
前言
一、基础介绍
在PTQ模型后量化过程中,通常情况下造成精度损失的主要原因可能有以下几点:
敏感节点量化问题。模型中的一部分节点对量化比较敏感会引入较大误差;
节点量化误差累积问题。模型中各个节点的量化误差累积导致模型整体出现较大的校准误差,主要包含:权重量化导致的误差累积、激活量化导致的误差累积以及全量量化导致的误差累积。
针对上述情况,地平线工具链提供的精度Debug工具将协助用户自主定位模型量化过程中产生的精度问题,对校准模型进行节点粒度的量化误差分析并快速定位出现精度异常的节点。PTQ精度Debug工具提供的功能包括:
获取节点量化敏感度;
获取模型累积误差曲线;
获取指定节点的数据分布;
获取指定节点输入数据通道间数据分布箱线图等。
1、基本流程
使用精度Debug工具进行精度Debug的基本流程为:
- 校准模型和校准数据的准备。校准模型在模型转换过程中为常态化保存,无需用户额外操作,为模型转换的输出目录model_output下的calibrated_model;校准数据的保存需要用户在Yaml文件中的模型参数组中增加如下参数配置(配置后精度Debug功能同时开启,但需要用户重新编译一次模型,编译等级可以配置为O0以减少编译时间):
- 通过import horizon_nn.debug as dbg导入Debug模块(使用命令行则无需导入),加载校准模型和校准数据;
通过精度Debug工具提供的API或者命令行,对精度损失明显的模型进行分析。详细的流程以及分析见后文。
2、校准数据
3、校准模型
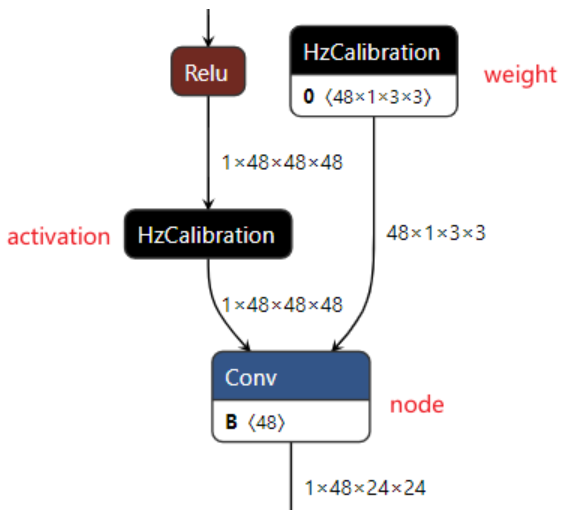
校准模型(calibrated_model.onnx)是将在校准阶段计算得到的每个被量化节点的量化参数保存在校准节点中,从而得到的模型。模型转换过程中,模型转换工具将浮点模型进行结构优化后,通过校准数据计算得到每个节点对应的量化参数并将其保存在校准节点中,形成了校准模型。因此校准模型是一种中间产物,主要特点是模型中包含校准节点,校准节点的节点类型为HzCalibration。校准节点主要分为两类:
