
1. 引论
2. 部署概论
在展开讨论具体代码接口和框架之前,有几个概念性质的问题需要先和大家对齐以保持思想上的同步,也方便后续一些问题的讨论和交流。
2.1 模型部署概念 和 实施所需知识
简单的,对于一个具体模型的部署任务而言,一般包含3个部分的代码逻辑:推理数据准备,模型推理,推理结果解析和输出。但真实的用户场景往往是比较复杂中,他们的场景的不仅模型文件的个数不止一个,而且不同的任务其优先级也存在差异。对此,地平线在对用户提供的API中专门提供了不同接口,方便用户对复杂场景的控制,这些特殊的接口会在后面的章节中进行说明。然儿无论多么复杂的场景都是在简单场景的技术上构建起来的。因此,本篇文章依然以简单场景模型推理为例,同时对于复杂场景涉及给出一些参考意见和注意事项。
2.2 常规部署流程 和 考虑因素
根据业务复杂性构建模型调度框架(workflow)。
- 进行模型推理数据预处理设计
通过硬件加速链路等高效生成推理过程所需的input数据。 - 推理过程及模型及数据间依赖关系控制
根据任务性质,涉及和排序不同模型任务的调度逻辑,如是否是抢占任务、模型输入输出数据是否有前后依存关系等。 - 模型推理结果解析并与其它过程融合处理生成最感知结果。
# 3. J6模型接口组织框架
## 3.1 框架说明
为解决上一代计算平台开发阶段和部署阶段在验证上存在的一些问题(可参考文章最后的_J6部署框架背后的思考),在新一代J6计算平台中引入了统一异构计算框架HUCP(Horizon Unified Computing Platform),其在部署逻辑中所处的位置如下图所示。可以看出HUCP介于应用程序和运行平台之间,是应用程序和运行平台之间的“中间件”。对上,HUCP为上层应用开发设计和提供了一套统一的应用程序编程接口(API);对下,隐蔽不同CPU架构在接口实现上带来的差异,不同运算平台调用各自的系统接口对HUCP提供的编程接口进行实现和编译以生成不同架构的动态链接库供编译器连接时调用。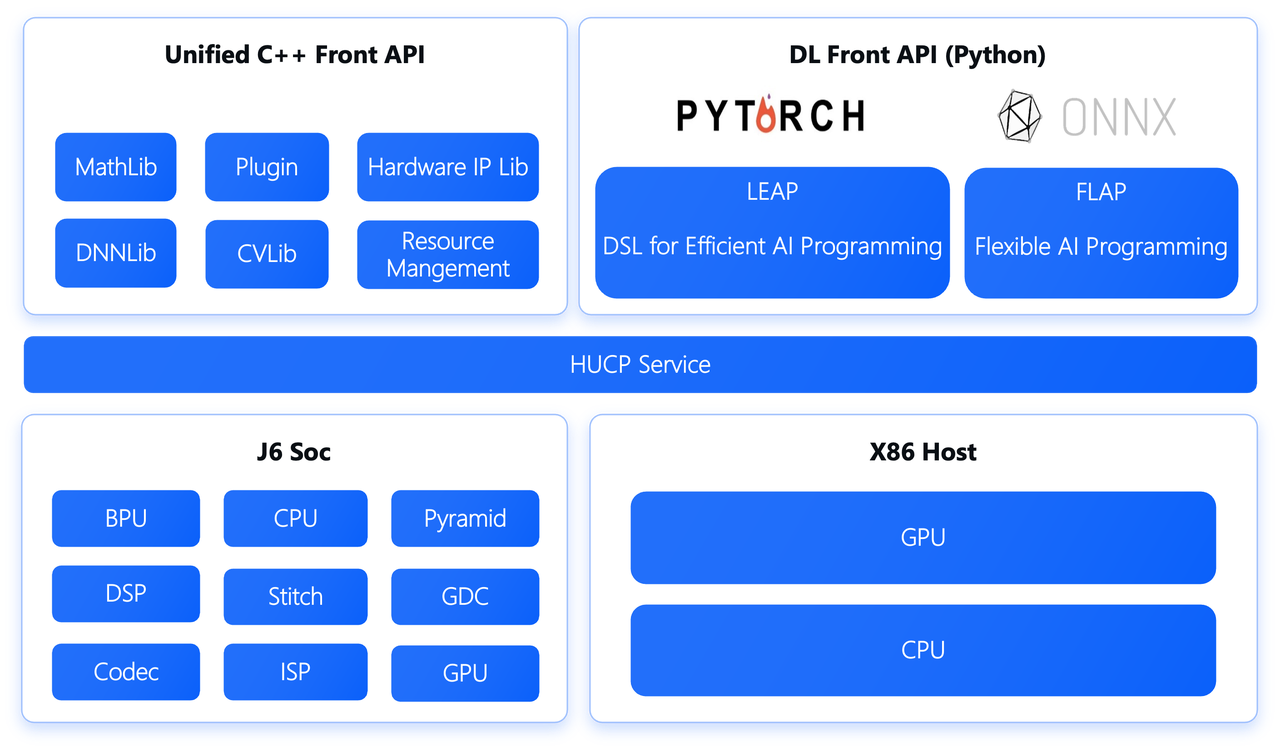
## 3.2 新框架特性
HUCP是对原先 J5 的 DNN 预测库进行了功能和边界的扩展,旨在提供计算图全图(视频通路 + 前/后处理 + 多模型串街 + 自定义计算)表达的能力,并支持将全图一起送入下游编译。具体包含以下特性:- HUCP Service 架在整个 J6 SoC 上,在 BPU、CPU、DSP 的基础之上,又扩展封装了 Pyramid、GDC、Stitch、Codec 等视频通路上的硬件 IP(不包含非计算的 camera 接入部分),并提供了 J6 SoC 和 x86 Host 端统一的 C++ 前端调用 API。以 Pyramid 为例,其实现完全参考了 SoC 上的 reference C,所以即使在 x86 端没有对应的硬件 IP 加速,也能在数值上保证一致性;
- 新增数学计算库(FFT、BLAS等)、CV 库等的封装;
