
VRSO: Visual-Centric Reconstruction for Static Object Annotation
静态物体检测(Static Object Detection,SOD)涉及识别交通信号灯、导向牌和交通锥等静态交通标示物。目前,大多数算法依赖于数据驱动的深度神经网络,并且需要大量的训练数据。传统的方法通常涉及在激光雷达(LIDAR)扫描的点云数据上手动标注大量训练样本,以解决较为罕见的情况。
然而,手动标注存在许多挑战,难以捕捉真实场景的变异性和复杂性,常常无法考虑到遮挡情况、不同光照条件和多样的视角(如图1所示的黄色箭头)。整个标注过程冗长、耗时且容易出错,造成相当高的成本(如图2所示)。因此,目前许多公司都在寻求自动标注解决方案,特别是基于纯视觉的方法,因为并非每辆车都装备有激光雷达。
VRSO的出现可以提升标注的效率和准确性,降低标注成本,同时还可以应对真实环境中的复杂场景和挑战。通过研究和引入自动标注技术,我们可以更好地应对静态物体检测任务中的标注困难,推动相关技术的进步并促进应用的发展。


VRSO 是一种以视觉为主、面向静态对象标注的标注系统,它主要利用了SFM、2D 物体检测和实例分割结果的信息。整体而言,VRSO 的效果如下:
平均投影误差仅为 2.6 像素,大约是 Waymo 标注误差的四分之一(10.6 像素)
与人工标注相比,速度提高了约 16 倍
对于静态物体,VRSO 通过实例分割和轮廓提取关键点的方式,克服了从不同视角综合和去重静态对象的挑战,同时解决了由于遮挡问题导致的观察不足困难,从而提高了标注的准确性。如图1所示,与 Waymo Open Dataset的手动标注结果相比,VRSO 展现出更高的鲁棒性和几何精度。
VRSO 的应用为静态对象标注领域带来了重要的技术突破,为提高标注效率和准确性提供了新的解决方案。通过结合视觉信息和先进算法,VRSO 在静态对象标注任务中展现出了出色的性能,为相关领域的发展和应用提供了有力支持。
算法介绍
VRSO系统主要分为两部分:场景重建和静态对象标注。