激活(activation)校准节点。激活校准节点的输入是当前节点的上一个节点的输出,并基于当前激活校准节点中保存的量化参数对输入数据进行量化和反量化后输出;
权重(weight)校准节点。权重校准节点的输入是模型的原始浮点权重,并基于当前权重校准节点中保存的量化参数对输入的原始浮点权重进行量化和反量化后输出。
除了上述的校准节点,校准模型中的其他节点称为普通节点(node),普通节点的类型包括:Conv、Mul和Add等。下图直观地展示了校准节点和普通节点在校准模型中扮演的角色:
二、一键运行
注意:因涉及ONNXRuntime版本问题,使用GPU加速计算仅作为尝试,如遇报错,建议回退CPU进行计算。
使用方法:
1、API使用
2、命令行使用
可通过hmct-debugger runall -h/--help查看相关参数。
3、参数介绍
4、执行顺序
PTQ Debug工具各个功能的运行顺序如下:
分别获取权重校准节点和激活校准节点的量化敏感度;
根据step1的结果,分别取权重校准节点的top5和激活校准节点的top5绘制其数据分布;
针对step2获取的节点,分别绘制其通道间数据分布的箱线图;
绘制分别只量化权重和只量化激活的累积误差曲线。
注:当指定node_type='node'时,工具会获取top5节点,并分别找到每个节点对应的校准节点,并获取其校准节点的数据分布和箱线图。
Debug分析:
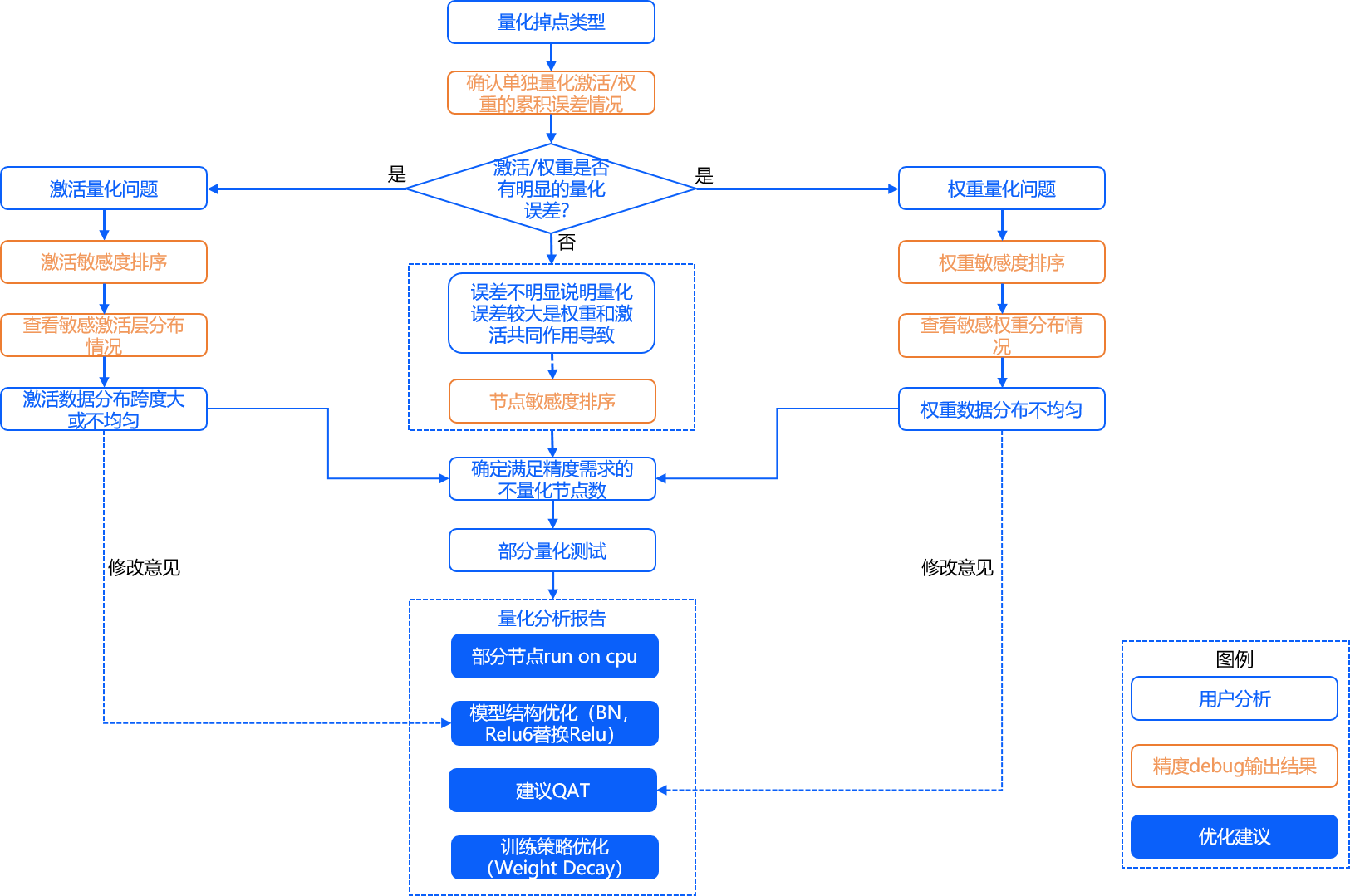
PTQ Debug分析的流程如下所示:
首先根据累积误差曲线判断模型量化掉点是由激活量化导致的还是由权重量化导致的,确定是激活量化问题还是权重量化问题。如果激活和权重的单独量化误差不明显,可以判断是两者共同作用导致的。
对于激活量化问题,根据激活节点的量化敏感度排序确定敏感节点;对于权重量化问题,根据权重节点的量化敏感度排序确定敏感节点;对于激活和权重量化问题,计算普通节点的量化敏感度并排序,确定敏感节点。
