
打哈欠检测的挑战
在驾驶员监控系统中,实时检测驾驶疲劳对于预防事故至关重要,而准确检测打哈欠是识别疲劳驾驶的重要手段。疲劳驾驶是全球道路事故的主要原因:超过71%的司机承认每周至少有一次疲劳驾驶。实时检测驾驶疲劳对于预防事故至关重要。在疲劳特征中,打哈欠是常见迹象,可作为衡量驾驶员疲劳程度(主要是早期水平)的标准。
传统方法无法很好处理实际的实时需求和长程情况,例如当被检测人捂嘴打哈欠或是侧着脸打哈欠行为(如图1所示的打哈欠帧序列),很难被传统方法检测出。此外,它们在弱光和强光条件下的稳健性不佳,如在隧道和户外阳光下。

YawnNet 是一种基于视觉的打哈欠检测系统,主要利用深度学习技术,整体效果显著:
我们使用ViT作为主干,并利用立方体em-beding和Swin transformer block进行时空特征提取。我们还应用迁移学习和顺序学习技术来简化训练过程,提高YawnNet掌握打哈欠行为时空特征的能力。与最先进的方法相比,它具有优越的性能,在长程情况下也具有显著的鲁棒性。也可将其轻量化后移植到征程五代,达到高精确性和实时性。
技术实现
