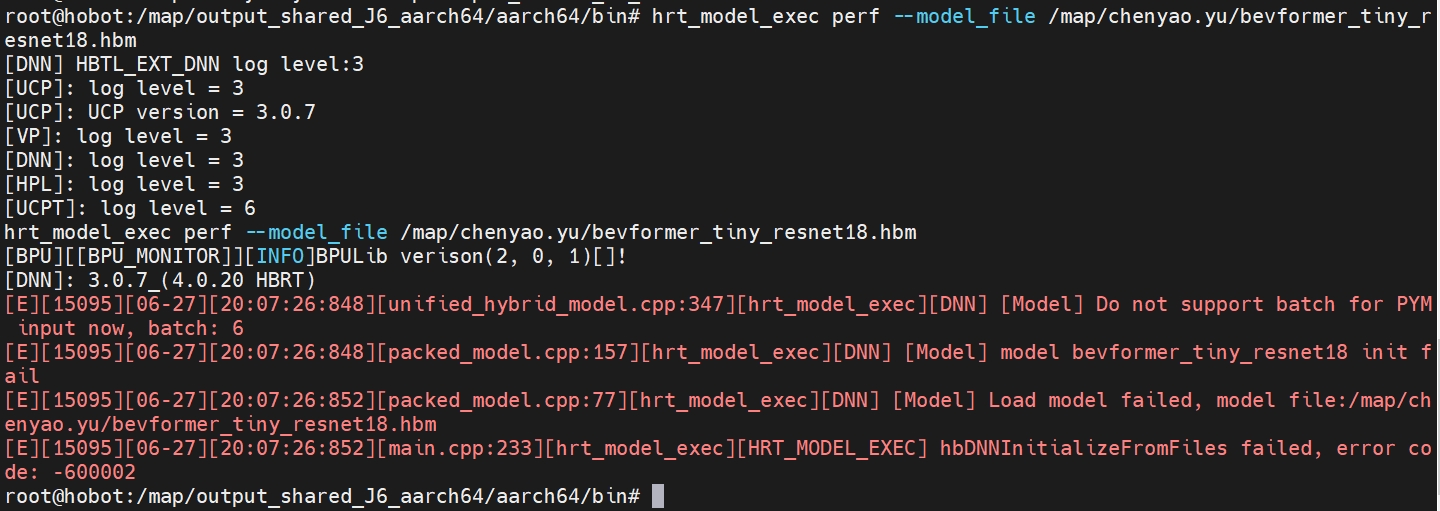
解决:现在的版本,板端对于 PYM来源的输入不支持多batch,不支持指的是输入数据的内存地址不能连续,所以需要对输入进行拆分,模型仍然是多batch推理。目前多batch的模型不能直接用hb_perf转换编译,需要拆成单batch输入,或者把yaml里的input_type_rt修改为featuremap类型;
问题:

解答:大概率是opset version版本太高导致的,可以降到11试一下,导出onnx模型时opset version版本调为11后模型测试成功
问题:
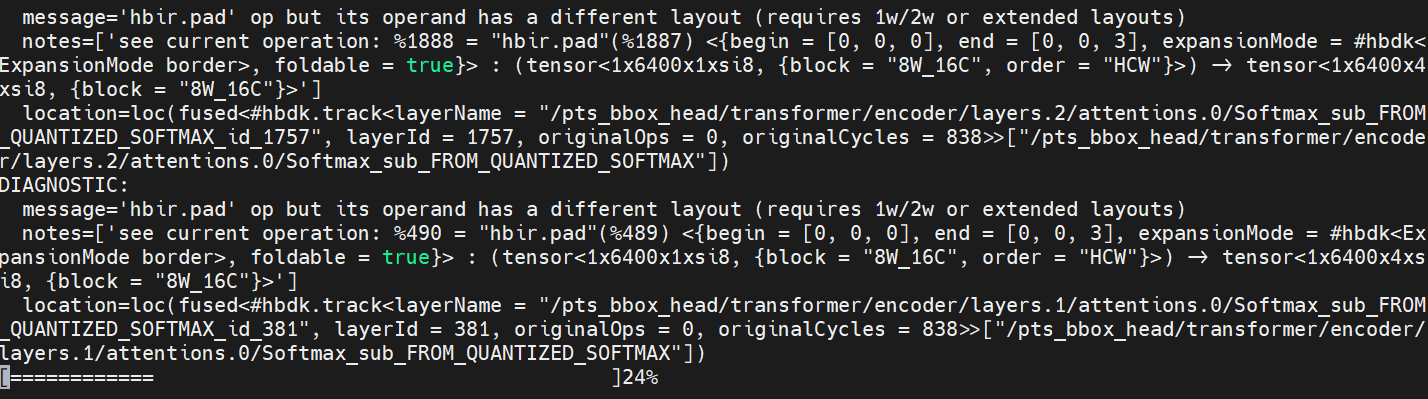
解答:模型编译时卡住了,由于模型太大,可以让客户把图片输入调小一点
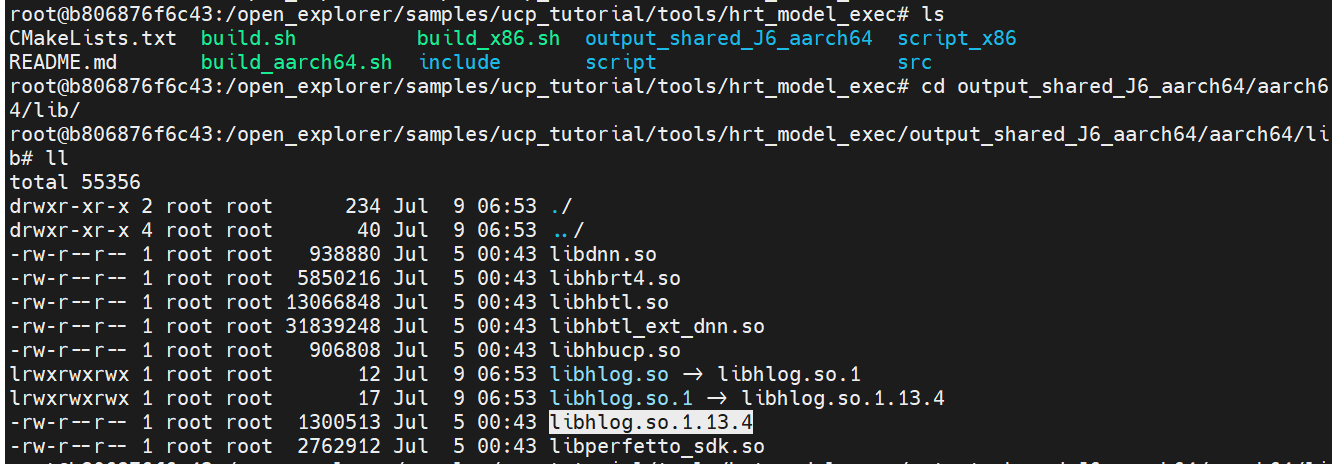
