
本文主要探索 开源网络剪枝(结构化剪枝与稀疏化置零)技术在地平线 J5上的可行性和有效性,涉及到的压缩方案,均不考虑硬件加速特性。
1. 实验结果先解读
表中涉及到结构化剪枝两种(ABCPruner_2020、HRankPlus_2020)、结构化稀疏两种(CHEX_2022、1XN_2022),从实验数据可以看出:
在分类任务中,在不使用数据增强、蒸馏、嫁接等主流且有效提升精度的方法下,结构化剪枝与稀疏化在精度损失较小的情况下,在J5上均可以提升性能(latency、FPS)。
结构化稀疏比结构化剪枝,精度上表现更好,但性能表现弱于后者。
网络稀疏化应用于轻量型网络结构,如mobilenet,压缩百分比相对较小,精度损失相比resnet较大,侧面说明轻量型网络中冗余结构相对较少。
1.1 分类模型
|- | -| -|-| -| -| -| -| -|-|
|Resnet18-base| 11.69M| 1.82B| 69.66% |69.40% |68.78% |68.63% | | 1.59 |1,476.68|
|ABCPruner-100%|9.5M|0.97B|67.80%|67.42%| 67.90%| 67.76%| |1.39|1753.08|
|CHEX| |1.03B| 69.60%| 69.77%| 69.15%| 69.11%| | 1.24| 2043.30|
|Resnet50-base| 25.56M| 4.14B| 76.01%| 75.43%| 74.96%| 74.86%| |3.26| 636.40|
|ABCPruner-80%| 11.75M| 1.89B| 73.86%| 73.20%| 73.83% |73.79%| |1.75| 1346.1|
|ABCPruner-100%|18.02M| 2.56B| 74.84%| 74.16%| 74.76%| 74.75%| |2.42| 903.31|
|HRankPlus_1(step)|15.09M|2.26B|75.56%| 75.04%| 74.57%| 74.34%| |2.13| 1060.92|
|HRankPlus_2(cos)|11.05M|1.52B| 75.83%| 75.37%| 74.78%| 74.46%| |1.63| 1459.36|
|HRankPlus_3(cos)|11.81M|1.38B| 75.60%| 74.98%| 74.43%| 73.78%| |1.82| 1269.95|
|CHEX_1 | |3.047B|78.00%|77.69%| 77.07%| 76.44%| |2.76| 789.85|
|CHEX_2 | |1.036B| 76.00%| 75.75%| 75.21%| 74.35%| 74.30%| 1.86| 1248.77|
|1xN_1x4| | | 76.51%| 75.96%| 75.48%| 75.33%| |2.2| 1029.34|
|MobileV1_base|| |70.61%||||| 0.92| 3,270.54|
|1xN_1x2| | | 70.28%| 68.49%| 70.14%| 68.8%| | 0.81| 4105.11|
|1xN_kernel_prun| | | 70.76%| 69.48%| 69.46%| 68.3%| | 0.81| 4118.36|
