
YOLOP是华中科技大学研究团队在2021年开源的研究成果,其将目标检测/可行驶区域分割和车道线检测三大视觉任务同时放在一起处理,并且在Jetson TX2开发板子上能够达到23FPS。
论文标题:YOLOP: You Only Look Once for Panoptic Driving Perception
论文地址: https://arxiv.org/abs/2108.11250
官方代码: https://github.com/hustvl/YOLOP
一、网络结构
相比于其它论文,YOLOP的论文很容易阅读。YOLOP的核心亮点就是多任务学习,而各部分都是拿其它领域的成果进行缝合,其网络结构如下图所示:
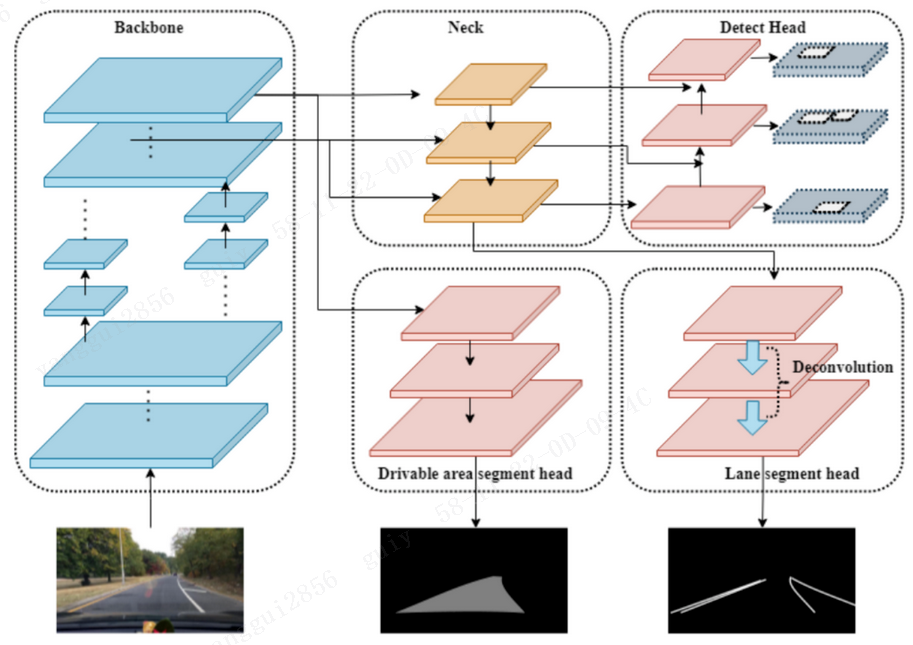
三个子任务共用一个Backbone和Neck,然后分出来三个头来执行不同的任务。
1、Encoder
根据论文所述,整个网络可以分成一个Encoder和3个Decoder。
Encoder包含Backbone和Neck,Backbone照搬了YOLOv4所采用的CSPDarknet,Neck也和YOLOv4类似,使用了空间金字塔(SPP)模块和特征金字塔网络(FPN)模块。
2、Decoders
Decoders即三个任务头
Detect Head
目标检测头使用了Path Aggregation Network (PAN)结构,这个结构可以将多个尺度特征图的特征图进行融合,其实还是YOLOv4那一套。
Drivable Area Segment Head & Lane Line Segment Head
可行驶区域分割头和车道线检测头都属于语义分割任务,因此YOLOP使用了相同的网络结构,经过三次上采样,将输出特征图恢复为(W, H, 2)的大小,再进行具体任务的处理。
3、Loss Function
损失函数包括三部分,即三个任务的损失。
目标检测损失
目标检测是直接照搬YOLOv4的,因此和YOLOv4采用的损失一样,经典的边界框损失、目标损失和类别损失,各自加了个权重。
语义分割损失
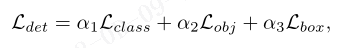
另外两个语义分割损失采用的均是交叉熵损失。
总体损失,总体损失为三部分损失之和:
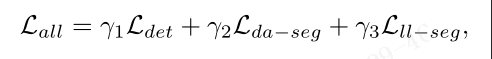
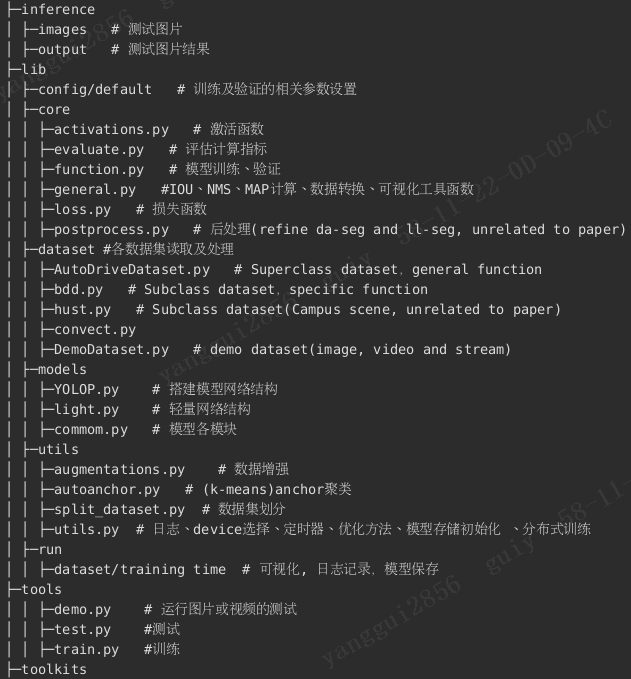
二、代码结构
三、训练--tools/train.py
1、设置DDP参数
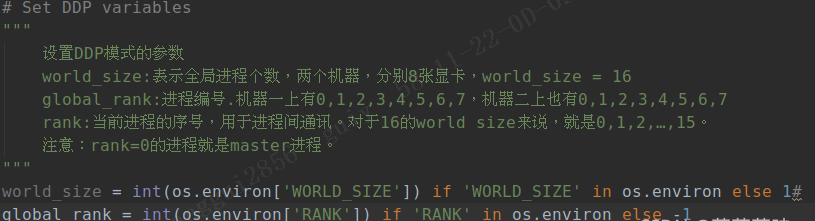
pytorch中DDP使用
(1)参数加载
(2)模型转换成DDP模型
(3)训练数据sampler,来使得各个进程上的数据各不相同
(4)分布式模型的保存
2、读取网络结构

