
环境部署部分在工具链开发手册 OpenExplorer 环境部署 中有涉及,但考虑手册是重点为指导用户如何使用工具链的相关组件,并没有对环境准备部分展开说明,但作为工具链使用的环境基础,不可谓不重要。因此本章作为工具链环境准备部分的补充,从系统安装到docker环境部署,逐步引导用户构建起工具链的使用环境。当然,如果你对Linux操作比较熟悉,会对环境部署部分有更好的理解和掌握。
1. 系统准备
1.1 操作系统选择&安装
在工具链的环境部署部分已经向用户推荐的了操作系统的类型和版本:原生Ubuntu 22.04。考虑到不同用户对安装包的使用场景存在差异,这里对两种比较典型的场景 虚拟机场景 和 物理机服务器场景 加以说明。
1.1.1 虚拟机场景
Ubuntu 22.04是一个比较成熟的Linux版本,网络上对于如何在虚拟机中进行安装配置也有很详细的文章,这里不再赘述,仅提供以下网络文章供参考:
1.1.2 物理机服务器场景
Ubuntu 22.04是一个比较成熟的Linux版本,如何在一台新的物理机上安装配置22.04版本的Ubuntu操作系统网络上有很详细的文章,这里不再赘述,仅提供以下网络文章供参考:
1.2 常用组件安装
2. 驱动安装
2.1 显卡型号查看
-i 表示不区分大小写
示例如下:

2.2 驱动版本选择&安装
2.2.1 确定显卡驱动是否已经安装 以及 最新稳定版本号
- 方法1:(通用)执行命令glxinfo | grep rendering,如果结果是“yes”,证明显卡驱动已经成功安装。
- 方法2:(Nvidia显卡)执行命令nvidia-smi -L判断·nvidia-smi工具·的存在性,存在说明驱动已经安装。
2.2.2 获取和安装最新的稳定版本的驱动
通过 nvidia-detector 来获取最新的稳定版本的驱动,此处假设执行结果为nvidia-driver-545,可通过sudo apt install -y nvidia-driver-545来安装驱动。另外建议除了安装 nvidia-driver 驱动,可以顺带安装 nvidia-dkms ,方便后续如果需要升降级内核的时候,减少不必要的麻烦,即:sudo apt install -y nvidia-dkms-545
