
由于LaneAF全bpu算子,因此 采用 fx模式 + 非异构方案 做 量化训练
基本知识
fx量化接口常用的函数
- wrap() --- utils.fx_helper.wrap接口
- 如果模型中使用到了FX不支持的操作,可以用wrap的方式将其作为一个函数或者方法包装为一个整体。fx 将不再关注他们内部的逻辑,而是将对他们的调用原样保留。 warp方法的使用样例
- fuse_fx()
传入 float model,自动做算子融合,如 conv+add+bn+relu 等。
- 算子融合的规则定义在 horizon_plugin_pytorch/quantization/fx/fusion_patterns.py 里
- prepare_qat_fx()
将浮点模型转为一个可以进行量化感知训练的Prepare模型
集成了自动化fuse流程,可以省略 fuse_fx() 操作。
qconfig_dict 用来设置量化规则
- convert_fx()
将 qat模型转换为定点模型。
基础流程
对 主模型插入 量化和反量化节点。
正常训练一个浮点模型,得到 best_float.pth
float_model 加载预训练权重。
model.load_state_dict(torch.load("best_float.pth"), strict=True)
设置 march
set_march(March.BAYES)
将 float_model 使用 prepare_qat_fx() 转换为一个可以进行量化感知训练的 prepare model
Config 推荐使用默认的 get_default_qat_qconfig()
"module_name"用来设置模型的高精度输出,一般将模型尾部的conv算子设置为高精度输出。可以print(float_model) 查看一下尾部结构,定位需要高精度输出的算子。
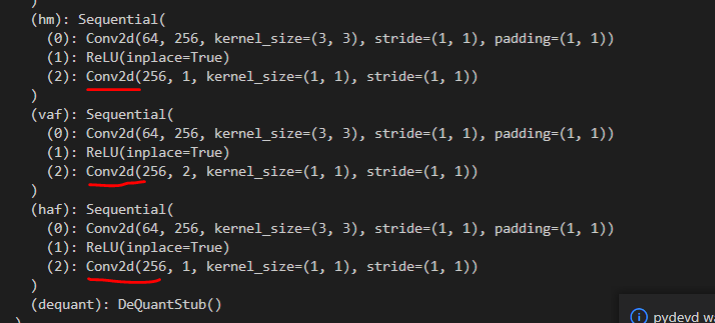
得到 qat_model 后,就可以做量化感知训练了
与float 训练不同,量化感知训练有对应的策略。
我的经验:LR不能设置过大,loss容易爆炸;
一般 Epoch 1/2 的精度已经可以看出来量化训练的好坏了
如果 adam 优化器 loss 难收敛,强烈推荐使用 SGD !
加载训练好的qat模型权重 qat_best.pth,测评qat模型精度。
如果 qat模型 的精度和 浮点模型精度很接近,可以不做校验操作。
我的 float精度:0.95133 qat模型精度:0.95148
否则,需要在 步骤5 之前做 prepare_calibration_fx()
将 qat模型转为定点模型,并验证定点模型的精度
定点模型的精度和qat模型的精度基本一致
模型编译
输出产物:
model.hbm
model.hbir
model.pt
板端性能测评:
latency: 5.603636 ms
fps:368.892750 FPS
踩坑记录
很多torch.xx操作的算子,在准备浮点模型时需要替换掉,
否则可能出现维度不匹配的错误,如:

FloatFunctional()函数不能多次调用,报的也是维度错误的error

不过可以在graph_module.py里,用traceback.print_exc() 捕获异常信息
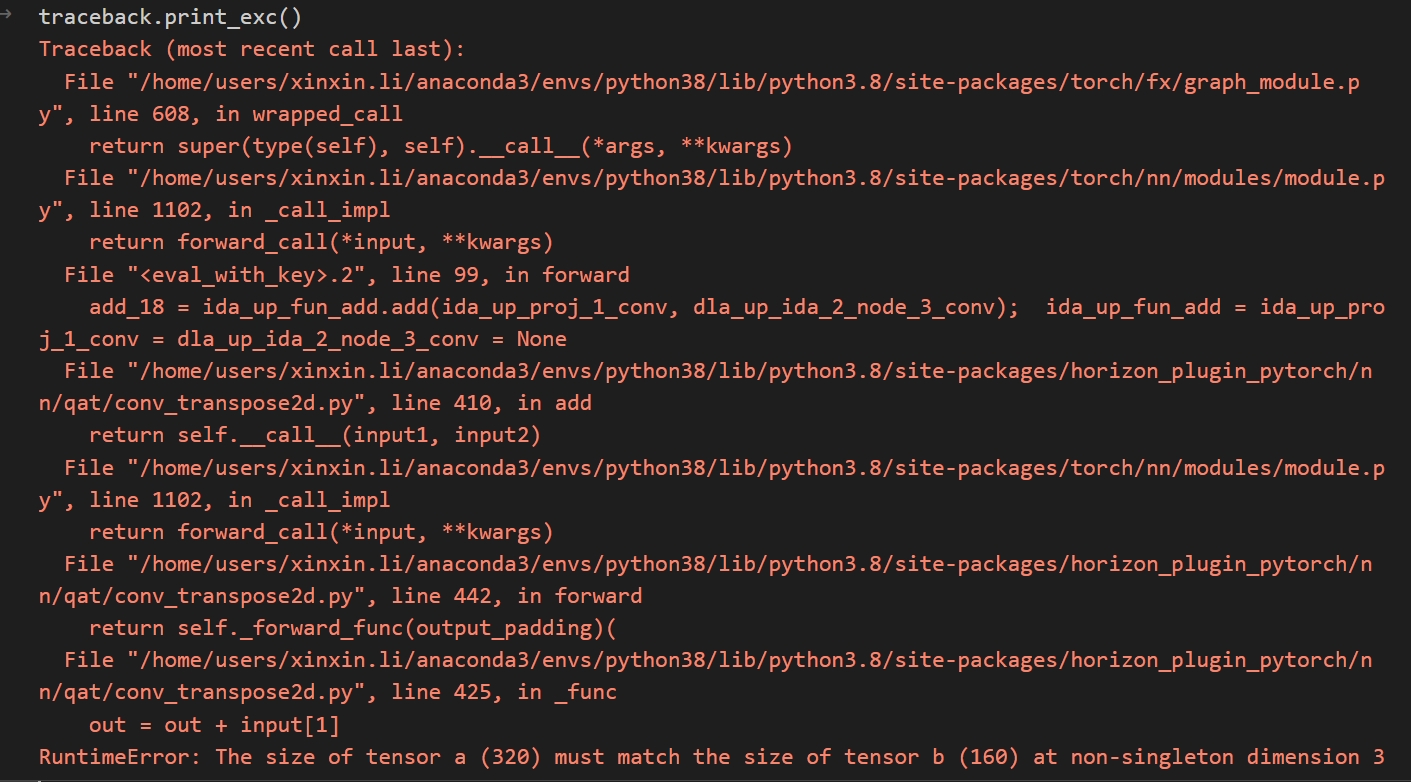
下面这样的写法是不对的,FloatFunctional()不能多次调用,可以用 + 代替
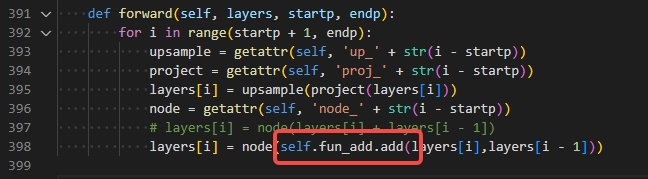
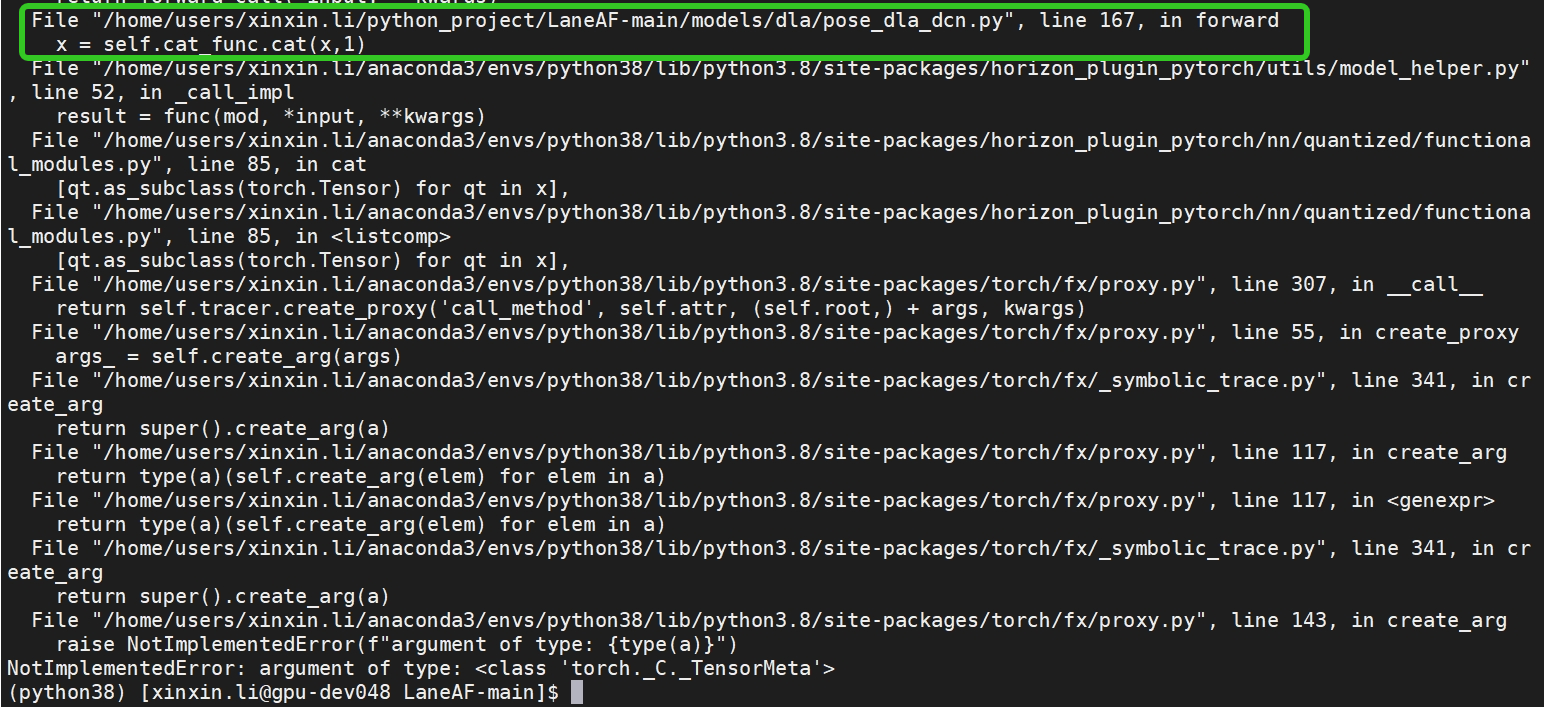
在 prepare_qat_fx之前多做了fuse_fx操作,也可能报错,报错信息奇奇怪怪,一直以为是cat算子的问题,删掉fuse_fx操作就好了。
使用 plugin的 export_to_onnx接口导出qat model,只报 “Aborted”错误,无其他信息

