
1. 理论简介
在阅读本文之前,希望大家对PTQ(Post-Training Quantization) 训练后量化有一定的了解~
地平线OpenExplorer和NVIDIA TensorRT是两家公司为适配自己的硬件而开发的算法工具链,它们各自具有独特的特点和优势。分开看的时候,网上有很多资料,但却没找到将他们放在一起对比的文章,本文从PTQ通路进行对比介绍。
OpenExplorer中文名为天工开物,是地平线发布的算法开发平台,主要包括模型编译优化工具集、算法仓库和应用开发SDK三大功能模块。
- TensorRT 是NVIDIA高性能深度学习的推理SDK,包含深度学习推理优化器和运行时环境,可加速深度学习推理应用。
利用Pytorch、TensorFlow等DL框架训练好的模型,通过模型转换编译生成可以在各家硬件上运行的格式(TensorRT xxx.engine/xxx.trt 或地平线 xxx.hbm/xxx.bin),提升这个模型在各家硬件(英伟达GPU、地平线BPU)上运行的速度。
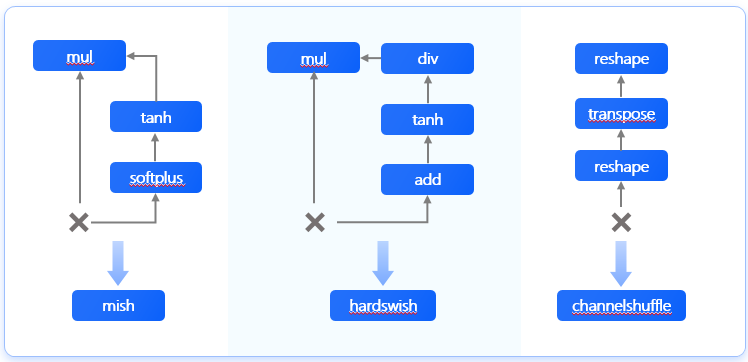
为了让深度学习模型高效的在自家硬件上运行起来,他们都会做很多优化,包括但不限于 量化、数据压缩、算子替换、算子拆分、算子融合等等优化措施,下面以两家show出来的算子融合为例来看一下:
- 英伟达宣传材料中的图片
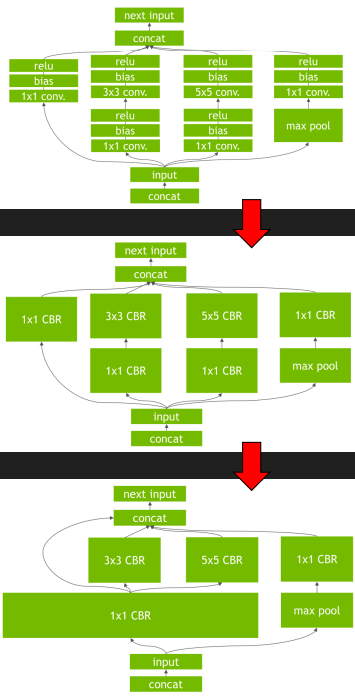
- 地平线宣传材料中的图片
- TensorRT 在进行PTQ 量化(默认进行fp32不量化) 时,会在优化网络的时候尝试 int8 精度,假设某一层在 int8 精度下速度优于默认精度(fp32),则优先使用 int8。支持的数据类型与精度:https://docs.nvidia.com/deeplearning/tensorrt/support-matrix/index.html#layers-precision-matrix,对应的onnx算子:https://github.com/onnx/onnx-tensorrt/blob/main/docs/operators.md
地平线OpenExplorer默认使用int8量化,部分节点BPU支持int16、int32,可以通过node_info、run_on_bpu、run_on_cpu参数控制量化精度以及运行的器件。
TensorRT 的核心在于对模型算子的优化(算子合并、量化、利用 GPU 特性选择特定核函数等策略),通过 tensorRT 能够在 NVIDIA 系列 GPU 上获得最好的性能,因此 tensorRT 的模型,需要在目标 GPU 上实际运行的方式选择最优算法和配置,也就是说 tensorRT 生成的模型只能在特定条件下运行(编译的 trt 版本、cuda 版本、编译时的 GPU 型号),不同硬件之间的优化是不能共享的。但是从tensorrt8.6开始,--hardwareCompatibilityLevel参数可以允许用户在不同的架构上构建和运行模型,可能会带来一些性能损失(视情况而定,5%左右,若某个大的优化只支持特定架构,性能损失会比较大);
OpenExplorer进行PTQ量化时需要指定参数march,指定产出混合异构模型需要支持的平台架构,针对不同硬件,地平线提供的OpenExplorer是不同的,当然,本质上用到的几个whl包是相同的。
2. 参数对比解读
NVIDIA
trtexec工具提供的参数总体上可以分为:Model Options、Build Options、Inference Options、Reporting Options、System Options,最常用到的是前三个;
