
该文章在首发于微信公众号:自动驾驶之星 https://mp.weixin.qq.com/s/KM5qc13B8bPI9Qd4lgSfXA,在此仅做技术分享和同步
1. 摘要
基于 BEV 的方法在多视角 3D 检测任务上很流行,性能较强。基于稀疏融合的方法在性能上优劣势,但仍然有很大的潜力。本文所提出的 Sparse4D 的方法通过 Sparse 采样、融合时空特征的手段迭代式的 refine anchor box。
Sparse 4D Sampling (稀疏4D 采样) 对于每个 3D anchor,分配多个 4D 关键点,投影到多视角/多尺度/多帧的图像特征上采样相关的特征。
Hierarchy Feature Fusion(层次特征融合): 有层次地将 不同视角/不同尺度/不同帧/不同关键点 的特征进行融合,以生成高质量的实例特征 通过这种方式,Sparse4D 能够不依赖 Dense 的视角转换以及全局注意力,对边缘设备的部署更加友好。此外,本文引入了实例级别的 Depth Reweight 模块来缓解 3D-to-2D 投影的不适定问题。实验上,Sparse4D 在 nuScenes 数据集上的性能超过了所有的 Sparse-based 方法以及大部分 BEV-based 方法。
2. 论文的目的、贡献及结论
该论文希望探索 Sparse-based 方法在 多视角+时序(4D 输入)下进行 3D 检测任务的可行性。
首个引入时序的 Sparse-based 3D 检测方法。
提出4D 信息聚合模块,可以完成多维度(多帧、多视角、多尺度、多位置)特征的融合;引入 Depth Reweight 模块提升性能。
nuScenes 数据上性能不错。
3. 论文的实验
在 nuScenes 数据集上做实验
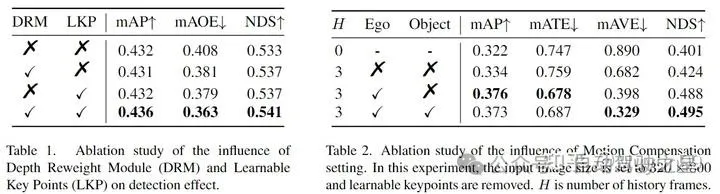
Table 1 是消融实验,DRM 模块和 LKP 各自有增益,结合使用也有增益。
Table 2:生成 4D 关键点时,同时考虑了车辆本身的运动(Ego)和物体的运动(Object)。时间窗口的长度选择 3 进行实验。没有运动信息,单加入时序可以提点;加入运动信息后,有明显的性能增益。在 Ego 的基础上加入 Object 运动信息会更好。
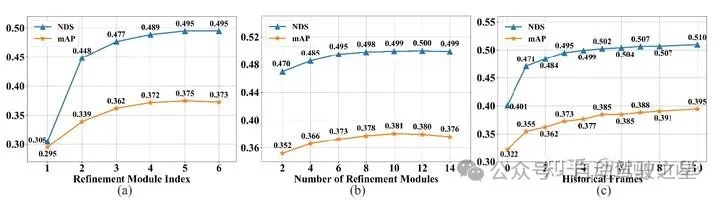
Refinement Module 的堆叠方式是有效的,能够渐进地 refine 3D box。
Refinement Module 并不是越多越好,加的过多还会掉点。
时间窗口越大,边际效益越明显,加入太早的帧意义不大。
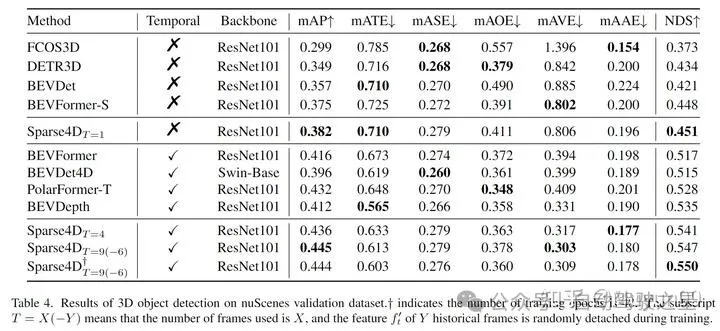
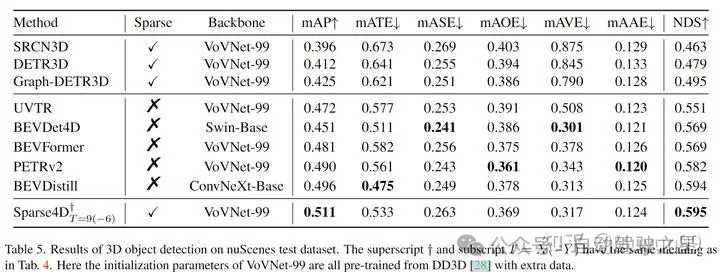
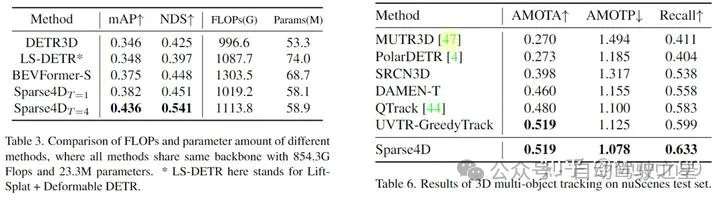
Table 3~5:性能、参数、计算量的对比中,Sparse4D 做到了把比较好的 Tradeoff,在性能较高的同时保持较小的模型规模和较少的计算代价。
