
目录
- 1. 必要步骤速览
- 2. 各步骤详解
- 2.1 浮点模型准备
- 2.2 数据校准
- 2.3 量化训练
- 2.4 定点转换
- 2.5 模型编译
- 3. 常见问题
1. 必要步骤速览
强烈建议在量化训练前(甚至是浮点模型设计阶段)先跳过训练过程完整走完prepare->convert->check步骤,确保模型可被硬件支持。
2. 各步骤详解
2.1 浮点模型准备
d. 更多关于如何搭建量化友好模型的说明可参考用户手册 4.2.4.1浮点模型的要求
- 在模型输入前插入 QuantStub节点,在模型输出后插入 DequantStub节点。有如下注意事项:
多个输入仅在 scale 相同时可以共享 QuantStub,否则请为每个输入定义单独的 QuantStub
建议使用horizon\plugin_pytorch.quantization.QuantStub 默认动态统计输入scale,若是可提前计算出scale的场景建议手动设置scale(例如bev模型的homo矩阵),对应的公版接口torch.quantization.QuantStub不支持手动设置。
- 参考算子约束列表完成算子替换。做这一步的原因是eager mode对算子的支持有一定限制,对部分算子的量化会有一些特殊处理。(例如需要用torch.nn.ReLU\替换torch.nn.functional.relu,add/cat/matmul等需要替换为horizon.nn.quantized.FloatFunctional,具体可参考如下示例)。
- 算子融合:算子融合可显著提高模型量化精度及部署性能,因此这是不可或缺的步骤,目前可支持conv/ConvTranspose2d/linear、bn、relu/relu6、add之间的融合(具体可参考:PythonPath/horizonpluginpytorch/quantizationfusemodules.py),支持使用算子下标或算子名称来写融合函数,具体可参考如下示例。
2.2 数据校准
2.3 量化训练
量化训练一些推荐的超参配置如下表所示:
超参
推荐配置
高级配置(如果推荐配置无效请尝试)
LR
从0.001开始,搭配StepLR做2次scale=0.1的lr decay
- LR 更新策略也可以尝试把 StepLR 替换为 CosLR。
- QAT使用AMP,适当调小lr,过大导致nan。
Epoch
浮点epoch的10%
1. 根据loss和metric的收敛情况,考虑是否需要适当延长epoch。
Weight decay
与浮点一致
1. 建议在4e-5附近做适当调整。weight decay过小导致weight方差过大,过大导致输出较大的任务输出层weight方差过大。
optimizer
与浮点一致
1. 如果浮点训练采用的是 OneCycle 等会影响 LR 设置的优化器,建议不要与浮点保持一致,使用 SGD 替换。
transforms(数据增强)
与浮点一致
1. QAT阶段可以适当减弱,比如分类的颜色转换可以去掉,RandomResizeCrop的比例范围可以适当缩小
averaging\_constant(qconfig\_params)
- weight averagingconstant一般不需要设置成0.0,实际情况可以在(0,1.0]之间调整
强烈建议您先尝试数据校准,若精度不满足预期再进行量化训练(注意要加载数据校准后权重参数)。
2.4 定点转换
请注意,定点模型和伪量化模型之间无法做到完全数值一致,所以请以定点模型的精度为准。若定点精度不达标,仍需要继续进行量化训练,建议多保留几个epoch的qat模型权重,便于寻找最优的定点精度。(qat或者calibrate精度高并不一定代表定点精度高,可以考虑进行一些回退,平衡最终的定点精度)
在正常情况下,定点模型的精度与板端部署精度是可以保持完全一致的,因此可使用该模型来评测最终部署精度。
2.5 模型编译
模型编译阶段包括以下三个步骤:
compilemodel()更多配置项请参考 用户手册-模型编译
3. 常见问题
1. 为何要设置高精度输出?
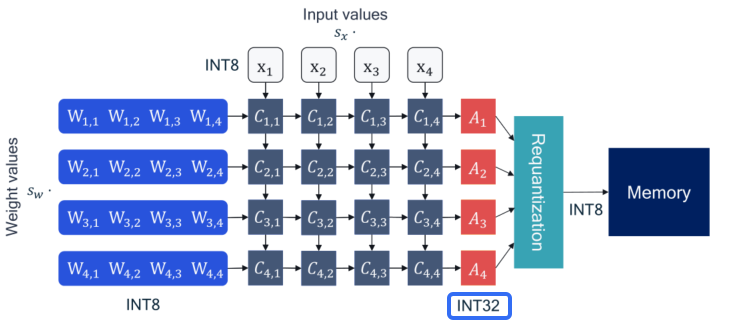
plugin ≤ v1.6.2 配置高精度输出需使用 default_calib_out_8bit_fake_quant_qconfig ,但该参数将在后续版本中被废弃
2. 如何理解fake quantize的几种状态?
从这段代码中我们可以得知:
在QAT之前要求模型设置的是train()的状态,CALIBRATION和VALIDATION则要求模型是eval()状态,这主要是为了使bn、dropout等处于正确的状态(训练的时候bn会更新,评测的时候bn不更新)。
- CALIBRATION时会disablefakequant,并设置fakequant状态为train(),即不进行伪量化操作,仅观测算子输入输出统计量,更新scale;QAT时会观测统计量并进行伪量化操作;VALIDATION时不会观测统计量,仅进行伪量化操作。
因此如下常见误操作会导致一些异常现象:
- 数据校准之前模型设置为train()的状态,且未使用setfakequantize,等于是在跑QAT训练;
- 数据校准之前模型设置为eval()的状态,且未使用setfakequantize,会导致scale一直处于初始状态,全为1;
- 数据校准之前模型设置为eval()的状态,且正确使用了setfakequantize,但是在这之后又设置了一遍model.eval(),这将导致fakequant未处于训练状态,scale一直处于初始状态,全为1;
3. 如何固定模型某个部分参数不更新?

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)