
0 概述
光流估计任务为求解连续两帧图像中目标物体或者目标像素点的偏移量,偏移量往往用二维向量表示。按照是否选取图像中稀疏点进行光流估计,可以分为稀疏光流和稠密光流,PWCNet面向稠密光流估计。PWCNet拥有参数量小和轻量化优点的同时,还有着优秀的估计精度,使其成为其中最热门的算法之一,因此地平线集成了光流估计PWCNet算法。本文将详细介绍光流估计PWCNet参考算法的原理和部署。
该示例为参考算法,仅作为在J5上模型部署的设计参考,非量产算法
1 性能精度指标
模型参数:
数据集 | Input Shape | Backbone | Head |
|---|---|---|---|
FlyingChairs | 1x6x384x512 | PwcNetNeck | PwcNetHead |
FlyingChairs数据集参考:FlyingChairs数据集
模型性能精度表现:
模型 | 性能(FPS/双核) | EndPointError(定点模型) |
|---|---|---|
PWCNet | 161.52 | 1.4075 |
2 模型介绍
PWCNet网络模型由NVIDIA在“CVPR, 2018”提出,是一个轻量且高效的基于CNN的光流估计模型,相比稠密光流估计的主流模型FlowNet 2.0,其网络大小缩小了17倍并且对于训练更加友好。此外截至论文发稿,PWCNet在“MPI Sintel final pass”和“KITTI 2015 benchmarks”上的性能和精度优于发布的所有光流估计算法,成为光流估计任务的SOTA(State-Of-The-Art)模型,同时是基于深度学习的光流估计中非常基础且具有重要意义的一个网络模型。
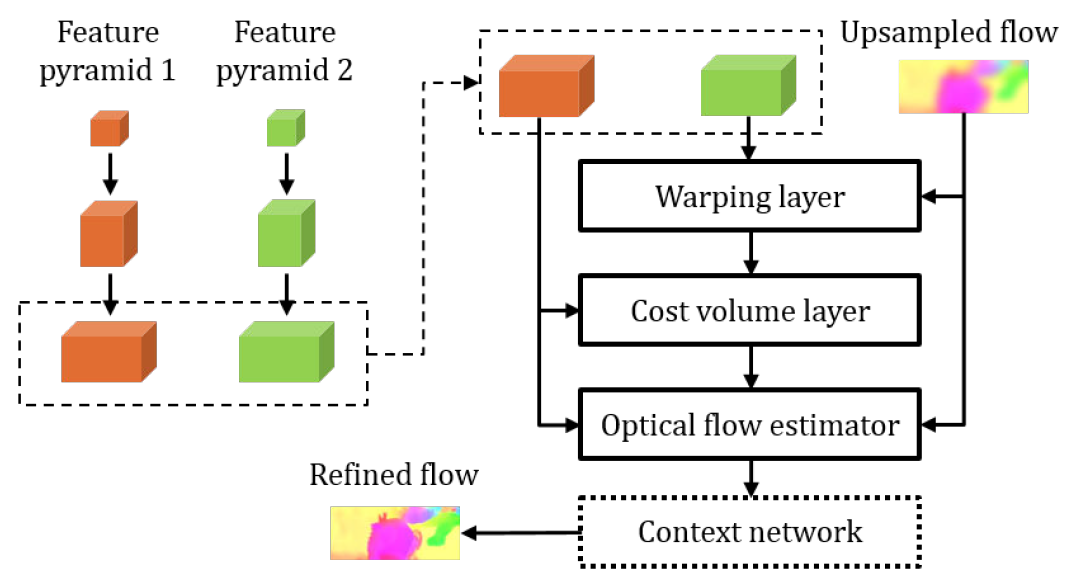
PWCNet的模型设计主要基于三个简单高效且成熟运用的原则:金字塔多尺度特征提取(Pyramidal Processing)、光流映射(Warping)和相关性匹配成本量(Cost Volume)。其模型构成包括多尺度特征金字塔、光流映射层、相关性匹配成本层、光流估计器和Context Network:
- 多尺度特征金字塔:不同于直接使用图像金字塔,特征金字塔对阴影和光照变化更为鲁棒,PWCNet基于多尺度特征金字塔的设计使其对不同尺度的光流(不同大小的像素点运动偏移量)拥有更准确的感知,因为对于一个$L$层的特征图金字塔,顶层特征图一个像素点的位移映射回原图则是$2^{L-1}$个像素点的位移。此外用多尺度特征金字塔替换传统的子网络串联,极大地减少可学习参数量的同时,减小了模型训练的复杂度;
- 光流映射层+相关性匹配成本层:光流映射层实现了将上层输出的光流(除金字塔顶层)应用到当前层特征图并生成映射后的特征图,相关性匹配成本层衡量相同尺度的第一帧图像特征图和第二帧图像映射后的特征图之间的像素相关性。光流映射层和相关性匹配层共同使每一层的光流(除金字塔顶层)都在上一层的基础上进一步Refine,实现了对输出光流的Coarse-to-fine。此外对于光流的非平移运动,光流映射操作对几何扭曲有补偿作用且可以将图像块恢复到正确比例。光流映射层和相关性匹配层没有可学习的参数,实现了模型参数量的减少和轻量化的目的;
- 光流估计器:光流估计器由CNN网络和反卷积层组成,CNN网络通过可学习的参数处理输入的上一层特征图信息、上一层输出的粗糙光流(金字塔顶层除外)和相关性匹配层输出的特征图相关性信息,输出当前层的细化后的光流,细化后的光流和特征图经过反卷积层放大至自身两倍,作为下一层的输入;
- Context Network:Context Network由CNN网络组成,对最终输出的光流进行优化,其中CNN网络使用空洞卷积,在不引入额外计算量的前提下提高感受野,优化光流质量。
参考资料:
2.1 模型改动点
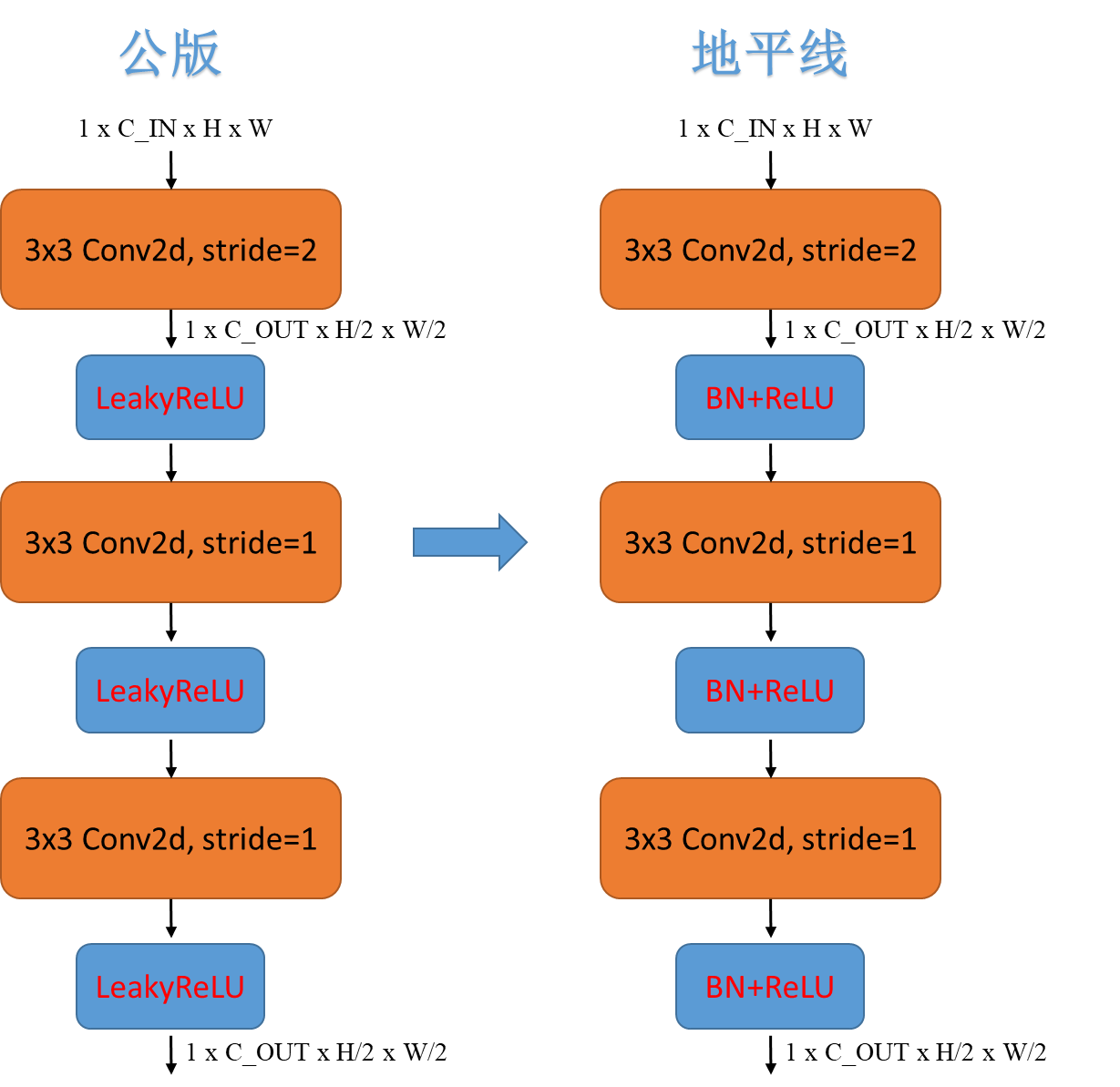
相比于公版模型,地平线所做的改动主要为:
出于模型优化考虑,在Backbone以及Head的部分卷积模块中,激活函数替换LeakyReLU为ReLU,并使用Conv+BN+ReLU的结构,其中BN模块对于量化更加友好;
在Warp操作中,去掉了地平线不支持的公版mask相关操作。
2.2 源码说明
2.2.1 Config文件
注:如果需要复现精度,config中的训练策略最好不要修改,否则可能会有意外的训练情况出现。
2.2.2 模型结构
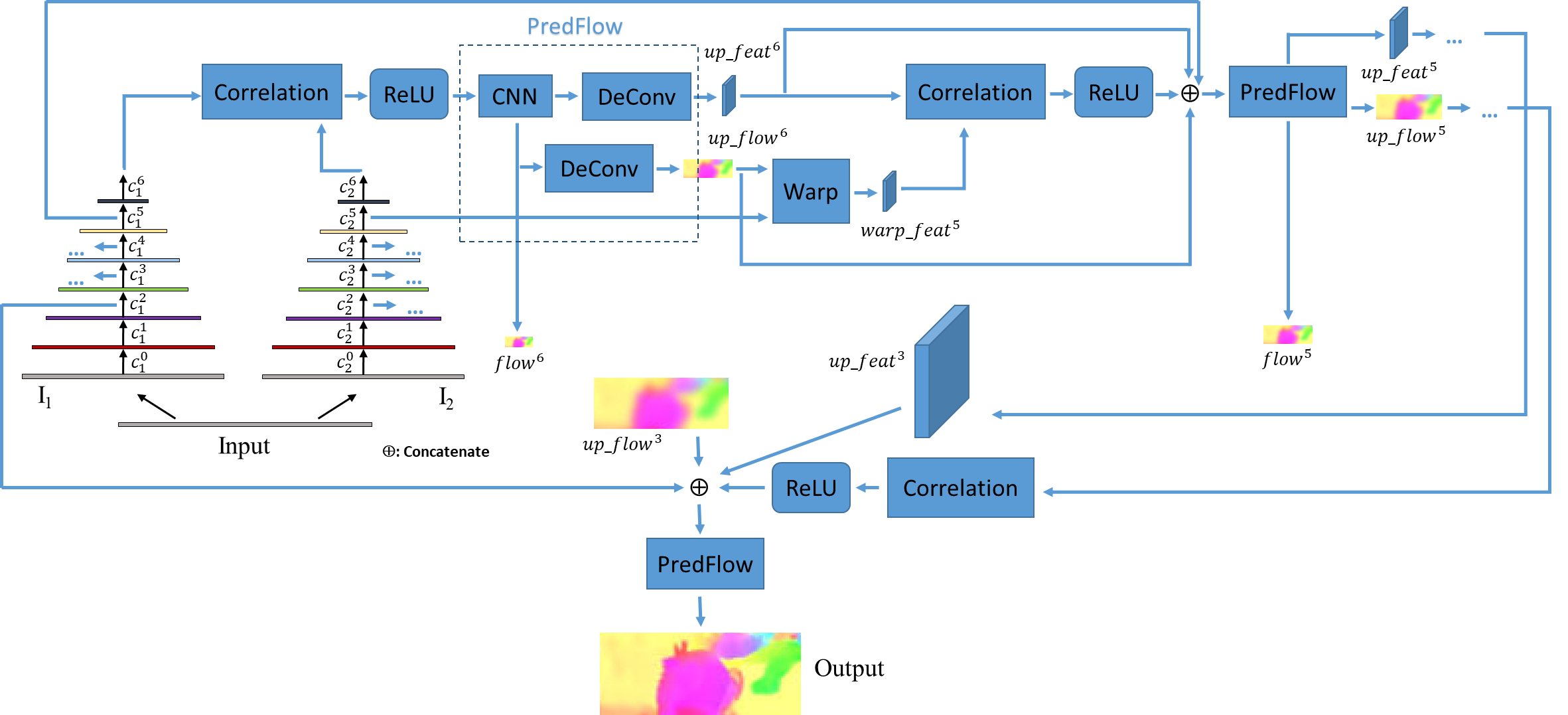
地平线光流估计PWCNet参考算法的模型结构如下所示:
2.2.2.1 Backbone
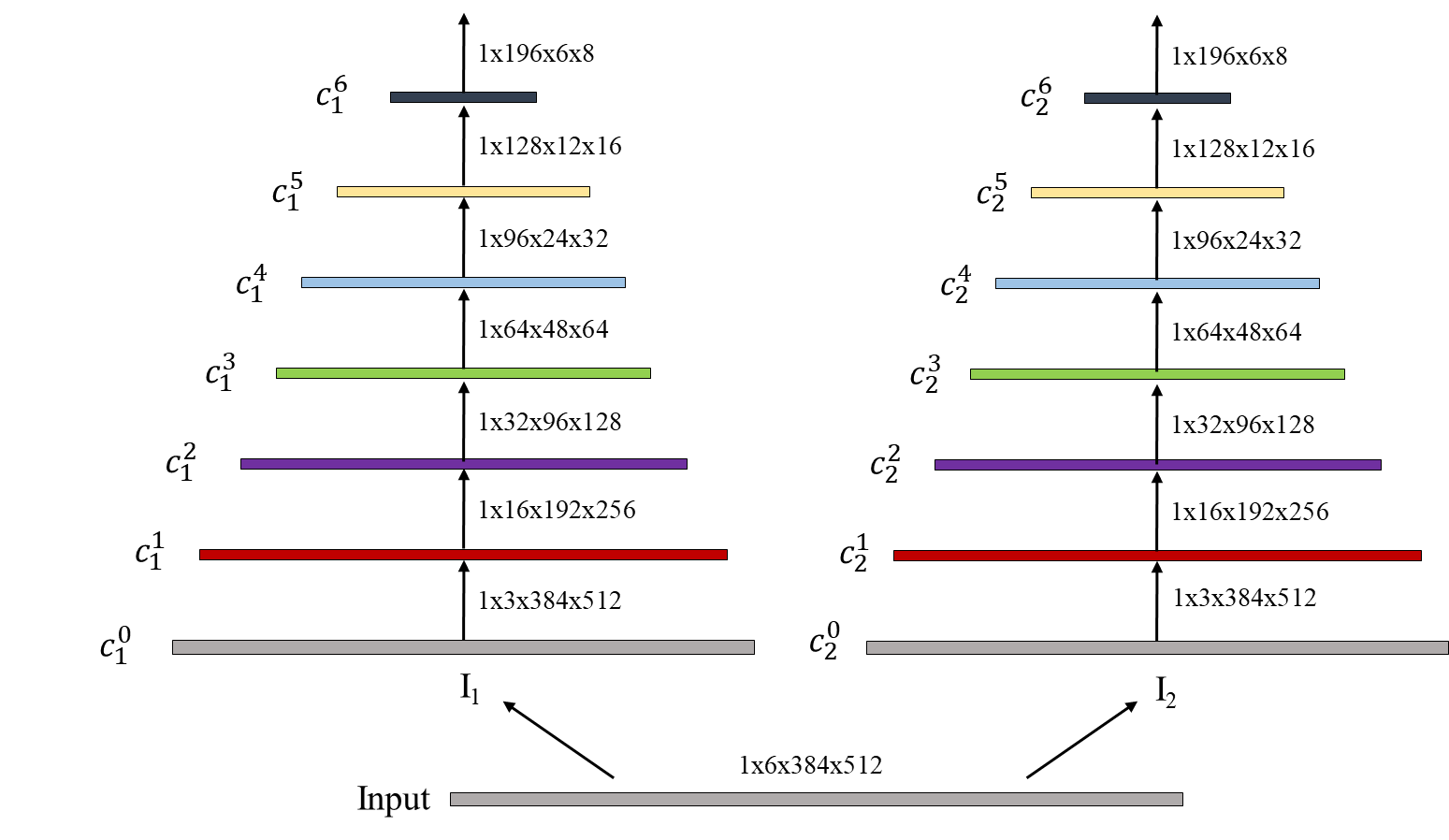
Backbone由3x3的二维卷积所组成的多层CNN网络来提取输入图像的多尺度金字塔特征。输入尺寸1x6x384x512为两帧1x3x384x512的图像堆叠而成,并在后面的处理中拆分,共享一个网络,分别提取特征,达到了不引入额外参数量的目的。
2.2.2.2 Head
Head部分对Backbone提取的多尺度金字塔特征进行处理,通过相关性匹配和Warp映射操作实现输出光流的Coarse-to-fine,并最终输出Refined光流。根据模型结构图可知Head部分主要组成模块为:Correlation(相关性匹配)、Warp(光流映射)和PredFlow(光流估计)。
2.2.2.2.1 Correlation
Correlation部分进行特征图的相关性匹配,也就是公版模型提到的Cost Volume,其计算过程和卷积类似,都是对应位置特征值的点积和,不同之处在于特征图Correlation的Kernel为另一张特征图或另一张特征图的patch,且不同于卷积操作需要先对Kernel进行翻转。公式如下:
c(x_{1}, x_{2}) =
\sum_{o \in [-k,k] \times [-k,k]} <f_{1}(x_{1} + o), f_{2}(x_{2} + o)>
$$