|MobileV2_base| | |72.65% | | | | |0.89| 3,472.89|
|1xN_1x2| | | 70.23%| 69.43%| 69.99%| 69.38%| | 0.8| 4102.7|
|1xN_kernel_prun| | | 71.15%| 70.59%| 69.56%| 68.95%| |0.81| 4042.04|
HRankplus和ABCPruner属于结构化剪枝,1XN和CHEX属于结构化稀疏。
复现的文件:https://pan.baidu.com/s/1zmUqTuxE1k5LIGPpqBq_Sw 32sv
1.2 检测模型
使用稀疏化方法CHEX对SSD_resnet50_300x300方法在coco2017检测数据集上进行实践。
model | 论文AP | 实测AP | quanti_AP | latency | cpu_latency | bpu_latency | FPS |
|---|---|---|---|---|---|---|---|
baseline | 25.2 | 11.94 | 6.02 | 5.55 | 278 | ||
CHEX_50% | 25.9 | 25.9 | 25.5 | 11.14 | 6.03 | 4.73 | 315 |
已使用hb_verifier工具验证quanti.onnx和bin模型的输出一致性
2. 量化
2.1 概述
量化本质上是对数值范围的重新调整,可以「粗略」理解为是一种线性映射。(之所以加「粗略」二字,是因为有些论文会用非线性量化(对数量化等),但目前在工业界落地的还都是线性量化(对称量化、非对称量化、二值化等),地平线采用的主要是线性量化中的对称量化。
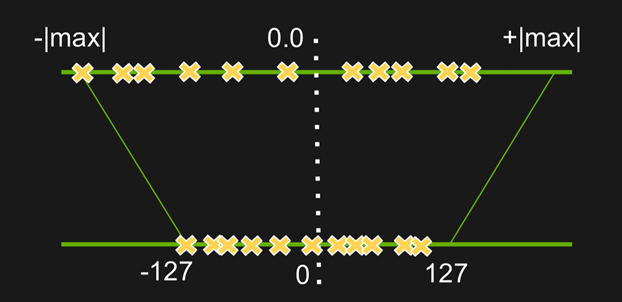

量化的可行性依据:神经网络具有良好的鲁棒性,将高精度模型量化到低精度模型,这个过程可以认为是引入了噪声,而模型对噪声相对不敏感,因此量化后的模型也能保持较好的精度。
量化的目的:降低计算复杂度,提高模型推理速度,降低存储体积,减少计算能耗。在一些对能耗和时间要求更高的场景下,量化是一个必然的选择。
2.2 浮点/定点转换公式
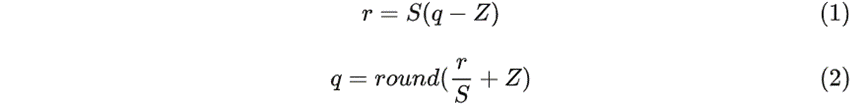
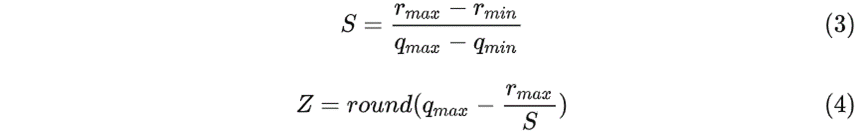
其中,$r_{min}$ 、$r_{max}$分别是 浮点实数r 的最小值和最大值, $q_{min}$ 、$q_{max}$分别是 定点整数q 的最小值和最大值。
对称/非对称量化:当实数中的0量化后对应整数Z也是0时,称之为对称量化,否则,为非对称量化。对称量化相比于非对称量化的精度可能要差一些,但速度会快一些,原因可见公式(7),将公式中的Z置零。
2.3 矩阵运算的量化
卷积网络中的卷积层和全连接层本质上都是一堆矩阵乘法,下面我们来看一看如何将矩阵中的浮点运算转换为定点运算。
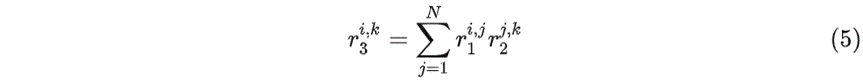
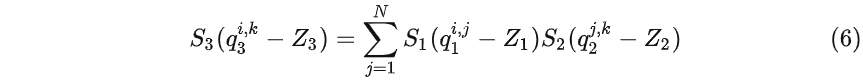
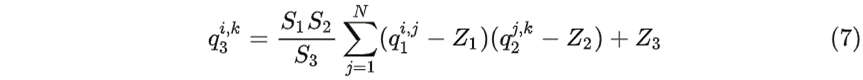
观察 (7) 式可以发现,除了 $S_1S_2/S_3$ ,其它都是定点整数运算。
那如何把 $S_1S_2/S_3$也变成定点运算呢?