Table 6:拓展到 3D 多目标跟踪任务上,使用简单的匈牙利匹配算法,性能上仍然出色,表明检测结果的可靠。
4. 论文的方法
4.1 简介及相关工作简述
没有深度信息,基于 2D 图像做 3D 感知任务(如 3D 目标检测)是 ill-posed issue(不适定问题), 适定问题是指定解满足下面三个要求的问题:① 解是存在的;② 解是唯一的;③ 解连续依赖于定解条件,即解是稳定的。这三个要求中,只要有一个不满足,则称之为不适定问题。如图像去噪,图像恢复,图像修补,图像去马赛克,图像超分辨率等问题。
3D 检测基本有两种思路,BEV-based 和 Sparse-based。
1. BEV-based 方法将多视角图像的特征转到统一的 BEV 空间下,性能已经被很多工作证实过很优秀。但存在三个遗留问题:
相关工作:BEVFormer,BEVDet,BEVDepth,BEVStereo,SOLOFusion。
image-to-BEV 的视角转换以来 Dense 的特征采样,计算复杂度高。
最大感知范围受限于 BEV 特征图的尺寸,而大尺寸又会带来大的计算开销。
高度维度在 BEV 方法中被压缩,存在信息损失。所以不能做标志牌检测等任务。
2. Sparse-based 方法不需要 Dense 的特征转换,直接采样 Sparse 的特征做 3D anchor 的 refine,能够避免以上问题。
相关工作:DETR,Deformable DETR,Sparse R-CNN,MoNoDETR,DETR3D,Sparse R-CNN3D,SimMOD,SRCN3D,PETR, Graph-DETR3D。
最有代表性的 Sparse 3D 检测方法是 DETR3D,但该方法对每个 anchor query 的 单个 3D reference point,只采样特征一次,模型容量是受限的。
SRCN3D 利用 RoI-Align 来采样多视角的特征,但其效率不高,对不同视角的特征点也不能精确地对齐。
现有的 Sparse-based 方法没有充分利用时序信息,与 BEV-based 方法存在性能上的差距。
3. Sparse4D 概述
通过引入 4D 关键点即可简单扩展到利用时序信息,可以有效地对齐时间信息。
能够提取每个 anchor box 的上下文信息,且效率较高。每个关键点的上下文信息包括多视角、多尺寸、多帧,Sparse4D 能够层次化地充分融合,为 3D anchor 的 refinement 提供了高质量的实例特征。
添加了实例级别的 Depth Reweight 模块作为显式监督,其中实例特征通过从预测的深度分布中采样的深度置信度重新加权。该模块以 Sparse 的方式进行训练,无需额外的 Lidar 点云的监督。
4.2 总体框架
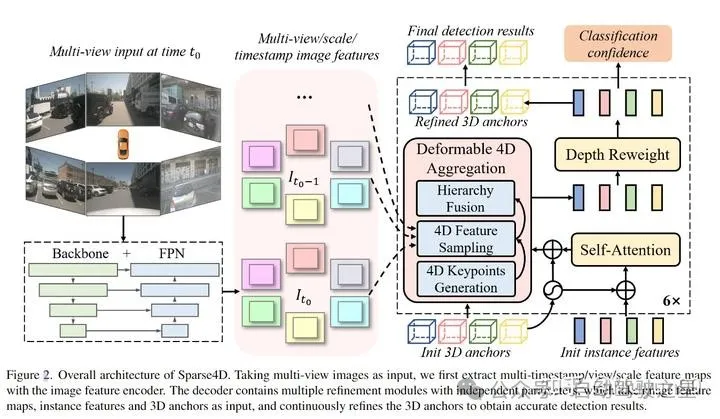
给定在 t 时刻的 N 视角图像、先过 Backbone + Neck(FPN)得到 Multi-scale + Multi-view 的Feature;为了做时序融合,特征队列中还有前面 T 帧的特征。