其中$k=2D+1$为Correlation Kernel的边长,$D=4$为本模型所取的Kernel半径,和公版一致。Correlation部分无可训练的权重参数,减少了参数量从而达到模型轻量化的目标。
2.2.2.2.2 Warp
I(x,y,t)=I(x+\delta{x},y+\delta{y},t+\delta{t})
$$
2.2.2.2.3 PredFlow
PredFlow部分输入为在通道维度上整合的粗糙光流信息、特征图信息和相关性信息,使用一个CNN网络处理并输出估计的光流,以及通过反卷积层对本层估计的光流和特征图进行处理,为下一层的光流估计提供信息,实现光流的Coarse-to-fine。在CNN网络中引入了Dense Connection和Residual Connection,进行特征复用以及获得更好的梯度流信息,提高模型的精度和泛化能力。此外引入Context Network对光流进行进一步优化。
2.2.3 Loss
Training Loss用来衡量每一层估计的光流(共5层)和光流真值之间的距离,也就是公版论文提到的多尺度光流Training Loss,公式如下:
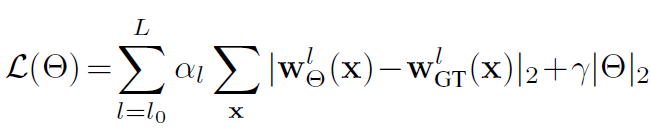
2.2.4 EPE Metric
EPE(Endpoint Error)是评估光流估计算法精度的指标,计算方法为估计的光流向量终点二维坐标和真值光流向量终点二维坐标的欧式距离。
2.2.5 后处理
光流估计后处理分为两部分:第一步将输出的光流图通过双线性插值操作恢复到原图分辨率;第二步进行光流图的可视化,可视化具体做法为用色相(Hue)去表示光流向量的方向,用色度(Saturation)去表示光流向量的长度,简而言之,就是用不同的颜色去表示像素点不同的运动方向,像素点运动偏移越大,该色彩的亮度越高。
可视化代码路径:/usr/local/lib/python3.8/dist-packages/hat/visualize/opticalflow.py
3 浮点模型训练