因此,如果存在$M=2^{−n}M_0$,我们就可以通过 $M_0$ 的 bit 位移操作实现$2^{−n}M_0$,这样整个矩阵计算过程就都在定点上计算了。
3. 知识蒸馏
主要思想:在网络训练期间,将教师网络的输出信息作为监督信号(知识、软标签),用于指导学生网络去模仿教师网络学习到的信息,继而达到提升学生网络精度的目的。
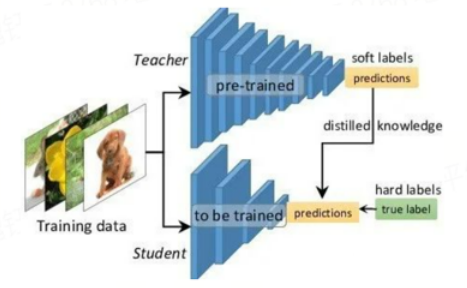

知识蒸馏在分类任务中有着非常优秀的表现,在目标检测等复杂任务场景中的应用还需要进一步的探索与实践。
4. 紧凑型网络设计
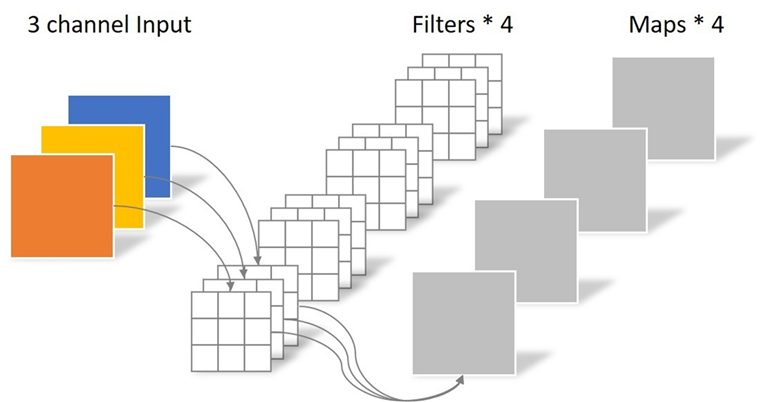
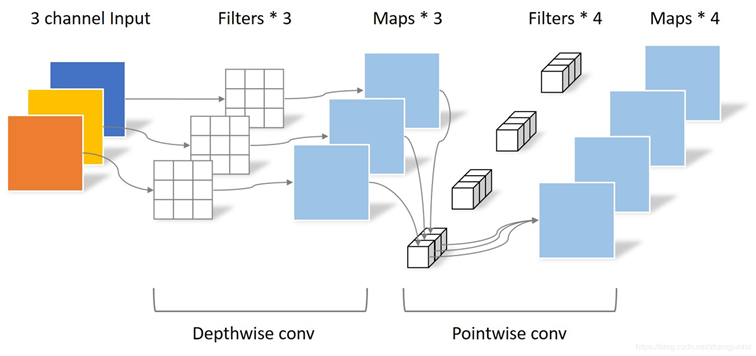
深度可分离卷积,先通过depthwise conv获取self_channel上的特征信息,再通过pointwise conv获取通道间的特征信息,生成4张特征图。
在特征提取能力大致相同的情况下,深度可分离卷积的实现方式,参数量大幅减少。紧凑型网络结构的设计需要大量实验驱动,以保证设计出的网络结构在不同应用场景下均有着良好的表现。
5. 网络剪枝与稀疏化
5.1 总体介绍
网络剪枝的目的:在保证任务精度的同时,剪枝网络中更多的冗余结构,继而加快模型运行速度。
网络剪枝分为非结构化剪枝和结构化剪枝。非结构化剪枝通过剪枝网络每层的神经元来压缩网络,剪枝某个神经元就是将该神经元的值设置为0,本质上是一种稀疏化的过程。由于其可以通过算法深入到神经元进行剪枝,因此可以获得更高的压缩率。这种方法可以通过稀疏化存储方式减少内存占用,较大程度上压缩网络存储体积,但并没有减少计算量。同时,这种剪枝方式也会导致不规则的内存访问,影响网络的在线推理效率,需要特殊设计的软硬件进行加速。
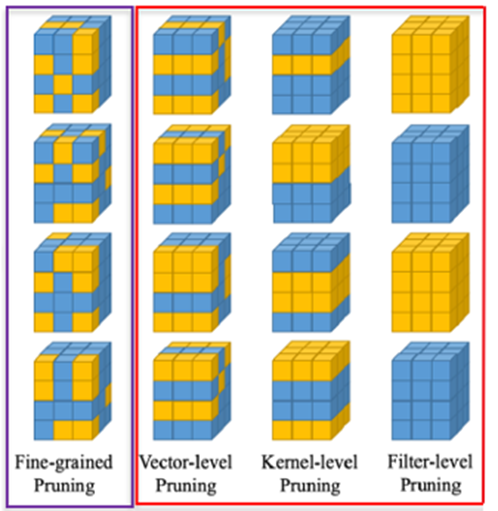