场景重建通过使用COLMAP结构光扫描法对驾驶场景进行重建,并定制化以适配驾驶场景。利用周围的所有摄像头来重建SfM模型。为了改善静态物体重建性能,采用了SuperPoint特征点提取器,该提取器在专注于引导板、交通信号灯和交通锥的采样数据集上进行训练。采样策略基于原始图像的2D分割结果。场景重建部分提供准确的车辆自我姿态和稀疏的三维特征关键点,以供进一步的静态物体注释算法使用。
静态对象标注算法,配合伪代码,大致流程是:
采用现成的2D物体检测和分割算法生成候选
利用 SFM 模型中的 3D-2D 关键点对应关系来跟踪跨帧的 2D 实例
引入重投影一致性来优化静态对象的3D注释参数
1.关联
从 SfM 模型中提取关键点,并筛选出位于3D边界框内的关键点,用于确定相应的3D点。
根据2D-3D匹配关系,在2D地图上计算每个3D点的投影坐标。
结合实例分割的角点信息,确定每个2D地图上的3D点对应的实例对象。
确定每个2D图像中2D观测到的位置与相应3D边界框之间的映射关系。
2.proposal 生成
在这一步骤中,为整个视频片段的静态物体初始化了3D边界框的参数(位置、方向、尺寸),这些参数可后续进行调整。通过利用SfM模型中的3D关键点作为中间步骤,可以从2D图像中恢复静态物体的3D参数。每个2D实例中的特征点可以形成对应的3D关键点集,作为3D边界框的proposal。不同类型的静态物体(如引导板、交通信号灯、交通锥)采用不同的表示方式和自由度,如方向、尺寸等。这一步骤为后续静态物体标注算法提供了初始信息。
3.proposal refinement
通过2D实例分割提取静态物体的轮廓。
使用轮廓拟合最小定向边界框(OBB)。
提取最小边界框的顶点。
根据顶点和中心点计算方向,并确定顶点的顺序。
由于3D关键点聚类生成的最小边界框可能存在不准确性,因此根据2D检测和实例分割结果进行分割和合并。
检测并排除有遮挡的观测结果。提取2D实例分割蒙版中的顶点时,需要确保每个标牌的四个角可见。由于遮挡,这一要求并不总是能够满足,因此需要采取额外步骤来检测并排除这些情况。通过提取轴对齐边界框(AABB)并计算AABB和2D检测框的面积比,来检测遮挡情况。设定一个阈值0.95用于检测遮挡案例。
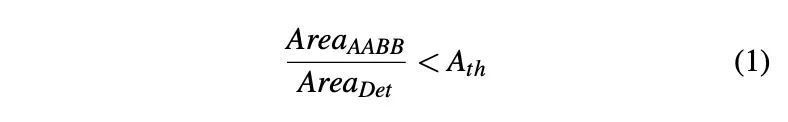
4.三角化
三角测量用于在3D条件下获取静态物体初步顶点值。只考虑关键点数量超过阈值的实例作为稳定有效观测。通过2D观测结果,对边界框顶点进行三角测量获得坐标,从而轻松计算位置、方向、大小参数。对于圆形标牌,由于没有区分“左下、左上、右上、右上、右下”顶点,因此使用2D检测结果和实例分割蒙版提取轮廓,计算中心点和半径。参数包括中心点(?、?、?)、方向(θ)和半径(?)。
5.tracking refinement
VRSO中的追踪基于SfM模型中的特征点匹配。当实例的特征点不足时,可能导致追踪不可靠,同一实例可能有多个追踪ID,降低了标注准确性。根据3D边界框顶点的距离和2D边界框投影的重叠度,决定是否合并分离的实例。合并后,可以收集实例内的3D特征点来关联更多的2D特征点,这一过程在无法添加新的2D特征点时终止。
6.最终参数优化
通过最小化残差投影误差来调整标注参数。以矩形标牌为例,可优化的参数包括位置(?、?、?)、方向(θ)和大小(?、ℎ),共六个自由度。主要步骤包括:
将六个自由度转换为四个3D点,并计算旋转矩阵。
将转换后的四个3D点投影到2D图像上。
计算投影结果与实例分割边角点结果之间的残差。
使用Ceres solvers中的Huber loss更新边界框参数,以减少离群值对优化结果的影响。
经过优化后,可以最小化残差值,获得更准确的标注结果。基于此,图像中矩形边界框的投影位置可更接近实际观察到的矩形边界框位置,从而提高边界框的准确性。
7.算法伪代码

标注效果

绿色框和红色框分别是来自VRSO和WOD的注释。我们可以发现,即使在低光照条件下,我们所提出的VRSO的注释也比WOD更准确地定位目标。
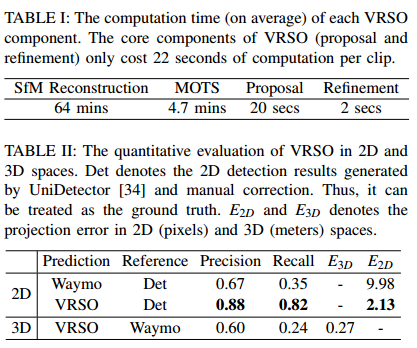
从表1可看出VRSO的核心组件(提议和改进)每个片段仅花费22秒的计算时间,速度很快。
表2是VRSO在二维和三维空间的定量评价。Det表示UniDetector生成的二维检测结果和人工校正。因此,它可以被视为基础真理。E2D和E3D表示2D(像素)和3D(米)空间的投影误差。可见VRSO有更高的准确率和召回率。
也有一些具有挑战性的长尾案例,例如极低的分辨率和照明不足。

总结
VRSO是一种新框架,用于实现静态对象的高精度、一致性三维标注。它将检测、分割和SfM算法融合在一起,解决了智能驾驶自动标注系统中的集成挑战。VRSO消除了人工干预注释的需求,其结果与手动注释相当。通过在Waymo开放数据集上进行评估,结果表明VRSO比人类注释速度快16倍,并且保持了出色的一致性和准确性。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)