2.2.3 查看 已安装显卡驱动版本号 以及 可支持cuda的最高版本号
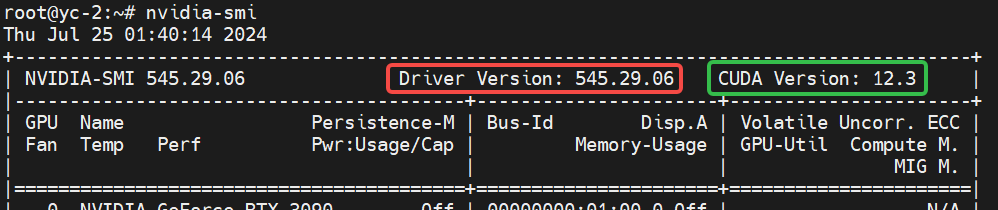
红色框标识出的是当前所安装驱动的版本号。
绿色框标识出的是当前驱动版本下可支持cuda的最高版本号。
3. CUDA安装
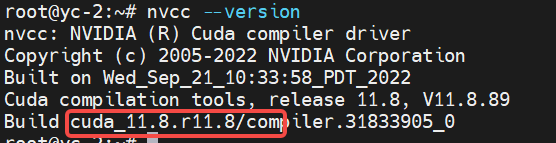
3.1 检测CUDA是否已安装以及版本号
命令nvcc --version可以查看所安装CUDA的版本信息。如果执行时报错命令不存在,说明CUDA尚未被安装。以下示例为CUDA已被安装时的输出结果,可以看出CUDA版本为11.8:
3.2 CUDA版本选择
CUDA的版本的选择由以下几个方面来确定:
- 用户所使用的DL框架版本约束
模型训练过程使用的DL框架往往对CUDA版本是有约束的. 拿最常用的PyTorch来说,PyTorch版本和CUDA版本之间的对应关系可以通过PyTorch官网查看。 - 驱动版本约束
2.2.3节中绿色框部分已经给出的当前驱动版本下可支持cuda的最高版本号,因此所按住的CUDA版本号必须低于最高版本号
## 3.3 CUDA安装
### 3.3.1 下载cuda
到CUDA官网 CUDA Toolkit Archive 找到合适的所需版本并点击下载,这里我们选择11.8。
选择操作系统Linux,架构x86_64,ubuntu22.04,安装方式为runfile(local),如下图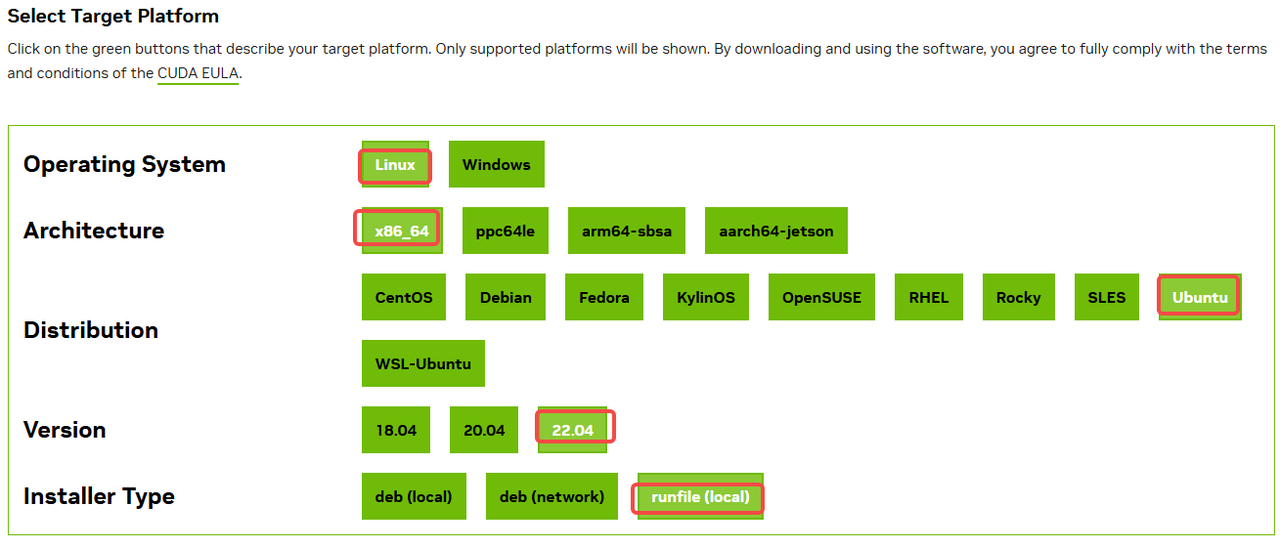
选择完成后,会出现如下安装命令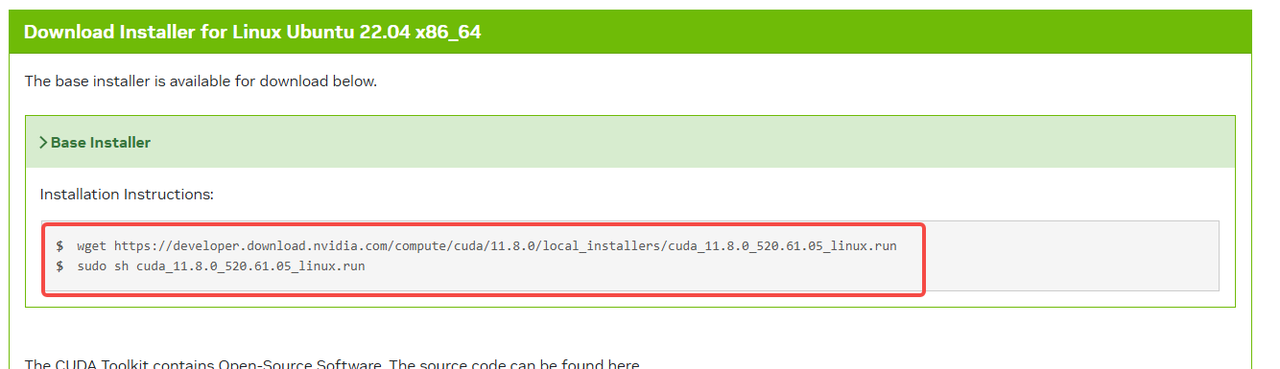
如上图所示在终端使用下方指令进行下载:3.3.2 安装cuda
下载完成使用下方指令安装:
sudo sh cuda_11.8.0_520.61.05_linux.run