(1) 缺乏权威的度量标准。“Smaller-Norm-Less-Important(SNLI)”流派,网络剪枝基于某度量标准来判断某个结构是否重要,继而进行剪枝,这个度量标准众说纷纭,例如基于L1范数、矩阵中0的个数、导数、信息熵等等,给研究者们带来无限可能。非SNLI流派认为,不是某个网络结构重要,而是网络每层过滤器的保留率重要。
(2) 需要依赖训练数据。针对不同的任务场景,模型剪枝需要依赖数据,现有的大多数剪枝方法采用迭代剪枝的方式,边训练边剪枝,无法在离开数据的情况下获取剪枝模型。
(3) 耗费大量时间与计算资源。网络剪枝通常采用多阶段优化的迭代裁剪(逐层迭代、端到端迭代),最后将迭代裁剪后的网络进行大量重训练来恢复网络精度,需要消耗大量计算资源。
5.2 filter/channel剪枝发展历程


常规卷积剪枝示意图如下:
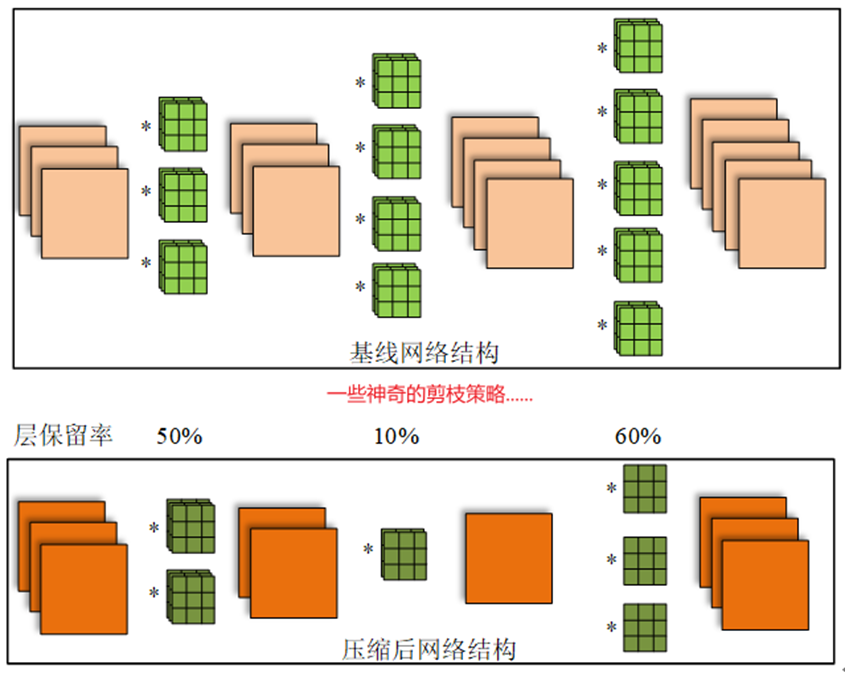
注意:某一层filter少了,下一层每个filter中的kernel也会跟着减少。
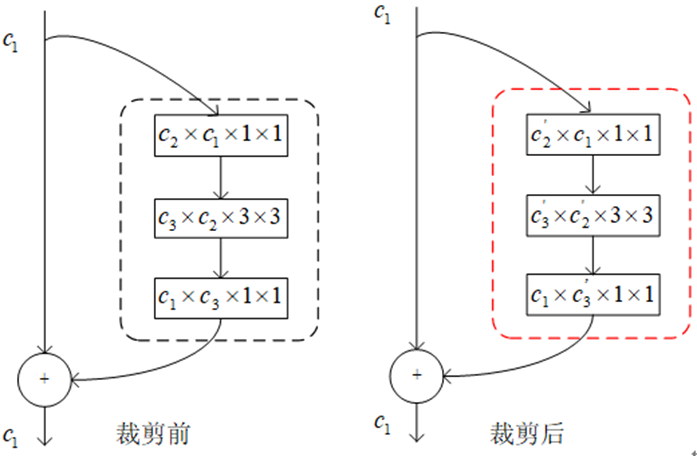
其中,$C_2 × C_1×1×1$表示卷积层有$C_2$个过滤器(filter),每个过滤器有$C_1$个卷积核(kernel),$C'$表示压缩后的过滤器(or卷积核)个数。
保留率(or压缩率)的获取方案可以分为:人工设置(HRankPlus)和方案搜索(ABCPruner),下面在典型论文中分别进行介绍。
5.3 HRankPlus
CVPR 2020, Oral
5.3.1 理论知识
灵感来自于一个发现:无论 CNN 接收的图像batch数是多少,由单个滤波器生成的多个特征图的平均秩总是相同的。作者提出一种针对低秩特征图所对应过滤器进行剪枝的算法。
剪枝原理:低秩特征图包含的信息较少。