3.1 Before Start
3.1.1 发布物及环境部署
J5:下载OE包horizon_j5_open_explorer_v$version$-py38_$releasedate$.tar.gz,获取方式见地平线开发者社区【OpenExplorer J5算法工具链 版本发布】。
step2: 解压发布包
获取发布包后,首先对其进行解压:
解压后文件结构如下:
step3: 拉取GPU docker环境
3.1.2 数据集准备
3.1.2.1 数据集下载
3.1.2.2 数据集打包
--src-data-dir为解压后的FlyingChairs数据集目录;
--target-data-dir为打包后数据集的存储目录。
3.1.3 Config配置
device_ids、batch_size_per_gpu:根据实际硬件配置进行gpu id和每个gpu的batchsize的配置;
- ckpt_dir:浮点、calib、量化训练的权重路径配置,权重下载链接在对应configs/opticalflow_pred/pwcnet/README.md文件中;
data_path:数据集的存放路径,按照实际存放路径配置。
3.2 浮点模型训练
环境部署、数据集准备和config文件中的参数配置完成后,使用以下命令训练浮点模型:
浮点模型训练后模型ckpt的保存路径为config配置的ckpt_callback中save_dir的值,默认为ckpt_dir。
3.3 浮点模型精度验证
浮点模型训练完成以后,可以使用以下命令验证已经训练好的浮点模型精度:
验证完成后,会在终端打印浮点模型在验证集上的精度,如下所示:
4 模型量化和编译
完成浮点训练后,还需要进行量化训练和编译,才能将定点模型部署到板端。地平线对该模型的量化采用horizon_plugin框架,经过Calibration+QAT量化训练后,使用compile工具将量化模型编译成可以上板运行的“hbm”文件。
4.1 Calibration
4.2 Calibration模型精度验证