- 获取量化敏感节点后,进行部分节点以较高精度量化或部分节点不量化测试。在J5工具链上,可以对敏感节点设置Int16量化,Int16量化调优工具的使用参考社区文章PTQ精度调优手段—设置Int16量化,同时也可以让敏感节点run_on_cpu。XJ3工具链暂不支持用户手动设置节点以Int16精度量化,可以让敏感节点run_on_cpu。
同时还可以根据敏感节点数据分布直方图以及通道间数据分布的箱线图来明确优化方向,例如激活敏感节点数据分布不均匀则可以通过优化模型结构来改善,权重敏感节点数据分布不均匀则建议使用QAT等。
三、功能详解
接下来将针对PTQ精度Debug工具提供的功能和对应的API或命令行使用方法,逐一进行详解。
1、获取累积误差曲线
通过只量化浮点模型中的某一个节点,并依次计算该模型中每个节点与浮点模型中节点输出的误差,获得累积误差曲线。
API使用方法:
命令行使用方法:
可通过hmct-debugger plot-acc-error -h/--help查看相关参数。
参数介绍:
配置方式与Debug结果分析:
- 指定单节点量化/不量化:
如下配置意为分别只量化Conv_2和Conv_90并保持其他节点不量化,计算累积误差曲线;
或分别解除量化Conv_2和Conv_90并保持其他节点量化,计算累积误差曲线。
API配置方式为:quantize_node=['Conv_2', 'Conv_90']/non_quantize_node=['Conv_2', 'Conv_90']
命令行配置方式为:-q ['Conv_2', 'Conv_90']/-nq ['Conv_2', 'Conv_90'] - 指定多个节点量化/不量化:
如下配置意为分别只量化Conv_2以及只量化Conv_2和Conv_90并保持其他节点不量化,计算累积误差曲线;
或分别解除量化Conv_2以及解除量化Conv_2和Conv_90并保持其他节点量化,计算累积误差曲线。
API配置方式为:quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']]/non_quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']]