弹出窗口按<上下键>选择“continue”,按键盘<回车键>,弹出窗口输入“accept”,按键盘<回车键>,弹出窗口使用<上下键>和<空格键>选择和取消选择,最后选择“install”点击键盘<回车键>,进行安装,如下图:注意:
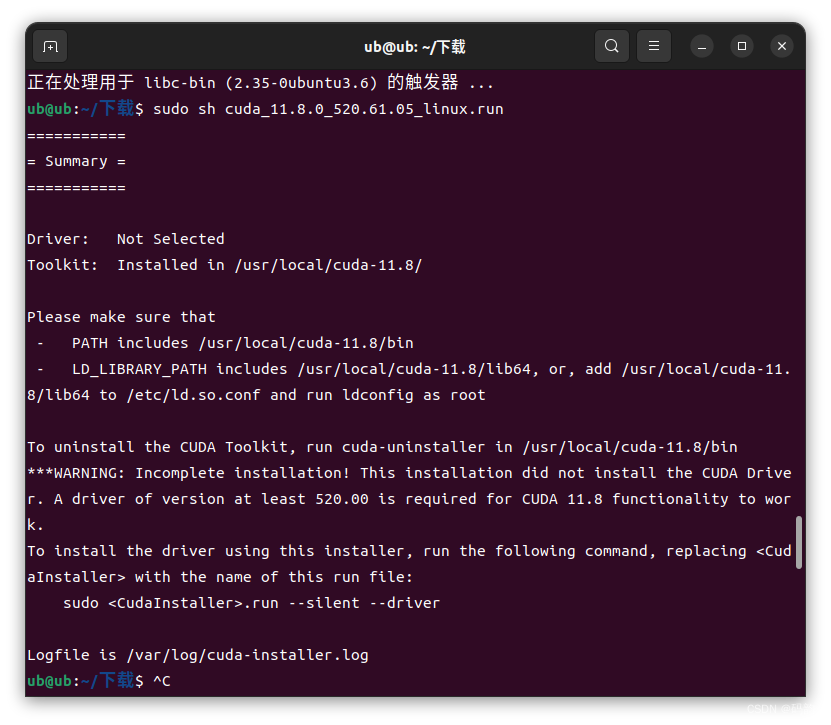
如果已安装最新驱动,可以在弹出窗口中取消驱动的安装,以免造成驱动回退等系统性故障。
- 考虑多个cuda版本共存的可能,可以通Option设置安装prefix到/usr/local/cuda-11.8下
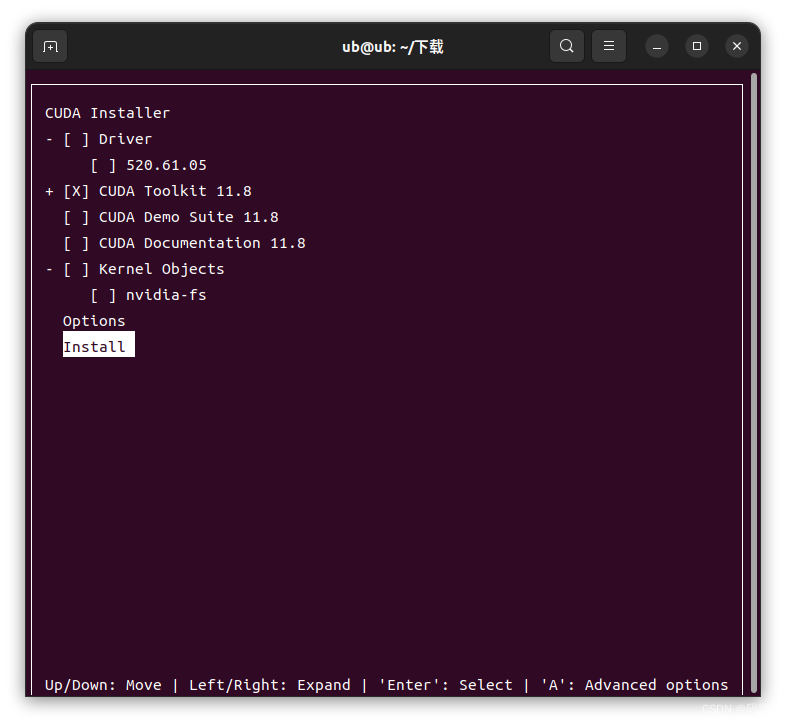
安装好弹出如下图:
3.3.3 设置cuda环境变量
设置cuda环境变量,在~/.bashrc文件末尾加入如下配置项并保存:
保存关闭后,终端使用下方指令更新环境变量
3.3.4 验证cuda是否安装成功
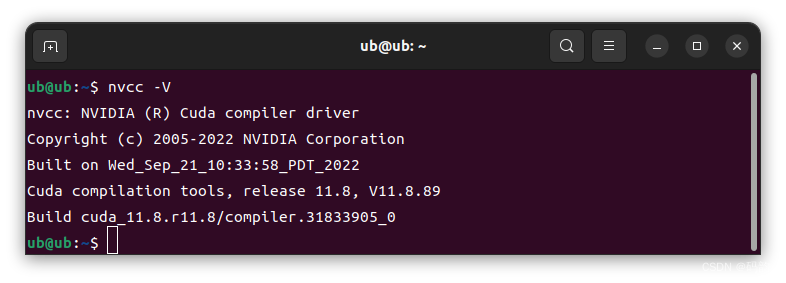
使用下方指令验证cuda是否安装成功:
打印如下即安装成功:
4. Docker & Nvidia Container 安装配置
4.1 Docker基本组件安装
注意:如果当前**非root用户,执行完上述命令后需要重新登录**一下当前用户docker相关命令才能使用。
4.2 Nvidia Container 安装
Nvidia Container为docker提供了显卡运行时环境,想要在 Docker 中能够“调用显卡”,需要安装“NVIDIA 容器工具包存储库”:
命令执行完毕之后,我们的系统中就添加好了 Lib Nvidia Container 工具的软件源,然后更新系统软件列表,使用命令安装 nvidia-container-toolkit 即可:
完成 nvidia-container-toolkit 的安装之后,我们继续执行 nvidia-ctk runtime configure 命令,为 Docker 添加 nvidia 这个运行时。完成后,我们的应用就能在容器中使用显卡资源了:
命令执行成功,我们将看到类似下面的日志输出:
最后,在完成配置之后,别忘记重启 docker 服务,让配置生效:
服务重启完毕,再次查看 Docker 运行时列表,能够看到 nvidia 已经生效,信息如下所示:
Runtimes: nvidia runc io.containerd.runc.v2
4.3 常用docker命令
Docker命令非常丰富,涵盖了从安装、配置、运行到管理的各个方面。以下是一些常用的Docker命令及其用途的概述:
1. 启动类命令:
- systemctl start docker:启动Docker服务。
- systemctl stop docker:关闭Docker服务。
- systemctl restart docker:重新启动Docker服务。
- systemctl status docker:查看Docker运行状态。
- docker version 或 docker info:查看Docker版本号等信息。
2. 镜像管理命令:
- docker images:列出本地镜像。
- docker search 镜像名:搜索Docker Hub上的镜像。
- docker pull 镜像名:从Docker Hub拉取镜像。
- docker run:创建并运行一个容器。常用的参数包括--name为容器命名,-p映射端口,-d后台运行等。
- docker rm 容器名/容器ID:删除容器。
- docker rmi 镜像名:删除本地镜像。
3. 容器管理命令:
- docker ps:列出正在运行的容器。
- docker exec -it 容器名 /bin/bash:进入正在运行的容器进行交互操作。
- docker stop 容器名/容器ID:停止正在运行的容器。
- docker start 容器名/容器ID:启动已停止的容器。
- docker restart 容器名/容器ID:重启容器。
这些命令是Docker使用中最基础也是最常用的,掌握它们对于快速上手和使用Docker进行应用部署和管理至关重要。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)