
0 概述
多目标跟踪是在视频序列的每一帧中定位所有的目标并确定它们的移动轨迹的任务。因为每帧中的目标都可能因为环境的变化而被遮挡,而且跟踪器要想进行长期跟踪或者低帧率的跟踪是比较困难的,所以多目标跟踪是极具挑战性的任务。MOTR(Multiple-Object Tracking with Transformer)能够学习建模目标的长时间变化,隐式地进行时间关联。基于Transformer和DETR,MOTR引入了track query这个概念,一个track query负责建模一个目标的整个轨迹,它可以在视频帧间传递和更新,从而无缝地完成目标检测和跟踪任务。本文为多目标跟踪算法MOTR的算法介绍和使用说明。
该示例为参考算法,仅作为在J5上模型部署的设计参考,非量产算法
1 性能精度指标
MOTR模型配置:
数据集 | Input shape | backbone | head | post-process | 跟踪目标最大数量 | 检测类别 |
|---|---|---|---|---|---|---|
mot17 | 1x3x800x1422 | efficientnetb3 | MotrHead | MotrPostProcess | 256 | 行人 |
性能精度表现:
infer/ms | post-process/ms | 双核FPS | 精度(MOTA) |
|---|---|---|---|
26.96 | 22.84 | 73.98 | 浮点:58.02 量化:57.76 |
2 模型介绍
2.1 模型优化点
相对于公版实现,地平线对MOTR的模型结构和训练策略做了如下优化:
2.1.1 模型结构优化
将backbone从ResNet50更换到efficientnetb3, 兼顾模型精度和推理性能;
优化query维度, 模型中将query全部有二维优化为4维进行计算, 便于性能提升;
模型中的linear全部替换为conv2d,便于性能提升;
deformable attention优化:
输入采用四维的数据,避免了flatten+reshape的重复计算;
将每个注意力头的采样点数量由4个减少到1个,并且用sigmoid替换softmax, 便于性能提升(精度基本上不变);
Track query个数由300降低到256, 便于性能提升;
引入padding query和mask query, 解决动态shape问题。
2.1.2 训练策略优化
- 引入了DAB-DETR的anchor-box,直接将box的坐标作为queries输出到DeformableTransformer的解码器中,加速模型收敛和提升精度;
- 引入了DINO的look forward twice, 利用后一层的改进的box信息校正前一层的box预测,优化梯度传播,提升预测精度。
2.2 模型结构
MOTR的输入为图像序列,输出为跟踪目标的位置信息和类别信息。MOTR的总体架构和过程如下图所示,主要由以下部分组成:
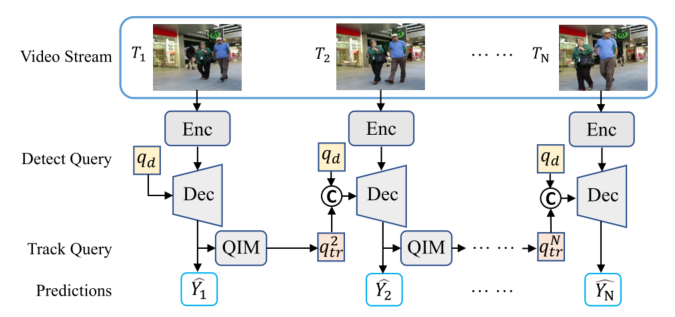
- Enc: 由backbone(efficientnetb3)和Deformable DETR encoder组成,用来提取每帧图像的特征;
- Dec: 由Deformable DETR decoder组成,用来生成bounding box 预测的隐藏状态。对于第一帧,不存在跟踪查询qtrq_{tr}qtru200b,因此只将固定长度的检测查询qdq_dqdu200b和手工生成的fake跟踪查询输入到Dec中;对于连续帧,模型会将来自前一帧的跟踪查询和可学习的检测查询输入到Dec中。更新检测查询和跟踪查询的过程如下所示:
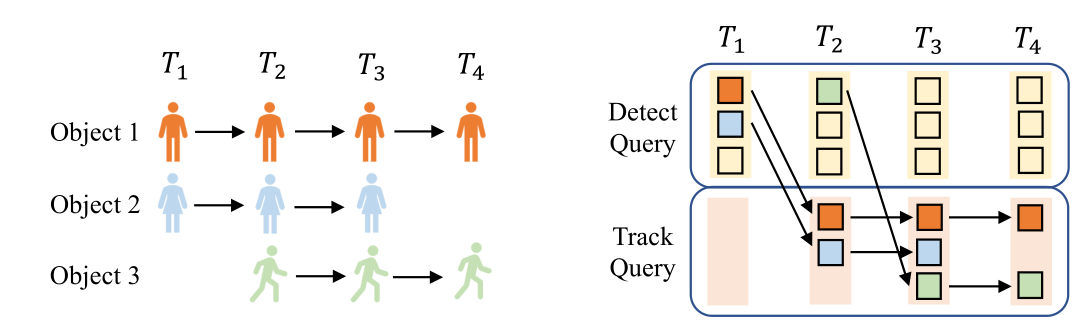
Track Query是动态更新的,而且长度是可变的。首先将Track Query初始化为空,然后使用Detect Query检测新生目标,将所有检测到的目标的隐藏状态连接起来,从而生成下一帧的Track Query,,终止目标的Track Query则将从Track Query集中删除。 - Query Interaction Module(QIM):QIM将Dec生成的box的隐藏状态作为输入,并为下一帧生成跟踪查询。QIM包括目标进出机制和时间聚合网络(Temporal Aggregation Network ,TAN)。目标进出机制用来解决新生目标和终止目标的问题;TAN增强了时间关系建模,并为跟踪目标提供上下文先验。
2.3 源码说明
2.3.1 config文件
model = dict(
type="Motr",
backbone=dict(
type="efficientnet",
model_type="b3",
...
),
head=dict(
type="MotrHead",
transformer=dict(
type="MotrDeformableTransformer"
),...
),
criterion=dict(
type="MotrCriterion",
),
post_process=dict(
type="MotrPostProcess",
),
track_embed=dict(
type="QueryInteractionModule",
),
)
test_model = copy.deepcopy(model)
deploy_model = dict(
type="Motr",
backbone=dict(
type="efficientnet",
...
),
head=dict(
type="MotrHead",
transformer=dict(
type="MotrDeformableTransformer",
...)
track_embed=dict(
type="QueryInteractionModule",
),
compile_motr=True,
)