Calibration完成以后,可以使用以下命令验证Calibration模型的精度:
验证完成后,会在终端输出Calibration模型在验证集上的精度,格式见3.3。
4.3 量化模型训练
量化训练后模型ckpt的保存路径为config配置的ckpt_callback中的save_dir的值,默认为ckpt_dir。
4.4 量化模型精度验证
量化训练完成后,通过运行以下命令进行量化模型的精度验证:
qat模型的精度验证对象为插入伪量化节点后的模型(float32);quantized模型的精度验证对象为定点模型(int8),验证的精度是最终的int8模型的真正精度,这两个精度应该是十分接近的。
验证完成后,会在终端输出qat模型和定点模型在验证集上的精度,格式见3.3。
4.5 仿真精度验证
除了上述模型精度验证之外,我们还提供仿真“hbm”模型上板的精度验证方法,可以通过下面的命令完成:
验证完成后,会在终端输出仿真上板的精度,格式见3.3。
4.6 量化模型编译
在量化训练完成之后,可以使用“compile_perf.py”脚本将量化模型编译成可以板端运行的“hbm”模型,同时该工具也能预估模型在BPU上的运行性能,“compile_perf”脚本使用方式如下:
opt为优化等级,取值范围为0~3,数字越大优化等级越高,编译时间也会越长;
可以指定--out_dir为编译后产出物的存放路径,默认在ckpt_dir的compile文件夹下。
5 其他工具
5.1 导出ONNX模型
我们提供将定点模型导出为ONNX格式的脚本,使用方法如下:
运行结束会在ckpt_dir文件夹下生成产物qat.onnx。
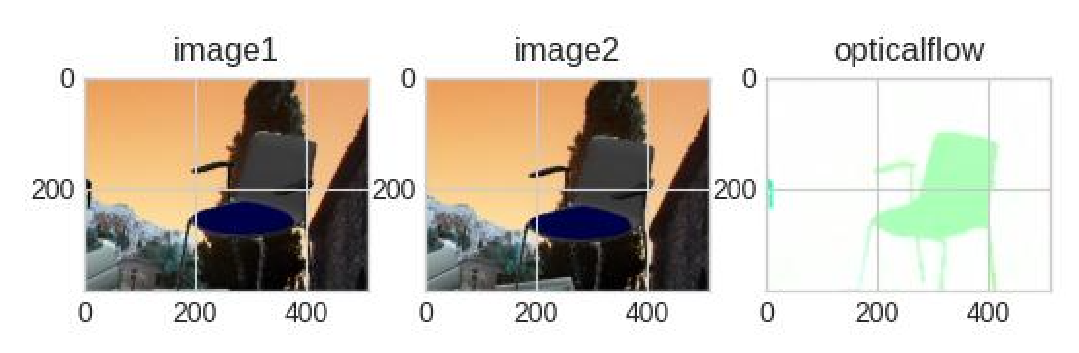
5.2 结果可视化
然后运行以下命令即可:
--save-path:可视化结果保存路径
可视化示例:


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)