
目前工具链BPU不支持scatterND算子,这些算子放在cpu上会严重影响模型耗时,这篇文章会分享一些等效替换的示例,帮大家消除模型里的scatterND算子,极大提高模型性能。
ScatterND算子产生的原因
onnx里的ScatterND算子产生的原因是因为模型里存在slice之后的inplace操作导致的,需要修改代码,等价替换掉相关操作即可。
举个例子:
原始代码:
x[:, :2] = x[:, :2].softmax()
return x
修改后:
a = x[:, :2]
b = x[:, 2:]
a = a.softmax()
return torch.cat([a,b] , dim=1)
从上面的例子可以看出,去除scatterND算子的核心是需要保证被赋值的一边不包含slice的inplace的操作即可。
实战演示
上面的例子非常简单,但实际模型结构基本比较复杂,接下来会以sparse4d 模型为例,对模型里的scatterND算子进行等效替换。
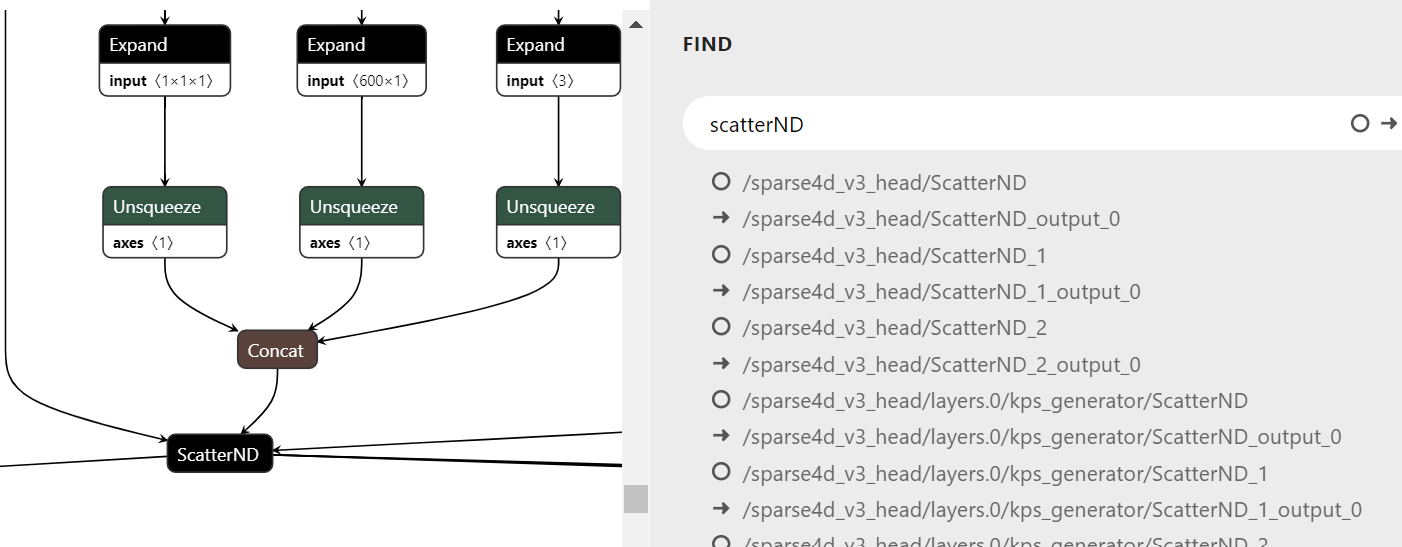
在导出onnx时,打开 verbose=True,这样就能在onnx模型里定位某个算子具体对应哪一行代码。
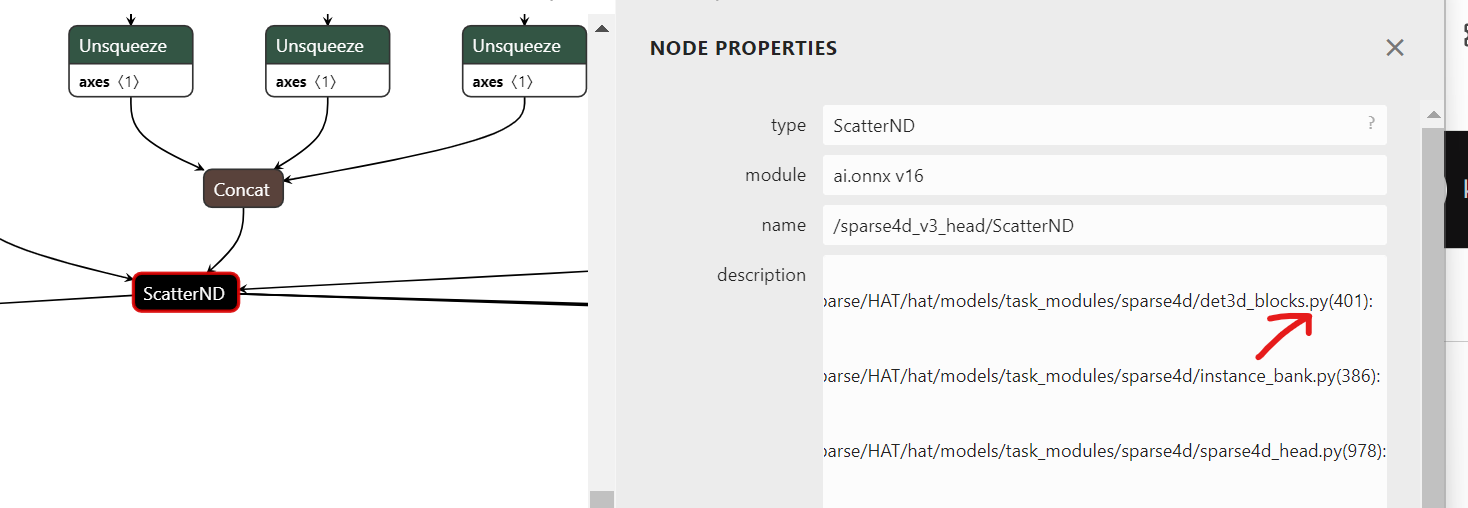
anchor_projection模块
修改前
修改后:
SparseBox3DKeyPointsGenerator模块
修改前:
修改后:
SparseBox3DRefinementModule模块
修改前:
修改后:
InstanceBankAddTrack模块
修改前:
修改后:
性能测试
之前sparse4d模型里存在25个scatterND算子,这些算子都被放在了cpu上,严重影响性能。去除这些算子后,时延降低了20ms,很有效果,推荐大家试一下。
优化前:板端(单线程)耗时 33.237717 ms
优化后:板端(单线程)耗时 13.581193 ms


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)