后面接六个堆叠的 Refinement Module,每个 Refinement Module 包含三个小模块。
4.3 Deformable 4D Aggregation 模块(3.2 小节)
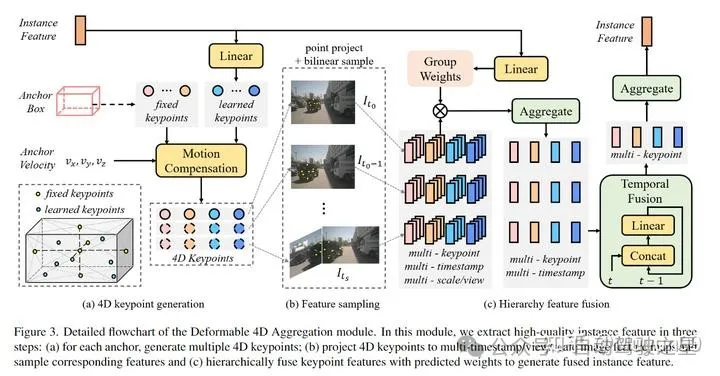
模块操作如下:
对送入的 3D anchor(最初的 Anchor 是聚类得到的,后续堆叠的模块使用 Refine 后的 3D anchor),进行 4D 关键点的生成。关键点分为 fixed 关键点以及 learned 关键点,learned 关键点是通过实例特征经过 Linear 层得到的。
将 4D 关键点投影到时间窗口内的特征上,进行 4D 特征采样,采样方式是 Bilinear Sample(双线性采样),采样是 Sparse 的。
采样后的特征做特征融合。通过上一轮的 Feature 生成 权重做 multi-scale/view 的融合;通过不断和前一帧的 Concat + Linear 操作进行时序特征融合(用自车运动信息进行坐标系的转换);再将多个关键点的特征求和,聚合成实例特征。
该模块作用:将特征进行多维度、层次化的聚合。
4.4 Depth Reweight 模块(3.3 小节)
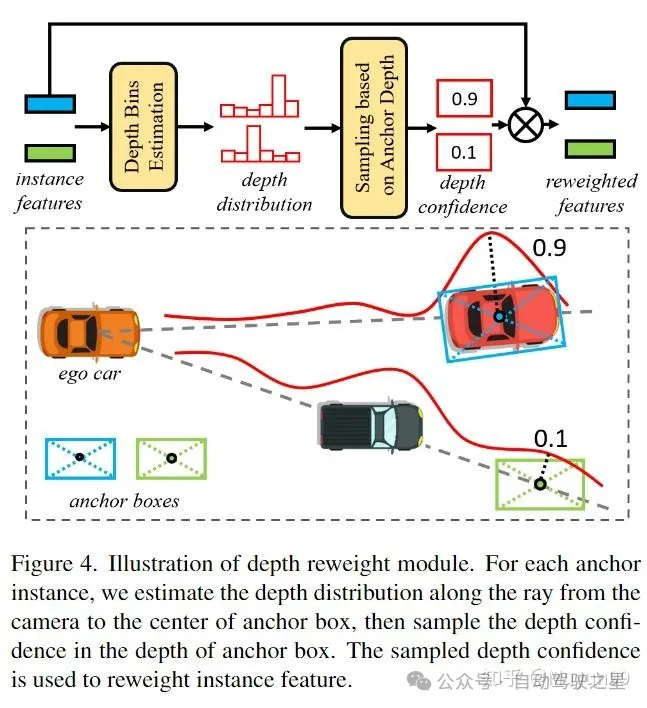
模块操作:该模块的结构就是多层的 MLP,用于估计深度分布。得到每个 3D anchor 中心点的 Depth Confidence,用将 Confidence 对实例特征进行加权。Anchor 的格式为:{x, y, z, ln w, ln h, ln l,sin yaw, cos yaw, vx, vy, vz},都在同一个坐标系下。
该模块的作用:加入显式的深度监督,为了加速拟合。
4.5 Self-Attention 模块
模块操作:将实例特征(最初的实例特征是随机初始化,后续堆叠的模块使用 Refine 后的 实例特征)和 Anchor Embedding 相加之后 做 Self-Attention,做完 Self-Attention 之后再和 Anchor Embedding 相加送入特征聚合模块。
模块作用:实例特征和 Anchor Embedding 之间的交互。
5. 文章评价
Sparse4D 性能不错,并且端上部署友好,推动了 Sparse-basd 方法的落地,有望成为 Sparse-based 方法的 Baseline。作者也给出了一些进一步提升性能的点:Multi-view stereo(多视角立体视觉)以获得更精确的 Depth,相机参数的编码等等。作者自己已经迭代出一版 Sparse4Dv2 并且已经开源,总的来讲,这篇工作及其后续是值得关注的。在端上落地 BEV 范式其实没那么友好,检测范围广,BEV 就得大;检测精度好,格子就得细;Sparse 这个感知的范式也值得进一步挖掘。



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)