为什么 秩 可以作为衡量特征图信息丰富度的指标?作者通过两个理论、一个实验来证明。
什么是矩阵的秩(Rank) :一个矩阵可以看作多个列向量的组合,如果一个列向量可以被其它列向量的通过一定的线性运算表达出来,就说这些向量是线性相关的。倘若一组向量相互不能够被表达,那么这组向量就是线性无关。一个矩阵的rank就是最大线性不相关的向量个数。一个矩阵的秩反应了矩阵所拥有的有效信息量,不相关的向量组合可以看作是有效的信息,而相关的向量可以用这些有效的信息来表达,它是冗余的。
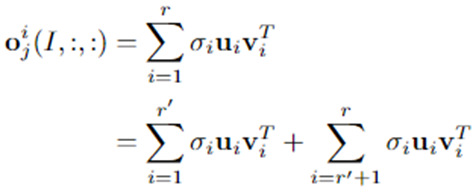

x轴:某层多个特征图的indices
y轴:第几个batch喂入的数据
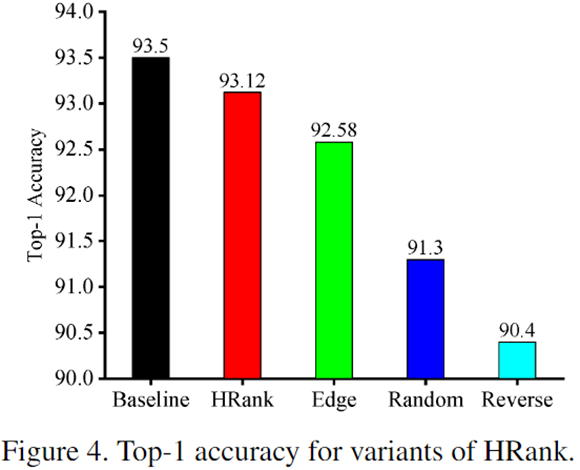
HRank:剪low_rank
Edge:low_rank和high_rank都剪
Random:随机剪
Reverse:剪high_rank
5.3.2 剪枝过程
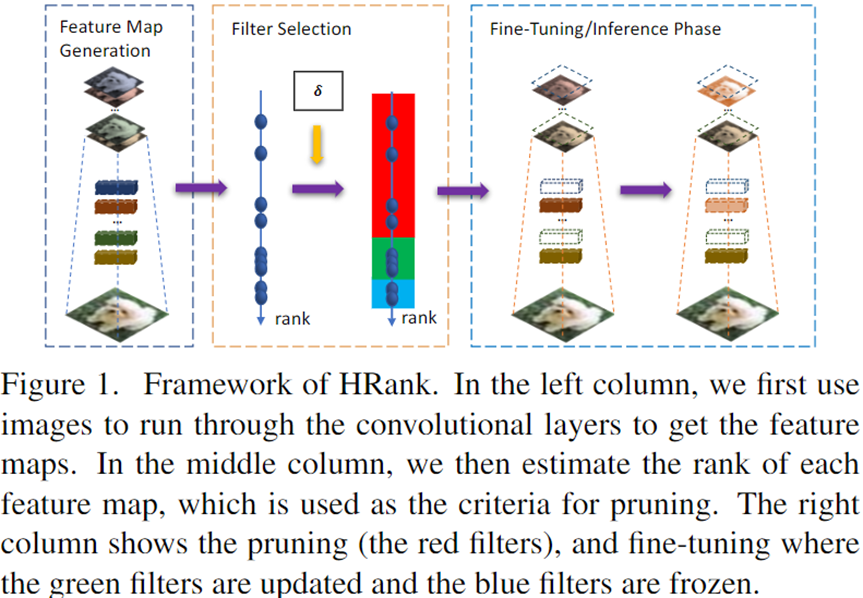
然后,确定各卷积层过滤器的压缩率:经验设置(vgg是layer-by-layer,resnet是block-by-block)
最后,根据计算得到的秩,从filter中筛选出秩高的保留,从而得到剪枝后的模型,微调。
5.3.3 压缩率对网络结构影响的解读
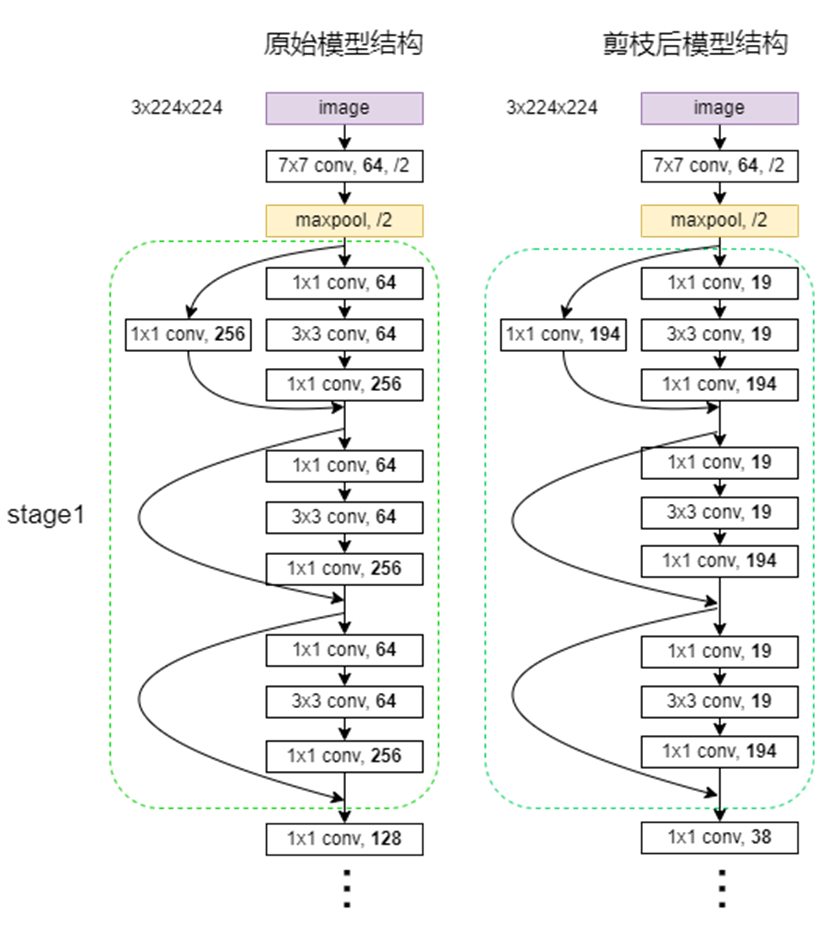
[0.24]*3:前三个stage的输出filter个数压缩率,最后一个stage输出filter个数不压缩
[0.7]*7+[0.45]*9:4个stage中[3, 4, 6, 3]个每个block中间层filter个数压缩率
[64, 194, 194, 194, 389, 389, 389, 389, 778, 778, 778, 778, 778, 778, 2048, 2048, 2048]