问题:编译/samples/ucp_tutorial/tools/hrt_model_exec/里的build_aarch64.sh,对hrt工具等进行编译
解答:下载到本地,copy到板端时遇到了两个软连接copy不过去的情况,此时ll看一下软连接的路径,发现都是到libhlog.so.1.13.4,所以下载下来后将libhlog.so.1.13.4文件复制两份,分别改名为libhlog.so和libhlog.so.1即可
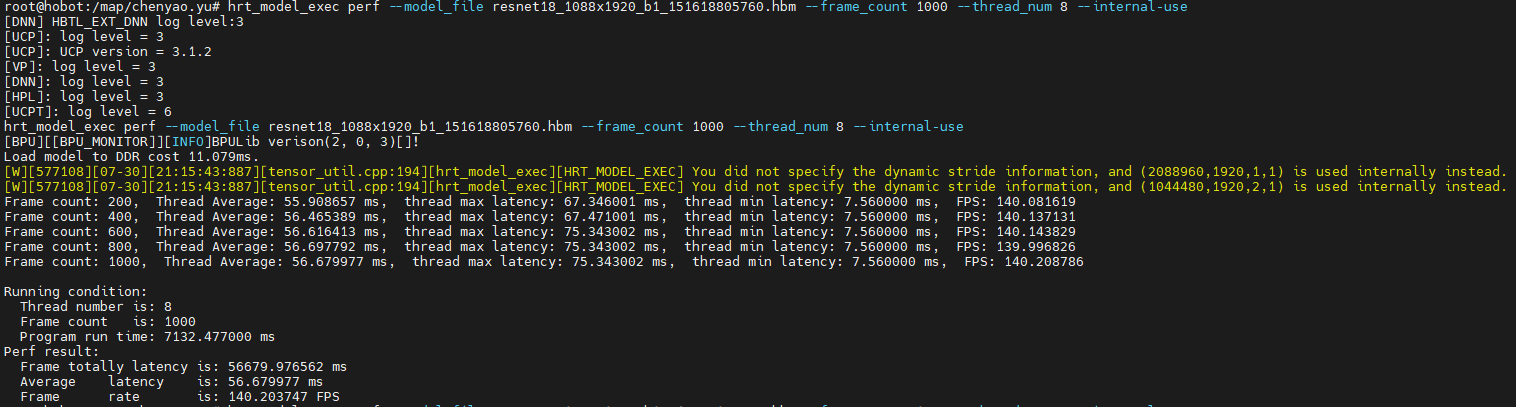
问题:

解答: hrt_model_exec perf --model_file resnet18_1088x1920_b1_151618805760.hbm --frame_count 1000 --thread_num 8 --internal-use
问题:内存不足