命令行配置方式为:-q [['Conv_2'], ['Conv_2', 'Conv_90']]/-nq [['Conv_2'], ['Conv_2', 'Conv_90']] 按照量化敏感度排序选择节点量化/不量化:
注:non_quantize_node设置不量化的节点等价于让其运行在CPU上。
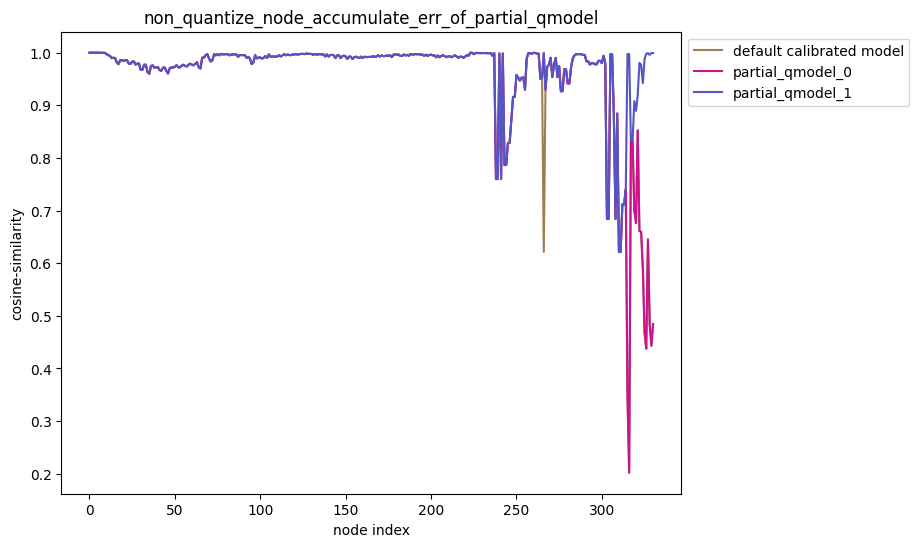
测试部分量化精度时,可以按照量化敏感度排序进行多组量化策略的精度对比,此时可以参考以下用法:
针对部分量化精度分析的累积误差曲线图,在分析时,用户应当更关注模型输出位置(曲线尾部)的量化相似度,例如下图,qmodel_1模型的精度要好于qmodel_0:
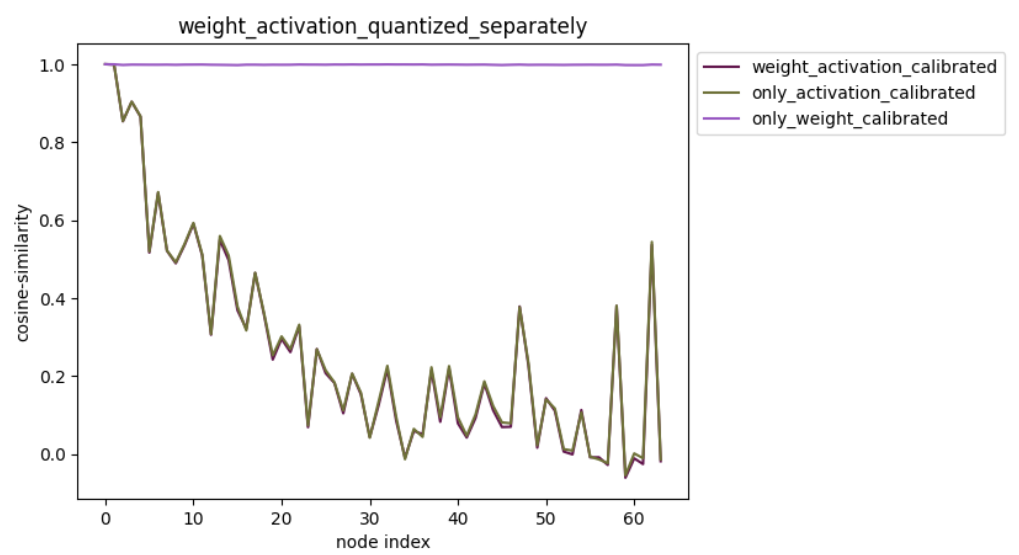
- 指定激活节点/权重节点分别量化:
如下配置意为分别只量化权重节点和激活节点并保持其他节点不量化,计算累积误差曲线。
API配置方式为:quantize_node=['weight', 'activation']
命令行配置方式为:-q ['weight', 'activation']可视化结果:
通过下图可以分析出激活节点量化引入了大量的量化累积误差,而权重节点量化对模型精度无负面影响。
2、获取节点量化敏感度
API使用方法:
命令行使用方法:
可通过hmct-debugger get-sensitivity-of-nodes -h/--help查看相关参数。
参数介绍:
Debug结果分析:
此外,调用API时,API还将以字典格式(Key为节点名称,Value为节点的量化敏感度信息)返回节点量化敏感度信息,以供用户后续使用,返回格式如下:
量化敏感度保存与加载:
由于模型的量化敏感度在PTQ精度Debug过程中扮演着重要的角色,累积误差曲线的计算分析中会用到,因此建议用户及时保存模型量化敏感度,直接加载以节省时间,可以参考如下代码进行量化敏感度的保存与加载:
注意:命令行暂时无法手动保存量化敏感度。
3、获取节点数据分布
指定节点,分别获取该节点在浮点模型和校准模型中的输出,得到输出数据分布。另外,将两个输出结果做差,获取两个输出之间的误差分布。