17=1+3+4+6+3=第一个卷积输出+各个残差块输出
[19, 19, 19, 38, 38, 38, 38, 140, 140, 140, 140, 140, 140, 281, 281, 281]
16= 3+4+6+3=各个残差块中间层输出
5.4 ABCPruner
IJCAI 2020
5.4.1 理论知识
ABCPruner是一种基于人工蜂群(artifical bee colony)算法的通道剪枝方法。目的是有效地找到最佳的剪枝结构,即每一层中的通道数,而不是选择“重要”的channel(启发于19年ICLR上的Rethinking),对最佳剪枝结构的搜索,公式化为一个优化问题,参考ABC算法以搜索策略解决这个问题(启发于18年CVPR上的Amc),减少人为干扰。
5.4.2 剪枝过程
将每层的裁剪方案限制成十个,具体做法:假设该层的filter数目为c,取10%c,20%c,...,100%c 十个数作为该层裁剪的选择空间。总结:将通道组合压缩到一个特定空间。
具体实现过程:
初始化一个 structure set,set中的每个元素表示每层要保留的通道数目(实际上是初始化多个structure set,每个set代表一种剪枝方案)
根据这个集合对每层进行随机裁剪
训练少量epochs,测试精度fitness(减少计算资源消耗)
然后使用ABC来更新 structure set
重复 2,3,4
- 挑选出最优结构,进行微调
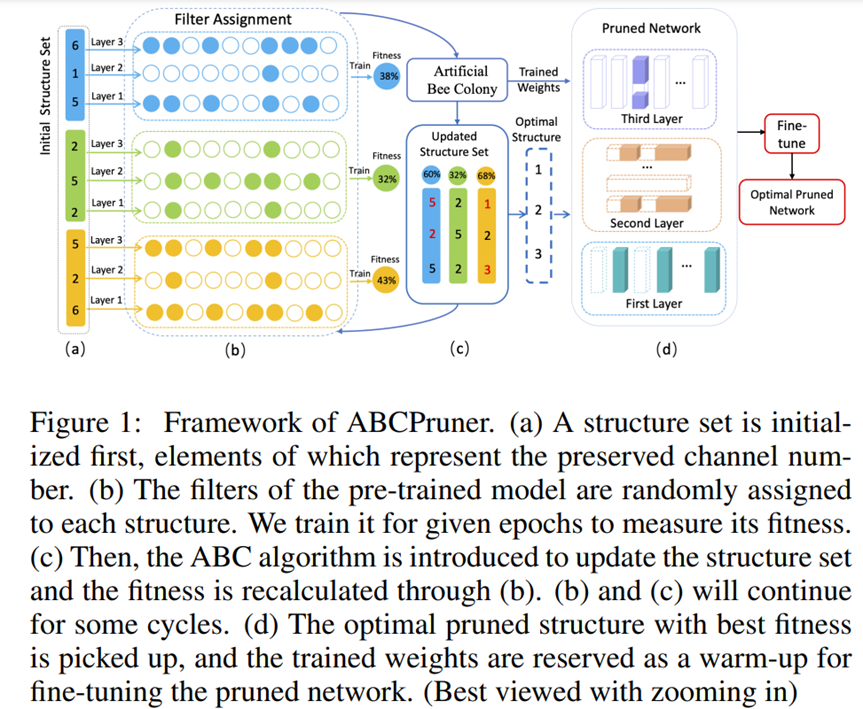
$\alpha$:保留率上限
n:被剪枝网络集合中的网络个数
$t_i$:计数器
M:某个网络结构M次没变,重新初始化它
$C^{'}$:被剪枝网络结构
$fit_{C}$:网络结构C的fitness

