
写在前面:
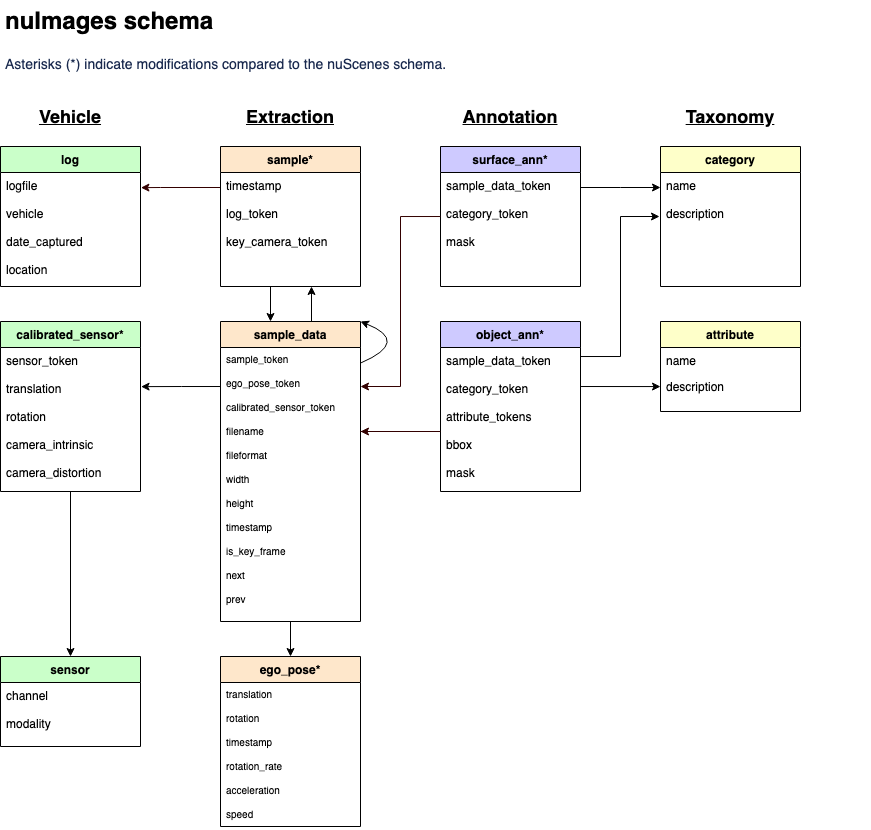
Nuscenes数据集还包含了许多参考算法模型不需要的数据,因此本文档除了分析Nuscenes数据集对应的dataloader给模型输入了哪些信息,还对照参考算法分析了哪些信息是模型真正需要的,由此为用户建立用户数据集并构建对应的dataset和dataloader提供支撑。
Dataloder构建&&单帧数据获取
如果用户想动手操作,需要准备下需要用到的Nuscenes数据集,可以按照以下步骤打包数据集。
Mini dataset版本数据集打包和meta文件夹构建
数据集打包以mini数据集为例,full数据集打包时间过长,且我们只是为了解析dataloader,所以只需取小部分数据为例即可。
数据集打包
如果下载的是Full dataset(v1.0)中的Mini、CAN bus expansion和Map expansion(v1.3)、nuScenes-lidarseg这四个项目下的文件,将下载完成的v1.0-mini.tgz、nuScenes-lidarseg-all-v1.0.tar.bz2、nuScenes-map-expansion-v1.3.zip和can_bus.zip进行解压,解压后的目录如下所示:
打包结束生成目录如下所示。
--src-data-dir为解压后的nuscenes数据集目录;
--target-data-dir为打包后数据集的存储目录;
--version 选项为 "v1.0-mini";
meta文件夹构建
- 在tmp_data/nuscenes 下创建meta文件夹,如果使用--version = "v1.0-mini",将解压后的v1.0-mini文件夹拷贝到tmp_data/nuscenes/meta 文件夹内;
- 将解压后的maps文件夹拷贝到tmp_data/nuscenes/meta 文件夹内;
- 将解压后的lidarseg文件夹拷贝到tmp_data/nuscenes/meta 文件夹内。
如果使用--version = "v1.0-mini",此时tmp_data的目录结构为:
单帧数据获取
sample的结构如下

sample中共有4部分内容:'seq_meta'、'img'、'cam2ego'、'camera_intrinsic'。
1.seq_meta
seq_meta的结构如下
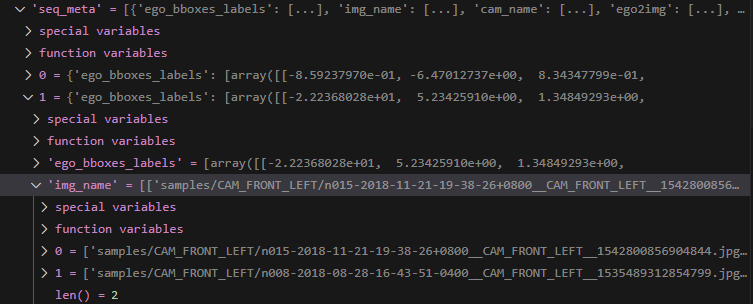
可以看到seq_meta内有3个连续时间序列的meta,每个meta内又包含ego_bboxes_labels、img_name、cam_name、ego2img、layout、color_space、scene、sample_token、ego2global、lidar2global、lidar2img、meta在内的12类信息,每个信息都有2份,这是因为batch_size_per_gpu =2。
1.1.ego_bboxes_labels