支持自定义算子(Plugin);
提供资源管理、调度控制(J6 支持三级调度)相关的 API 接口;
- 支持 x86 平台 GPU 环境下模型算子级别的仿真。
基于以上新框架能力 和 仿真功能加持,算法同学能够在 x86 环境下快速、便捷地完成原型验证、回灌仿真等工作,节约大量算法/工程对齐的开销,后续也能丝滑地迁移至 SoC 环境(只需替换模型文件,基于交叉编译工具重新编译工程即可),从而极大地提升了生产开发效率。当然,在最后的实车部署阶段,还是需要依赖工程的深度优化(Neon 加速等),依然会涉及对齐等工作。
# 4. 与J5相比部署差异
到目前为止,地平线工具链套件已经历多代芯片计算平台的检验,尽管每个代芯片的工具链套件的版本都是独立迭代的,但它们无论在设计模式,还是在技术实现上都在考虑硬件构成差异后进行相互间的思想借鉴,在用户侧,工具链套件的使用是一脉相承的,如果用户曾经使用对地平线前一代计算平台下工具链套,那么在J6计算平台使用工具链套件则是一件很EASY的事情,用户只需要注意J6计算平对相对上一代平台有哪些差异,对应到部署如何在落地代码上加以区分和实施即可。部署时,J6计算平台与J5计算平台相比存在以下变动点,需要特别注意:
## 4.1 Batch拆分- 对于 batch>1 的 Pyramid/Resizer(nv12) 输入节点,请参考上文进行 batch 维度的拆分,并使用独立地址部署;
- 对于 batch>1 的 ddr 输入节点,支持使用连续地址部署。
4.2 NV12输入
J6 默认 nv12 hbm 输入数据的 tensorType 为 HB_DNN_IMG_TYPE_NV12,如果需要复用 J5 的代码,Y 和 UV 使用两个地址传入,可以手动修改 tensorType 类型为 HB_DNN_IMG_TYPE_NV12_SEPARATE。示例如下:注:HB_DNN_IMG_TYPE_NV12和HB_DNN_IMG_TYPE_NV12_SEPARATE两种 tensorType 支持互转,执行效率无差异4.3 Layout适配
- J3/J5:为四维的输入输出节点提供了有效的 layout 值(非四维节点的 layout 无意义)
- J6:为了全面兼容四维和非四维场景,layout 的概念被弱化:
per_channel 量化模型会提供 quantizeAxis 信息(即量化轴),在一定程度上可以起到类似 layout 的作用
非 per_channel 量化模型所提供的 layout 信息,无论是否有值均无意义
4.4 输入输出对齐
- 输入节点
featuremap 输入时,模型中保留量化节点则 runtime 会做输入数据的 padding,删去量化节点则需要用户自行做 padding(和J5一致) - 输出节点
无论模型输出节点是 CPU 算子还是 BPU 算子,都需要用户在后处理自行 remove padding(可根据 valid shape 和 stride 计算需要 remove 的区域)