从2022年发的一些文章上看,大家倾向于往稀疏化置零上进行探索了。相比于上面介绍的结构化剪枝,稀疏化置零不需要考虑维度匹配的限制,通常精度更高,但需要硬件支持稀疏化。
5.5 1xN Pruning
TPAMI 2022
5.5.1 理论知识
filter级别剪枝:剪枝filter中的所有kernel(该方案也会剪枝掉下一层filter中的对应kernel)
1XN Pruning:剪枝具有相同输入channel index的连续N个输出kernel(如:连续4个filter中的第1个kernel)
5.5.2 剪枝过程
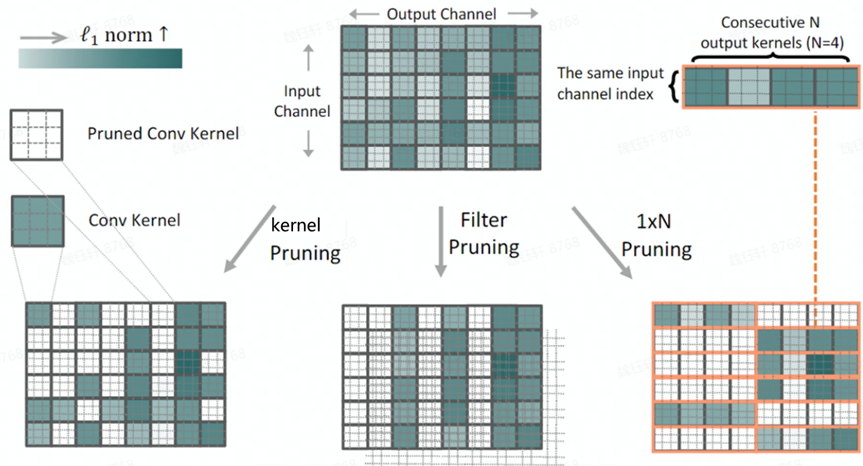
注意:
该剪枝方案是一种稀疏化的操作,是将某些kernel全部置零,理论上属于结构化剪枝(稀疏),考虑到维度匹配问题,在网络搭建时,无法控制到内部kernel级别,故无法获取剪枝后的网络,需要支持稀疏化的硬件才能加速。
5.6 CHEX
CVPR 2022
5.6.1 剪枝过程
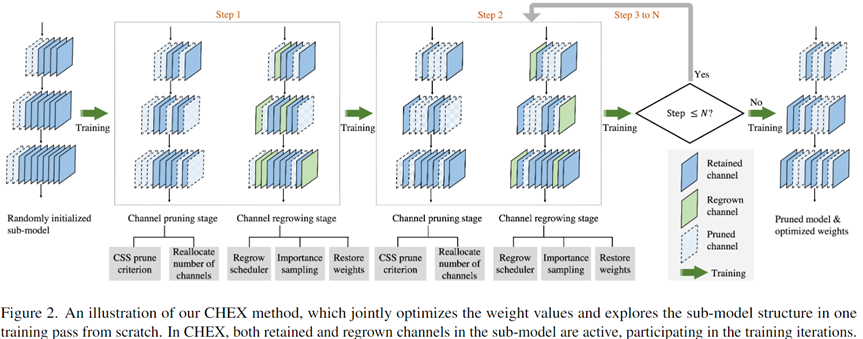
原始模型:Conv-6-8-10,随机初始化子模型结构
Channel pruning stage:根据目标稀疏度,剪枝不重要的channel,每一层的通道数会在这一步使用“sub-model structure exploration technique”进行重新生成,例如,图中step1中的conv-3-4-5,step2中的Conv-2-3-7。
Channel regrowing stage:每一次pruning后,会regrow之前剪枝掉的一部分channel,这些恢复的channel weight,会使用被剪枝前最近一次的weight。
- 每进行一次2. 3两步(成对出现),会训练一些epoch,这个过程重复N次,得到剪枝后的网络。