图2显示了YawnNet的总体流程。在数据预处理阶段,我们使用基于YOLOv5的深度神经网络进行面部检测和提取。由于打哈欠通常持续3-6秒,并且涉及一长串帧,我们使用随机帧方法来更有效地训练模型。它需要从原始视频中随机提取帧,以获得由64帧组成的压缩视频片段,然后使用步长为4的时间下采样将其进一步压缩为16帧。在检测阶段,我们使用ViT作为主干。224×224分辨率的图像最初被处理并分割成尺寸为16×16的视觉像素块。然后通过块嵌入将每个像素块转换为高维特征。然后,像素块被输入到编码器用于特征提取,并且输出762维的结果被用作线性分类器的输入以获得分类结果。在这里,我们详细介绍了两种主要的哈欠检测策略:立方体嵌入和Swin Transformer Block。
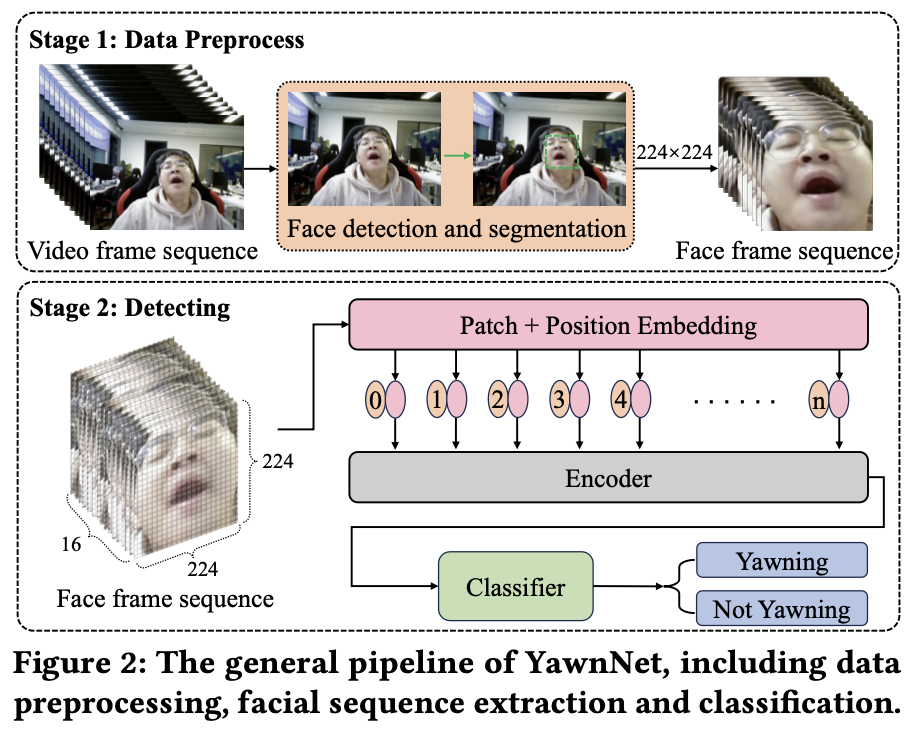
立方体嵌入
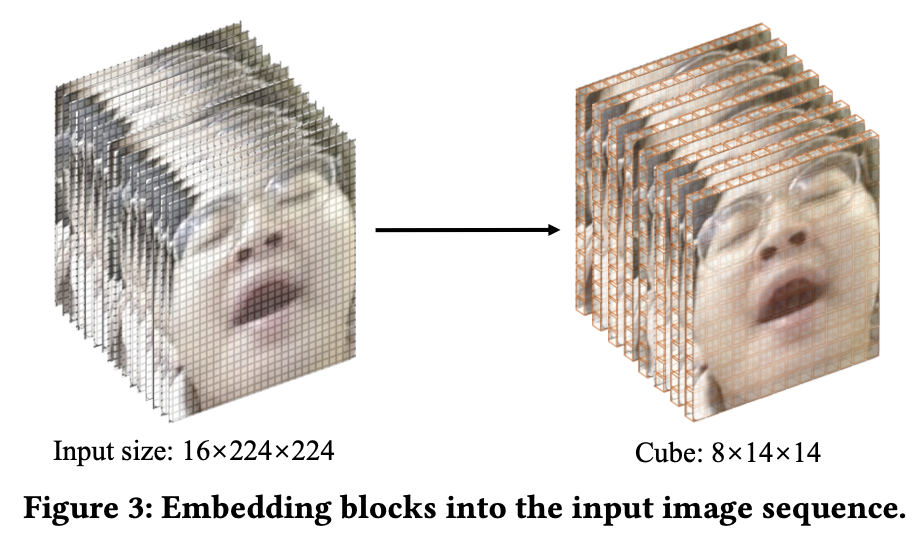
为了对数据中的时空关系进行编码,我们对输入图像使用联合时空立方体嵌入。如图3所示,它包括嵌入一个大小为2×16×16的立方体作为单个单元。为了实现这一点,将原来的16×224×224的大立方体划分为8×14×14的小立方体,并嵌入到低通道维度D中,作为后续层的输入。
Swin-Transformer
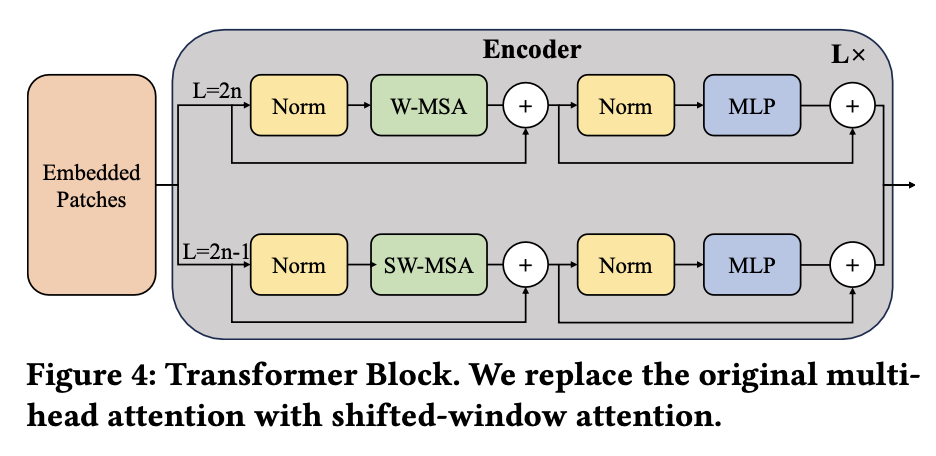
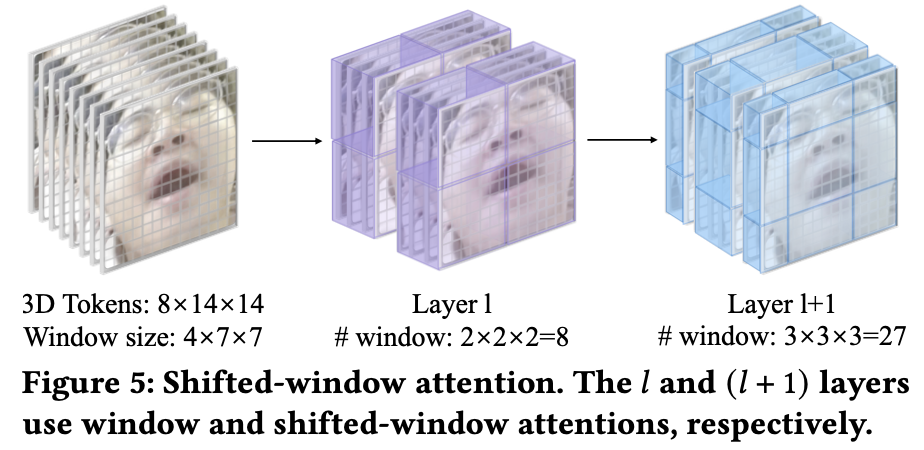