Horizon J5
hb_mapper工具提供的参数总体上可以分为:模型参数组、输入信息参数组、校准参数组、编译参数组、自定义算子参数组;
hrt_model_exec工具提供模型信息查看、模型推理、模型性能评测三组参数;
Horizon J6
hb_compile等效于hb_mapper工具,新增了一些功能参数,用法上稍有不同
- 同样使用hrt_model_exec工具
可以粗暴理解为:NVIDIA trtexec = Horizon J5 hb_mapper/J6 hb_compile + hrt_model_exec
本文将以NVIDIA trtexec工具(TensorRT-8.6.1)为核心,看看地平线J5 OpenExplorer1.1.68 和J6 OpenExplorer3.0.17 是如何提供与trtexec工具类似功能的。
2.1 模型转换编译(构建)
trtexec工具常用参数与J5 hb_mapper/J6 hb_compile工具对比
2.1.1 Model Options
J5 hb_mapper:--model
- J6 hb_compile:--model
NVIDIA支持ONNX、Caffe、UFF,Horizon支持ONNX、Caffe,但均主流支持ONNX,本文仅介绍ONNX相关内容
2.1.2 Build Options
J5不支持动态shape
J6支持动态shape,hb_compile对应参数:待完善
J5 hb_mapper相关参数有:
node_info # 配置节点输入/输出精度
input_type_rt # 板端模型输入数据格式nv12/rgb/featuremap等
input_layout_rt # 板端输入数据排布NCHW/NHWC
输出排布和onnx保持一致
input_type_train # 原始浮点模型的输入数据类型rgb/bgr等
input_layout_train # 原始浮点模型的输入数据排布NCHW/NHWC
J6 hb_compile相比于J5 hb_mapper的差异:
取消input_layout_rt,板端输入layout与原始浮点输入数据排布相同
增加quant_config参数,支持对模型算子计算精度进行精细化配置
NVIDIA的tensor core和地平线的BPU core都是 HWC 排布的,HWC数据排布是为了编译优化模型性能,虽然CHW和HWC排布均支持,但内部会进行转换。
针对网络输入/输出数据排布,允许用户进行一些控制
J5 hb_mapper以及J6 hb_compile不需要配置类似参数
类似于hb_mapper/hb_compile中advice和debug参数
hb_mapper与hb_compile中无相关参数
允许用户在运行时重新适配(refit)TensorRT 引擎的权重。对于需要在推理过程中动态更新模型权重的场景比较有用,例如在模型部署后需要根据新数据进行微调,强化学习中或在保留相同结构的同时重新训练模型时,权重更新是使用 Refitter(C++、Python)接口执行的。
hb_mapper与hb_compile中无对应参数,默认支持稀疏化
J5 hb_mapper不支持TF32/fp16/fp8、可以通过run_on_cpu或node_info将节点配置运行在CPU上
J5 hb_mapper支持int8和int16以及尾部conv节点int32量化,可以通过node_info或run_on_bpu参数进行配置