使用plugin的export_to_onnx接口不抛具体错误信息,已经反馈给地平线(猜测新版本已修复),
使用公版接口导qat onnx,报错如下,稍微是能看出来具体问题的

如果让float model和输入不在同一设备,使用公版接口导float.onnx, 报错信息如下,基本一眼就能发现原因。

这是因为公版的浮点已经走到conv逻辑的计算了,所以会报上面很具体的错误,而qat模型在quant stub就挂掉了,所以无论是用公版还是plugin的接口报错信息都很少
torch.jit.trace(quantize_model)时出现的问题:RuntimeError: Only tensors, lists, tuples of tensors, or dictionary of tensors can be output from traced functions
这是因为模型返回的是[dict],改为return dict就好了
同样的,train和val的代码也要改
重新trice,又报了下面这个错误
错误原因:网络输出为list或dict出现错误
解决方案:将输出用tuple和NamedTuple包裹。
编译成功,生成 model.pt、model.hbir、model.hbm
代码附录
暂时无法在飞书文档外展示此内容
其他
ptq与qat得到的量化模型差异对比 (纯粹好奇)
导出qat的qat.onnx, 使用horizon_nn的check工具,对比量化算子分布。
- ptq比qat多了一些 HzRequantize 节点,其他的基本都一致
- ptq中,当两个算子的量化参数不一致时会插入Requantize节点,这个用户是不感知的,HzRequantize 算子对精度也没啥影响
ptq:
qat:

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)