为了更有效地提取像素块中的高级时空信息,我们实现了Swin Transformer块,如图4所示。Swin-Transformer块包括win-dow多头自注意和移位窗口多头自注意,如图5所示。因此,Swin变压器的层数应为2的整数倍,偶数层提供给W-MSA,奇数层提供给SW-MSA。在此基础上,YawnNet可以更有效地捕捉不同尺度图像中的信息。
损失函数
为了更好地将模型用于迁移学习,并在减轻过拟合的同时增强其泛化能力,我们的损失函数使用了Lstce。
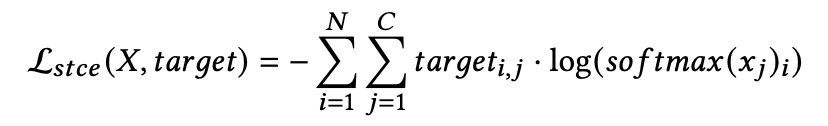
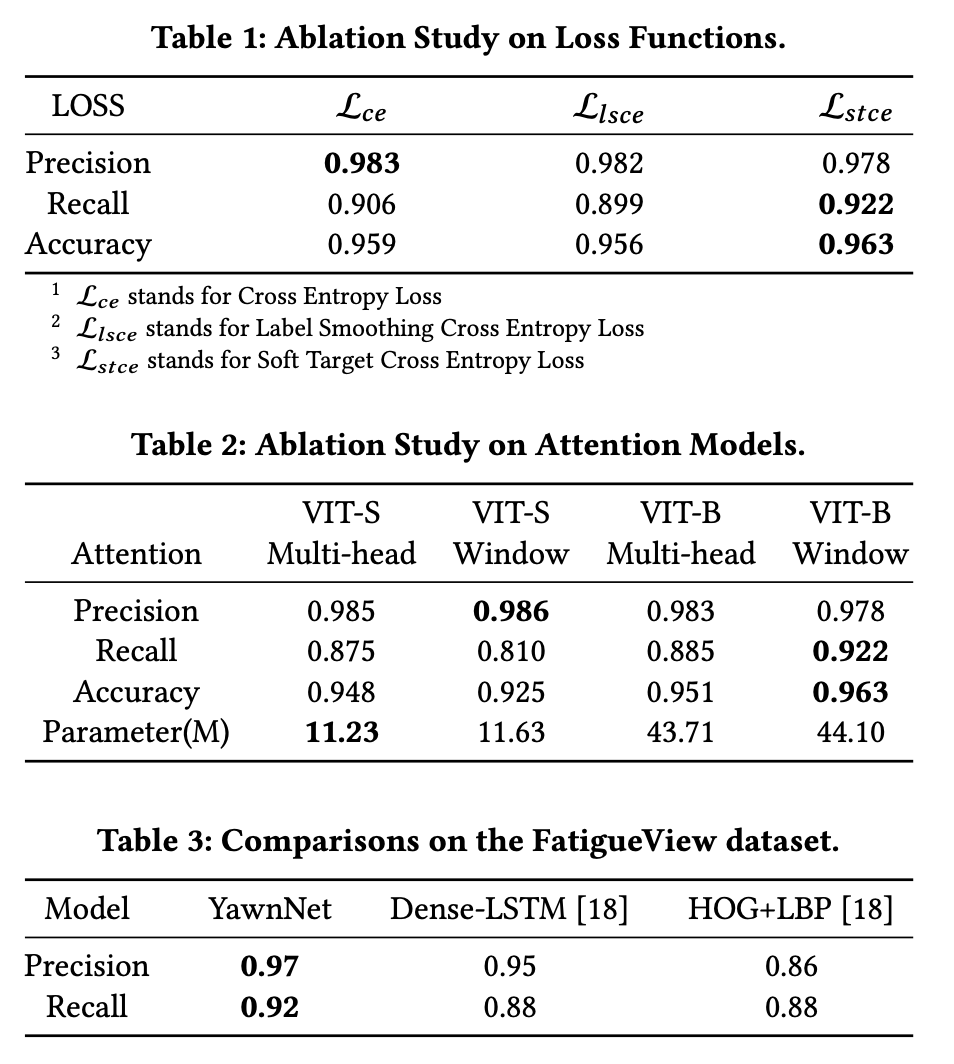
实验结果
在多个公开数据集上的实验表明,YawnNet精确度高,并且在实时性和鲁棒性方面均优于现有方法。
结论
YawnNet是一种简单而有效的打哈欠检测方法,用于在驾驶场景中检测哈欠。与一般的基于CNN的方法和一般的阈值方法不同,YawnNet采用ViT作为骨干,利用块嵌入部分和SW-MSA方法进行时空特征提取。实验表明,YawnNet在现有的开源数据集上是稳健且高度准确的。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)