J6 hb_compile通过node_info和quant_config,支持对模型算子计算精度进行精细化配置
TF32是英伟达提出的代替FP32的单精度浮点格式,TF32 采用与半精度( FP16 )数学相同的10 位尾数位精度,这样的精度水平远高于AI 工作负载的精度要求。同时, TF32 采用与FP32 相同的8 位指数位,能够支持与其相同的数字范围。
注意:NV不论配置哪一项,fp32都是会使用的。举例:配置--fp16,网络会使用fp16+fp32;配置--int8和--fp16,网络会使用int8+fp16+fp32
类似于hb_mapper/hb_compile --fast-perf功能,主要用于性能评测
类似于J5 hb_mapper run_on_bpu、run_on_cpu、node_info三个参数的功能,支持对模型算子计算精度进行精细化配置
类似于J6 hb_compile node_info和quant_config,支持对模型算子计算精度进行精细化配置
类似于hb_mapper/hb_compile node_info、run_on_cpu、run_on_bpu参数的功能
类似于hb_mapper/hb_compile中如下参数:
cal_data_dir # 模型校准使用的样本存放目录
cal_data_type # 指定校准数据的数据存储类型
trtexec 工具支持送入校准数据,在校准过程中,可以使用 --calib 选项来指定一个包含校准数据的文件。这个文件通常是一个缓存文件,包含了模型在特定输入数据集上运行时的激活值的统计信息。
trtexec 工具本身不提供校准数据的生成功能,需要事先通过其他方式(例如使用TensorRT的API trt.IInt8EntropyCalibrator2)生成,包含了用于量化的统计信息。
NVIDIA校准方法
- IInt8EntropyCalibrator2
熵标定选择张量的尺度因子来优化量子化张量的信息论内容,通常可以抑制分布中的异常值。目前推荐的熵校准器。默认情况下,校准发生在层融合之前,适用于cnn类型的网络。 - IInt8EntropyCalibrator
最原始的熵校准器,目前已不推荐使用。默认情况下,校准发生在层融合之后。 - IInt8MinMaxCalibrator
该校准器使用整个激活分布范围来确定比例因子。推荐用于NLP任务的模型中。默认情况下,校准发生在层融合之前。 - IInt8LegacyCalibrator
该校准器需要用户进行参数化,默认情况下校准发生在层融合之后,不推荐使用。
hb_mapper/hb_compile工具本身不提供校准数据的生成功能,需要事先通过其他方式(例如使用numpy)生成,不包含用于量化的统计信息。
地平线校准方法(校准发生在融合之后)
- default
default 是一个自动搜索的策略,会尝试从系列校准量化参数中获得一个相对效果较好的组合。 - mix
mix 是一个集成多种校准方法的搜索策略,能够自动确定量化敏感节点,并在节点粒度上从不同的校准方法中挑选出最佳方法, 最终构建一个融合了多种校准方法优势的组合校准方式。 - kl
KL校准方法是借鉴了 TensorRT提出的解决方案 , 使用KL熵值来遍历每个量化层的数据分布,通过寻找最低的KL熵值,来确定阈值。 这种方法会导致较多的数据饱和和更小的数据量化粒度,在一些数据分布比较集中的模型中拥有着比max校准方法更好的效果。 - max
max校准方法是在校准过程中,自动选择量化层中的最大值作为阈值。 这种方法会导致数据量化粒度较大,但也会带来比KL方法更少的饱和点数量,适用于那些数据分布比较离散的神经网络模型。