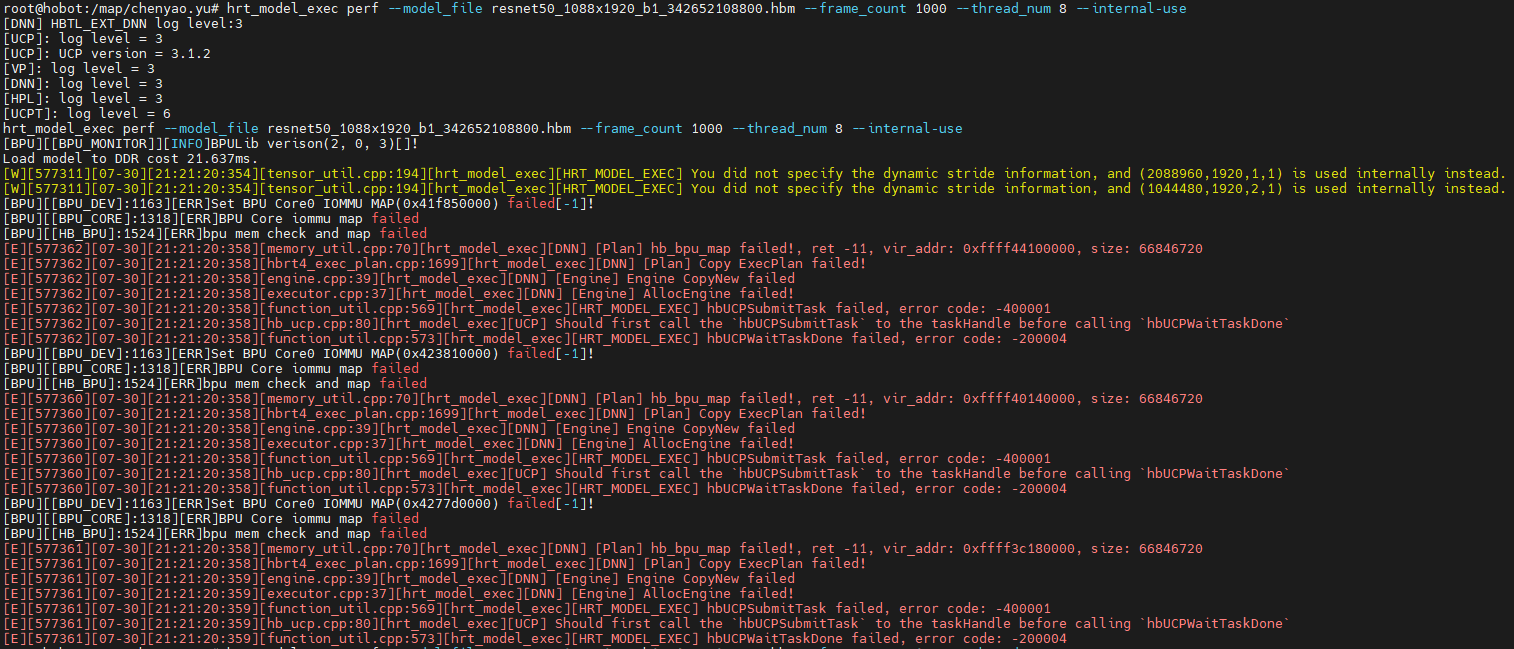
解决:hrt_model_exec perf --model_file resnet18_1088x1920_b1_151618805760.hbm --frame_count 1000 --thread_num 8 --internal-use 改为2线程,解决
问题:怎么输出算子占用情况
解决:hrt_model_exec perf --model_file resnet18_1088x1920_b1_151618805760.hbm --frame_count 1000 --thread_num 8 --internal-use --profile_path ./
当前目录输出算子占用情况,统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