API使用方法:
命令行使用方法:
可通过hmct-debugger plot-distribution -h/--help查看相关参数。
参数介绍:
Debug结果分析:
可视化结果:
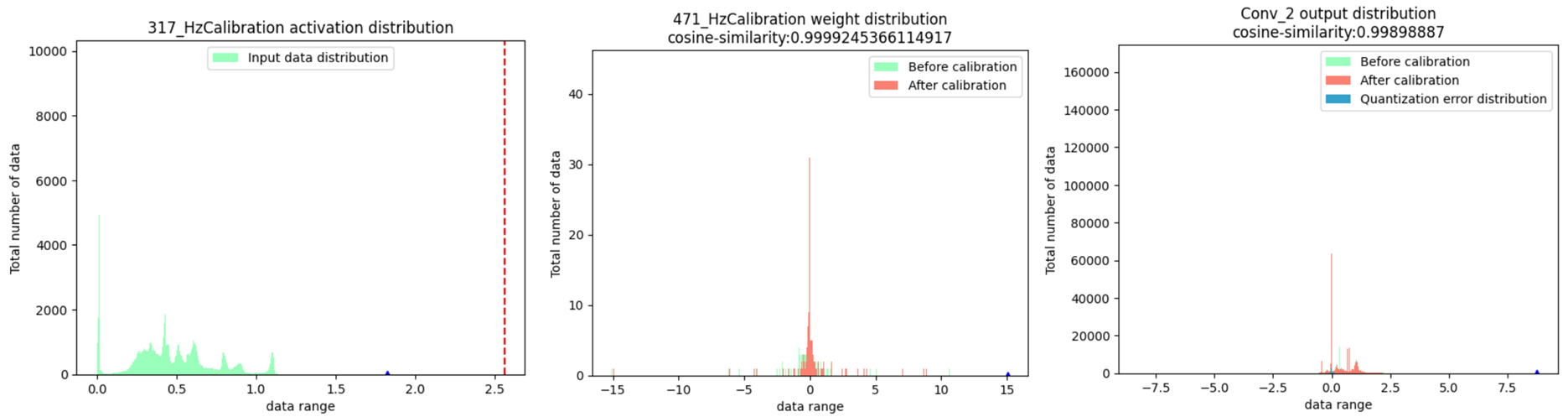
注:蓝色三角表示数据绝对值的最大值;红色虚线表示最大的校准阈值。
数据分布结果的分析标准为是否满足对量化友好的正态分布,只要分布中有一个很明显的单峰就认为满足正态分布,不需要严格满足正态分布公式,例如可视化结果中的第一张图,输入数据分布相对比较集中,对于激活节点而言输入数据分布是友好的;同理第二张图校准前后权重节点的数据分布也是友好的。第三张图是普通节点校准前后的输出数据分布以及量化误差分布,也符合正态分布,当节点输出不符合正态分布时,用户可以尝试在模型中增加BatchNorm层并重新训练,然后再进行PTQ量化。
4、获取节点通道间数据分布
绘制指定校准节点输入数据通道间数据分布的箱线图。
API使用方法:
命令行使用方法:
可通过hmct-debugger get-channelwise-data-distribution -h/--help查看相关参数。
参数介绍:
Debug结果分析:
可视化结果:

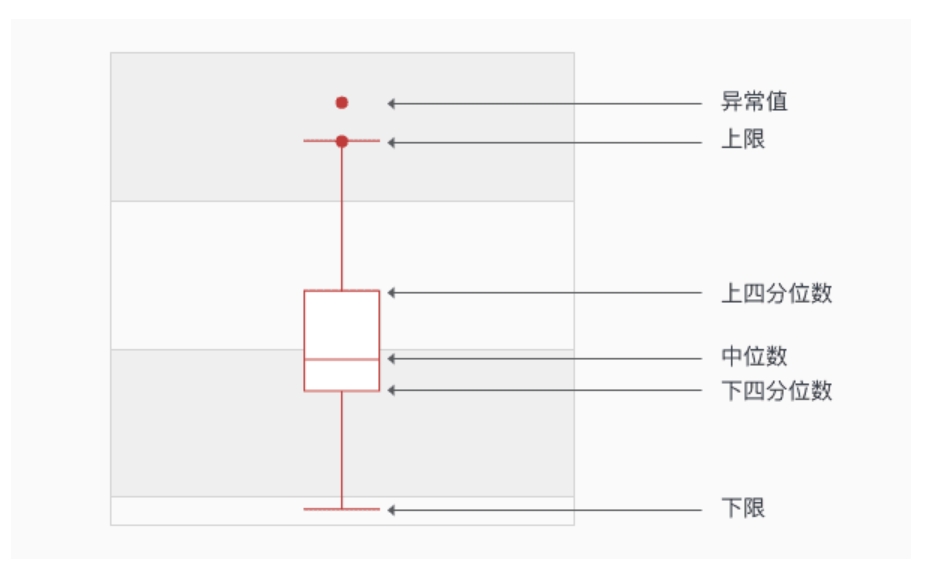
注:横坐标表示节点输入数据的通道数;纵坐标表示每个channel的数据分布范围,其中红色实线表示该channel数据的中位数,蓝色虚线表示均值。
通过箱线图可以直观地了解当前数据每个通道之间的数据分布情况。通过观察箱线图纵坐标确认数据分布范围,当某一个通道有异常值时(即数值极大或极小,例如上图中第21通道),认为当前节点采用per-tensor量化会有较大的量化风险,需要尝试使用per-channel量化去减少量化误差。箱线图的阅读可以参考下图:
四、实例参考
我们还提供了三篇社区文章,来展示如何在具体模型上使用PTQ Debug工具进行分析:


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)