类似于hb_mapper/hb_compile中如下参数:
working_dir # 模型转换输出结果的存放目录
output_model_file_prefix # 指定转换产出物名称前缀
hb_mapper/hb_compile默认启用cache功能
通过时序缓存保存构建阶段的Layer分析信息(特定于目标设备、CUDA版本、TensorRT版本),如果有其他层具备相同的输入/输出张量配合和层参数,则TensorRT构建器会跳过分析并重用缓存结果。
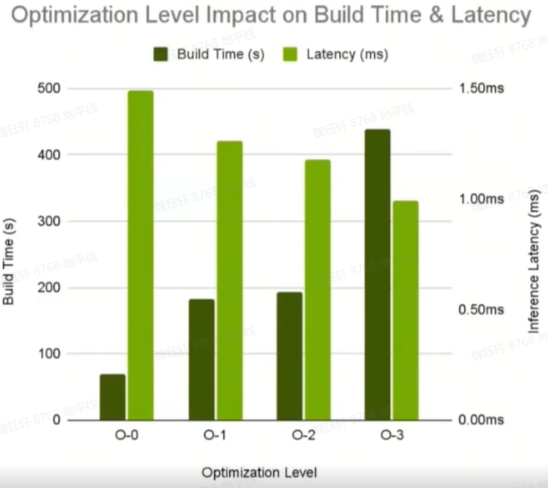
J5 hb_mapper相关参数:optimize_level,范围是O0~O3,默认是O0,耗时评测时需要配置为O3
J6 hb_compile相关参数:optimize_level,范围是O0~O2,默认是O0,耗时评测时需要配置为O2
hb_mapper/hb_compile无相关参数,默认兼容,跨多个版本时可能会存在不兼容的情况
hb_mapper/hb_compile无相关参数,通过march指定架构即可,例如J5的bayes、J6的nash-e/m等
hb_mapper/hb_compile相关参数:
compile_mode # 编译策略选择
balance_factor # balance 编译策略时的比例系数
stream是CUDA中为了实现多个kernel同时在GPU上运行,实现对GPU资源划分,利用流水线的方法提高GPU吞吐率的机制。
并行化操作,地平线会在模型编译时由编译器完成。
2.2 模型推理(评测) Inference Options
trtexec工具常用参数与hrt_model_exec工具(J5、J6都有这个工具)对比
hrt_model_exec相关参数:
model_file # 模型文件路径
model_name # 指定模型中某个模型的名称,针对打包模型,用的较少
J5 尚不支持动态shape、J6待呈现
hrt_model_exec相关参数:input_file
hrt_model_exec相关参数:frame_count
hrt_model_exec不支持warmup,采用多帧推理获取平均值的方式,可以很大程度上规避第一帧多出来的耗时
hrt_model_exec相关参数:perf_time
hrt_model_exec无相关参数
J5 hrt_model_exec无相关参数,没有多流的概念
在 CUDA 中,流(stream)是一种执行模型,它允许开发者将多个计算任务(如内核执行、内存拷贝等)组织成队列,由 GPU 异步执行。使用多个流可以提高 GPU 利用率,因为当一个流的任务等待内存拷贝或其他非计算密集型操作时,GPU 可以切换到另一个流执行计算密集型任务。infStreams 与 CUDA 流的概念直接相关,它影响的是模型推理任务在 GPU 上的并行执行。
maxAuxStreams 是 TensorRT 内部用于优化网络层执行的机制,它允许 TensorRT 在内部使用多个流来并行化可以并行化的层。
两者之间的关系在于它们都旨在通过并行化策略来提高 GPU 上的推理性能,但它们作用的层面和具体实现方式不同。
hrt_model_exec无相关参数
地平线CPU和BPU是共享内存的
hrt_model_exec无相关参数
hrt_model_exec无相关参数
hrt_model_exec无相关参数
启用这个参数时,TensorRT 在等待 GPU 计算完成时使用自旋等待(spin wait)策略,而不是阻塞等待(block wait)。