5.6.2 轻量型网络剪枝结果
注意:
该剪枝方案是一种稀疏化的操作,虽然是将某filter权重全部置零,理论上属于结构化剪枝,但由于剪枝通道位置是不定的,每一层剪枝率也不定,特别是对于具有shortcut的网络,无法获取剪枝后的网络,因此只能是结构化稀疏置零,故需要支持稀疏化的硬件才能加速。
6. 模型转换与测试性能
6.1 模型转换
6.2 性能评测
latency单核单线程
FPS双核多线程
7. 总结与思考
结构化压缩方案(包括结构化剪枝和稀疏化置零)在地平线J5 上均可以实现加速。
未来地平线会支持稀疏化训练吗?会有标准的参考文档进行介绍吗?期待中~
8. 参考链接
https://zhuanlan.zhihu.com/p/149659607
https://zhangkaifang.blog.csdn.net/article/details/108753791
https://www.sohu.com/a/395528127_129720
https://blog.csdn.net/u011231598/article/details/116455709
https://github.com/lmbxmu/HRankPlus
https://blog.csdn.net/m0_37192554/article/details/106402269
https://blog.csdn.net/lihuanyu520/article/details/107097820
https://github.com/lmbxmu/1xN
https://github.com/zejiangh/Filter-GaP
https://github.com/lmbxmu/ABCPruner




'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)