stride 可以简单理解为,某个维度的数,代表输出 shape 对应维度的值 +1 时,在内存上需要跳过的字节大小,以下方输出节点为例:
- stride[2] - valid_shape[3] = 64 - 28 = 36
表明 shape 的最后一维 padding 了 36 个字节大小
- stride[1] / stride[2] = 2048 / 64 = 32 = valid_shape[2]
stride[0] / stride[1] = 65536 / 2048 = 32 = valid_shape[1]
表明其他维度均不存在 padding
所以用户在编写 remove padding 代码时,仅需将最后一维下标 28~63 的值略去即可
- 注意:由于 J6 和 J5 的硬件对齐规则存在差异,所以 align_shape/ stride 会和 J5 不同,不能完全复用;虽然当前版本还会提供 aligned_shape(后续可能被废弃),并且大多数与 stride 计算结果相同,但并不保证总是准确,所以请以 stride 计算结果为准。
5. 部署常用工具
类别 | 工具名称 | 功能描述 | 使用说明 | 注意事项 |
|---|---|---|---|---|
通用工具 | uname -a | 查看当前系统版本 | 重点是镜像时间和平台架构 | 一般用于问题排查是版本对齐 |
top、htop | 查看进程对CPU、内存的占用率 | 多线程工程可以为每个线程设置不同名称然后HTOP查看 | 查看系统运行状态 | |
专用工具 | hrut_somstatus | 查看当前开发板的BPU使用率 | 多线程工程可以为每个线程设置不同名称然后HTOP查看 | 查看系统运行状态 |
hrt_model_exec | 评测模型的性能、获取模型信息等 | 参考用户使用手册 | 在开发板或仿真平台上都可以使用,需要注意的是环境变量PATH需要包含工具的位置。另外动态链接版本还需要配置LD_LIBRARY_PATH环境变量已包含工具所需的动态库文件 | |
dmesg | 查看系统日志 | 多线程工程可以为每个线程设置不同名称然后HTOP查看 | ||
UCP trace | 分析 UCP 应用程序对各个硬件IP的调度逻辑 | 参考用户使用手册 | 通过设置环境变量后通过脚本启动日志抓取和分析工具 | |
hrt_ucp_monitor | 监控硬件 IP 占用率的工具 | 参考用户使用手册 | 可以看做是top、htop、hrut_somstatus等常规工具的整合 | |
hb_verifier | 进行onnx模型之间、onnx模型与hbir模型之间的对比 | 参考用户使用手册 | 进行模型逐层算子输出余弦相似度对比 |
类别 | 工具名称 | 功能描述 | 使用说明 | 注意事项 |
|---|---|---|---|---|