阻塞等待:在默认情况下,当 TensorRT 引擎执行推理任务时,如果 GPU 计算尚未完成,它会挂起(阻塞)当前线程,直到 GPU 计算完成并返回结果。这种等待方式可能会导致线程在等待期间不执行任何操作,从而影响整体的CPU利用率和系统性能。
自旋等待:启用 --useSpinWait 参数后,TensorRT 会采用自旋等待策略。在这种模式下,线程会循环检查 GPU 计算是否完成,而不是挂起。自旋等待可以减少线程挂起和恢复的开销,从而在某些情况下,例如GPU 计算时间与CPU处理时间相比 较短的情况下。通过减少线程挂起的频率,可以提高CPU的利用率,从而可能提升整体的系统性能。
GPU 计算时间不稳定或较短时,自旋等待可以减少线程上下文切换的开销,并保持 CPU 核心的活跃状态。然而,自旋等待也可能导致 CPU 资源的过度使用,特别是在 GPU 计算时间较长的情况下,因此需要根据具体的应用场景和硬件配置来权衡是否使用这个参数。
hrt_model_exec相关参数:thread_num
"stream(流)"和"thread(线程)"是两个不同的概念,用于处理并发和数据流的情况。
线程(Thread): 线程是计算机程序中执行的最小单位,也是进程的一部分。一个进程可以包含多个线程,它们共享进程的资源,如内存空间、文件句柄等。线程可以并行执行,使得程序能够同时处理多个任务。线程之间可以共享数据,但也需要考虑同步和互斥问题,以避免竞争条件和数据损坏。
流(Stream): 流是一种数据传输的抽象概念,通常用于输入和输出操作。在计算机编程中,流用于处理数据的连续流动,如文件读写、网络通信等。流可以是字节流(以字节为单位处理数据)或字符流(以字符为单位处理数据)。流的一个常见特性是按顺序处理数据,不需要一次性将所有数据加载到内存中。 总之,线程是一种用于实现并发执行的机制,而流是一种用于处理数据传输的抽象概念。
hrt_model_exec无相关参数
useCudaGraph参数允许用户指示 TensorRT 在执行推理时使用 CUDA 图(CUDA Graph)。CUDA 图是一种 CUDA 编程技术,它允许开发者创建一个或多个 CUDA 内核及其内存依赖关系的静态表示,这可以提高执行效率和性能。
CUDA 图的优势
性能提升:通过使用 CUDA 图,可以减少运行时的开销,因为它们允许预编译一组 CUDA 操作,从而减少每次执行操作时的启动延迟。
重用性:一旦创建了 CUDA 图,它可以被重用于多个推理请求,这使得它特别适合于高吞吐量和低延迟的应用场景。
使用场景
高并发推理:在需要处理大量并发推理请求的场景中,使用 --useCudaGraph 可以提高处理速度和效率
hrt_model_exec会在终端中打印 加载 板端模型 的时间
反序列化时间:--timeDeserialize 参数会让 trtexec 测量将序列化的 TensorRT 引擎文件加载到 GPU 内存中所需的时间。
性能分析:通过测量反序列化时间,开发者可以了解模型加载阶段的性能瓶颈,并探索减少模型加载时间的方法。
hrt_model_exec无相关参数
猜测:重新适配(refitting)是指在模型转换为 TensorRT 引擎后,根据新的权重或校准数据更新引擎的过程,比如将模型的权重从一种精度转换为另一种精度,或者根据新的校准数据调整量化参数。
类似于hb_mapper/hb_compile中debug参数,debug默认配置为True,编译后会在 html 静态性能评估文件中增加逐层的信息打印,可以帮助分析性能瓶颈。该参数开启后不会影响模型的推理性能,但会极少量地增加模型文件大小。
trtexec使用该参数,一次用于收集性能分析数据的运行,另一次用于计算性能基准测试的运行,提高分析/测试的准确性。