3、定义损失函数及优化器

4、 网络结构划分
用于单任务训练固定其他网络部分层

5、初始化学习率
后续在train()中warmup会调整学习率

首先定义一个优化器,定义好优化器以后,就可以给这个优化器绑定一个指数衰减学习率控制器。
参数:
四、dataset/bdd.py文件
1、数据读取
该文件继承AutoDriveDataset.py
1、

2、按比例缩放操作:letterbox()图像增加灰边
3、数据增强操作
2、数据增强
utils/utils.py文件
1、random_perspective()放射变换增强
2、augment_hsv()颜色HSV通道增强
3、cutout()
五、models/YOLOP.py文件

yolop包括三个检测任务,目标检测+可行驶区域检测+车道线检测。
六、损失函数
loss.py postprocess.py
build_targets思想:
build_targets主要为了拿到所有targets(扩充了周围grids)对应的类别,框,batch中图片数索引和anchor索引,以及具体的anchors。 每个gt按照正样本选取策略,生成相应的5个框,再根据与默认anchor匹配,计算宽高的比例值,根据阈值过滤不相符的框,得到最终正样本。
损失计算:
1、目标检测损失
predictions[0] 目标检测分支[[4,3,48,80,6],[4,3,24,40,6],[4,3,12,20,6]]。
targets[0] 目标检测标签 [32,6],格式为[batch_num,class,x1,y1,x2,y2]。根据build_targets在每个检测层生成 相 应的正样本tbox[]。
将每层的预测结果tensor pi根据正样本格式得到ps = pi[b, a, gj, gi]。
计算每个检测层预测与正样本之间的ciou坐标损失。
obj损失:

cls类别损失:

2、可行驶区域损失

3、车道线损失

七、网络模型输出格式形式
1、网络模型检测输出格式
det_out:障碍物检测输出格式: [25200,6] 其中6表示[x1,y1,x2,y2,conf,cls],25200 :(80x80+40x40+20x20)x3
2、网络模型车道线输出格式
lane_line_seg : 车道线分割输出格式:1,2,640,640

3、网络模型可行驶区域输出格式
drive_area_seg : 可行驶区域分割输出格式:1,2,640,640

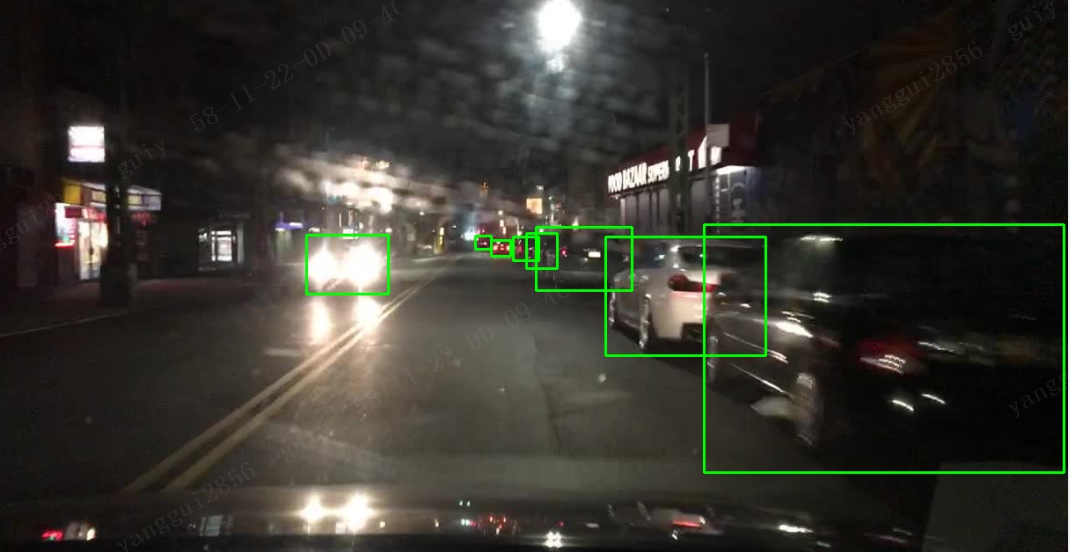
八、前视停车场数据集检测效果图



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)