通用工具 | uname -a | 重点是镜像时间和平台架构 | 重点是镜像时间和平台架构 | 一般用于问题排查是版本对齐 |
top、htop | 查看进程对CPU、内存的占用率 | 多线程工程可以为每个线程设置不同名称然后HTOP查看 | 查看系统运行状态 | |
dmesg | 查看系统日志 | 无法从应用日志查看到问题时可以尝试 | ||
专用工具 | hrut_somstatus | 查看当前开发板的BPU使用率 | 参考用户使用手册 | |
hrt_model_exec | 评测模型的性能、获取模型信息等 | 参考用户使用手册 | 在开发板或仿真平台上都可以使用,需要注意的是环境变量PATH需要包含工具的位置。另外动态链接版本还需要配置LD_LIBRARY_PATH环境变量已包含工具所需的动态库文件 | |
UCP trace | 分析 UCP 应用程序对各个硬件IP的调度逻辑 | 参考用户使用手册 | 通过设置环境变量后通过脚本启动日志抓取和分析工具 | |
hrt_ucp_monitor | 监控硬件 IP 占用率的工具 | 参考用户使用手册 | 可以看做是top、htop、hrut_somstatus等常规工具的整合 | |
hb_verifier | 进行onnx模型之间、onnx模型与hbir模型之间的对比 | 参考用户使用手册 | 进行模型逐层算子输出余弦相似度对比 |
6. 可能遇到的问题
- Q: HUCP 里面对于不同硬件间的数据内存是如何管理的?视频通路里的 online 如何实现?
在 HUCP 中存在不同架构的硬件 IP,算子调用或模型推理都会涉及到数据的创建,传递,访问和释放。为了屏蔽不同架构内存模型的不同,提供了一套统一的内存管理接口,负责内存的分配,释放,刷新,属性查询,内存共享等功能。通过统一的内存管理接口,可以实现不同硬件 IP 之间数据的零拷贝传递,满足数据在不同硬件 IP之间的流转。申请的内存可分为 cacheable 和非 cacheable 两种,对于 cpu 读写的 cacheable 内存, 需要读之前或者写之后刷新一下缓冲。同时考虑到 PAC 卡的场景需要支持 Host/Device 模式的内存管理,对于板端和 x86 仿真场景下不区分 Host/Device 模式,申请的 Host/Device 均可用于算子调用或者模型推理,而 PAC 卡场景下 pc 端需要申请 Host 内存,PAC 卡端申请 device 内存,借助提供的接口做 host 和 device 之间的内存拷贝,但是不支持 device 之间的内存拷贝。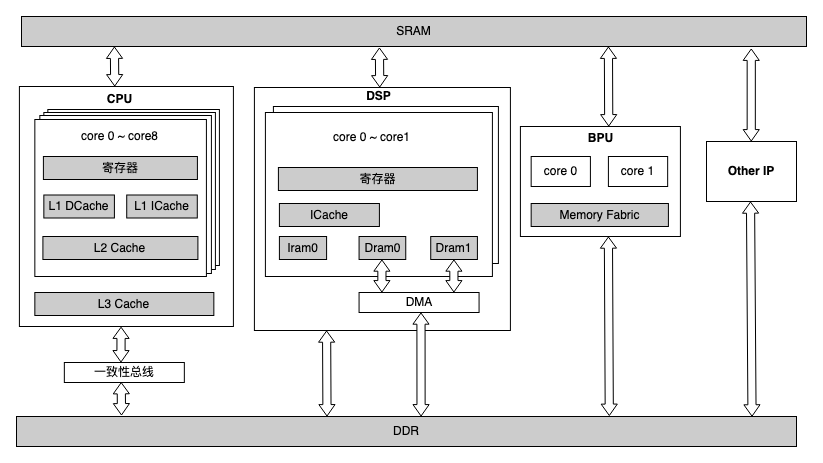
- Q: HUCP整合了原J5上的多个接口后形成了一个完整的API大表,是否能覆盖原先所有的系统软件接口
A: 会有一定的裁剪,裁剪的标准是能简化地满足用户 90% 的主要功能

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)