代表这一时刻6个相机输出的图像中共包含46个目标,每行代表1个目标,上述tensor的前9列代表bboxes的label,最后一列代表class的label。
1.2.img_name
代表某时刻6个相机输出的图像名称,从名称可见其时间戳是对齐的
代表6个相机名称
1.5-1.8:layout、color_space、location、scene、timestamp、sample_token
layout意义不详,color_space代表数据集图像的色彩空间为rgb格式,location表示该帧数据采集地点,scene代表该帧数据所属scene对应的token,timestamp代表该帧数据的时间戳
1.9.ego2global
代表自车坐标系到全局坐标系的4x4转换矩阵
1.10.lidar2global
代表激光雷达坐标系到全局坐标系的4x4转换矩阵
1.11.lidar2img
分别代表6个相机中激光雷达坐标系到相机像素坐标系的4x4变换矩阵
1.12.meta
包含:自车坐标系到全局坐标系的平移向量和旋转向量、传感器坐标系到自车坐标系的平移向量和旋转向量
2.img
img中共有36张图像,36=2(batch_size)*3(queue)*6(cam_num),其中每张的尺寸为3x480x800
3.cam2ego
分别代表6个相机中相机像素坐标系到自车坐标系的4x4变换矩阵,36=2(batch_size)*3(queue)*6(cam_num),可想而知,36个变换矩阵中只有6个彼此不同的矩阵
4.camera_intrinsic
代表6个相机的内参矩阵,36=2(batch_size)*3(queue)*6(cam_num),可想而知,36个内参矩阵中只有6个彼此不同的矩阵
BEVFormer中使用到的数据集信息
以下img、seq_meta:ego_bboxes_labels、seq_meta:lidar2img/ego2img、seq_meta:meta、seq_meta:ego2global是BEVFormer参考算法中使用到的信息,如果大家需要自己构建数据集,只需包含以下信息即可。
1.img
见bevformer.py,提取图像特征,用于encoder的SCA
2.seq_meta:ego_bboxes_labels
见criterion.py:forward,用于计算Loss
3.seq_meta:lidar2img or ego2img
见view_transformer.py:point_sampling,用于生成bev_mask和reference_points_cam
4.seq_meta:meta
见view_transformer.py:get_prev_bev,用于判断前后两帧是否属于同一scene中
5.seq_meta:ego2global
见view_transformer.py:get_refine_coords,用于对齐pre_bev和bev


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)