地平线 模型构建与模型推理/性能评测是分开的,无相关参数
地平线无相关参数
缓存管理:--persistentCacheRatio 参数用于控制 TensorRT 引擎在执行推理时分配给持久化缓存的内存比例
性能优化:合理设置缓存比例可以提高模型的推理性能,尤其是在处理大型模型或复杂网络结构时
内存使用:增加持久化缓存的比例可能会减少内存占用,但也可能导致缓存溢出
TensorRT 会自动管理缓存,因此手动设置--persistentCacheRatio不是必须的。只有需要精细控制内存使用或优化性能时才会用到
2.3 报告选项 Reporting Options
地平线无相关参数
日志中增加很多信息,类似于:[08/09/2024-17:18:51] [V] [TRT] Registered plugin creator - ::BatchedNMSDynamic_TRT version 1
类似于hrt_model_exec中frame_count参数
为了减少偶然因素对性能测试结果的影响,通过多次运行推理并取平均值来提供一个更加稳定和可靠的性能度量。
hrt_model_exec中无相关参数
设置 --percentile=99,trtexec 将会报告第 99 百分位的执行时间,这意味着在 100 次推理中,有 99 次的执行时间会小于或等于报告的值,而只有 1 次的执行时间会大于这个值。故:0 representing max perf, and 100 representing min perf
hrt_model_exec中无相关参数
hb_mapper/hb_compile默认会在日志中打印层的信息
hb_mapper/hb_compile默认开启debug参数后,会在转换编译过程中生成html文件,其中有类似的层耗时信息
hrt_model_exec工具中profile_path参数
类似于J5 hrt_model_exec中dump_intermediate、enable_dump、dump_format等
hrt_model_exec无相关参数
2.4 系统选项 System Options
类似于hrt_model_exec中core_id参数
类似于J5 hb_mapper中custom_op_method、op_register_files、custom_op_dir参数
J6 hb_compile待确定
各家的工具都会针对自己的硬件或特性设计针对性的参数,只要满足开发者需要的功能即可,例如地平线工具链的一些参数,有一些就没介绍到。
这么多参数其实并不是都会用到,大家根据自己的需求选择性使用即可。
3. 实操演示
3.1 onnx模型生成
上述代码运行后,会生成一个static.onnx,接下来就可以使用这个onnx啦。
3.2 性能评测实测
实操的方向不同,使用的命令和脚本也会有差异,本文重点在对比两家工具链的PTQ 功能参数对比介绍上,因此只选择一个性能评测方向进行实操演示。
英伟达trtexec
构建用于性能评测的engine,另外性能数据可以一起产出,脚本如下:
会产出engine文件:resnet18.engine,以及一些日志,例如:
地平线hb_compile与hrt_model_exec
转换编译用于性能评测的hbm

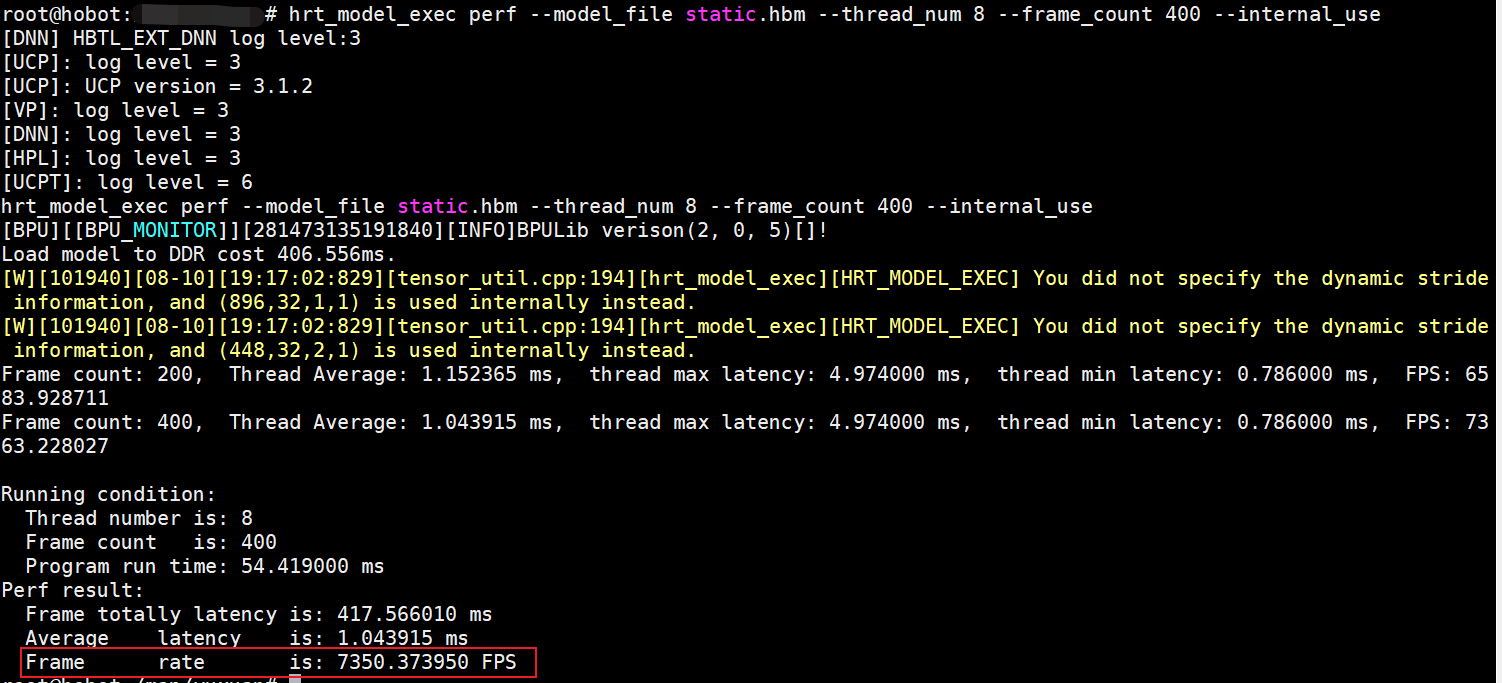
在板端评测性能数据
由于时间原因,就先到这儿了,下次再聊~



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)