type=torch.utils.data.DataLoader,
dataset=dict(
type="Mot17Dataset",
... ),
)
val_data_loader = dict(
type=torch.utils.data.DataLoader,
dataset=dict(
type="Mot17Dataset",
)
#trainer配置
float_trainer = dict()
calibration_trainer = dict()
qat_trainer = dict()
int_infer_trainer = dict()
#编译配置
compile_dir = os.path.join(ckpt_dir, "compile")
compile_cfg = dict(
march=march,
name="motr",
out_dir=compile_dir,
hbm=os.path.join(compile_dir, "model.hbm"),
layer_details=True,
input_source=["pyramid", "ddr", "ddr", "ddr"],
opt="O3",
)
# predictor配置
float_predictor = dict()
qat_predictor = dict()
calibration_predictor=dict()
int_infer_predictor = dict()
注: 如果需要复现精度,config中的训练策略最好不要修改,否则可能会有意外的训练情况出现。
2.3.2 Backbone
MOTR参考算法采用与硬件比较友好的efficientnetb3作为backbone来提取图像多尺度特征,提升了模型的精度。efficientnetb3的网络结构如下所示:
2.3.3 MotrHead
MOTR通过efficientnetb3和Deformable Transformer Encoder提取图像序列特征。对于第一帧图像,由于不存在跟踪查询,所以将固定长度的可学习检测查询和padding后的fake跟踪查询输入到Deformable Transformer Decoder。对于连续帧,将来自前一帧的跟踪查询和可学习的检测查询输入到解码器中,这些查询与解码器中的图像特征交互,生成用于边界框预测的类别classes、坐标coords和hs,然后输入到查询交互模块(QIM)中,来生成下一帧的跟踪查询。
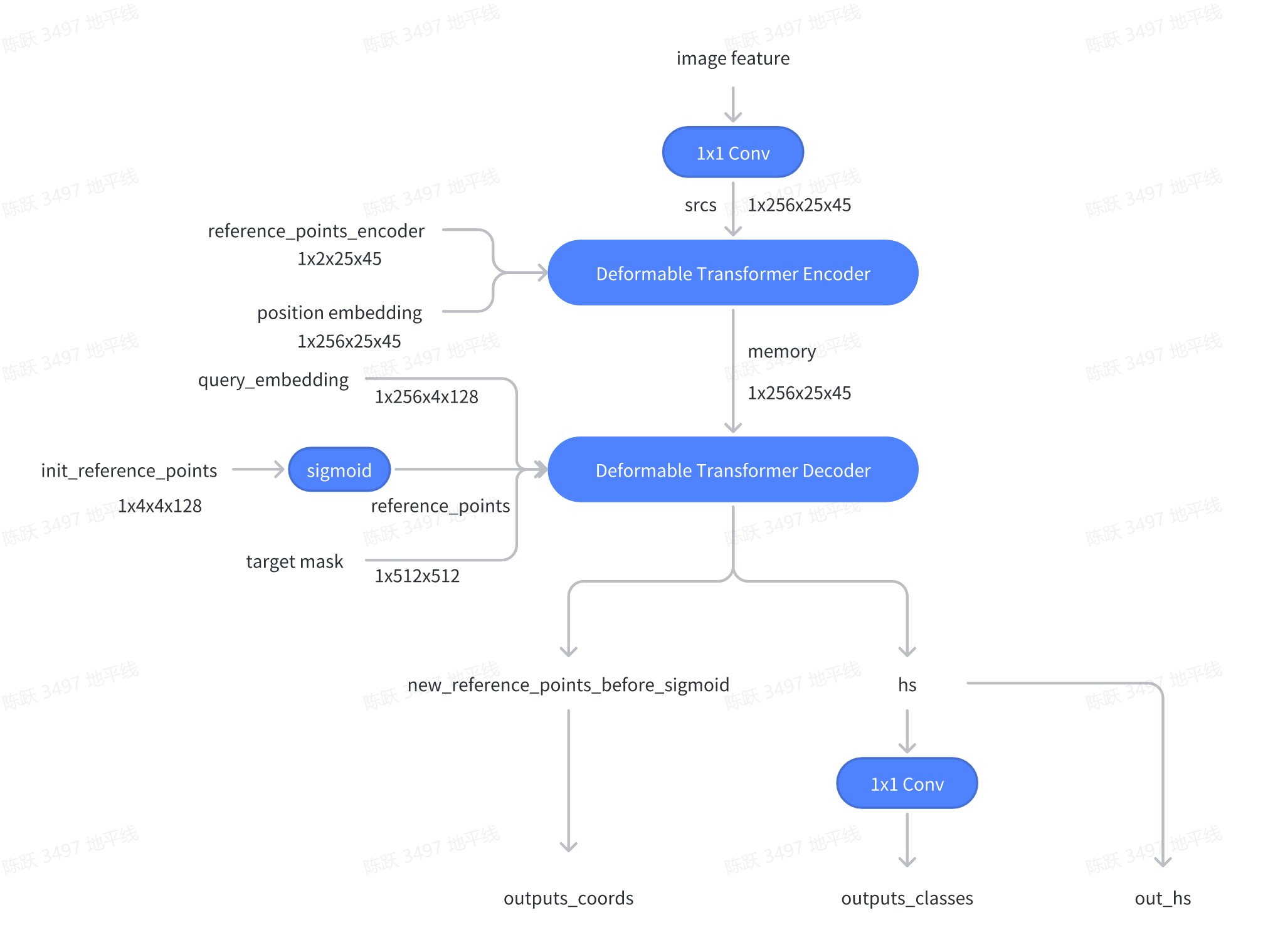
/usr/loacal/lib/python3.8/dist-packages/hat/models/task_modules/motr/motr_deformable_transformer.py
Track instance 初始化
对于首帧图像,我们生成了值全为0的track instance用于目标padding, 初始化过程如下所示 :
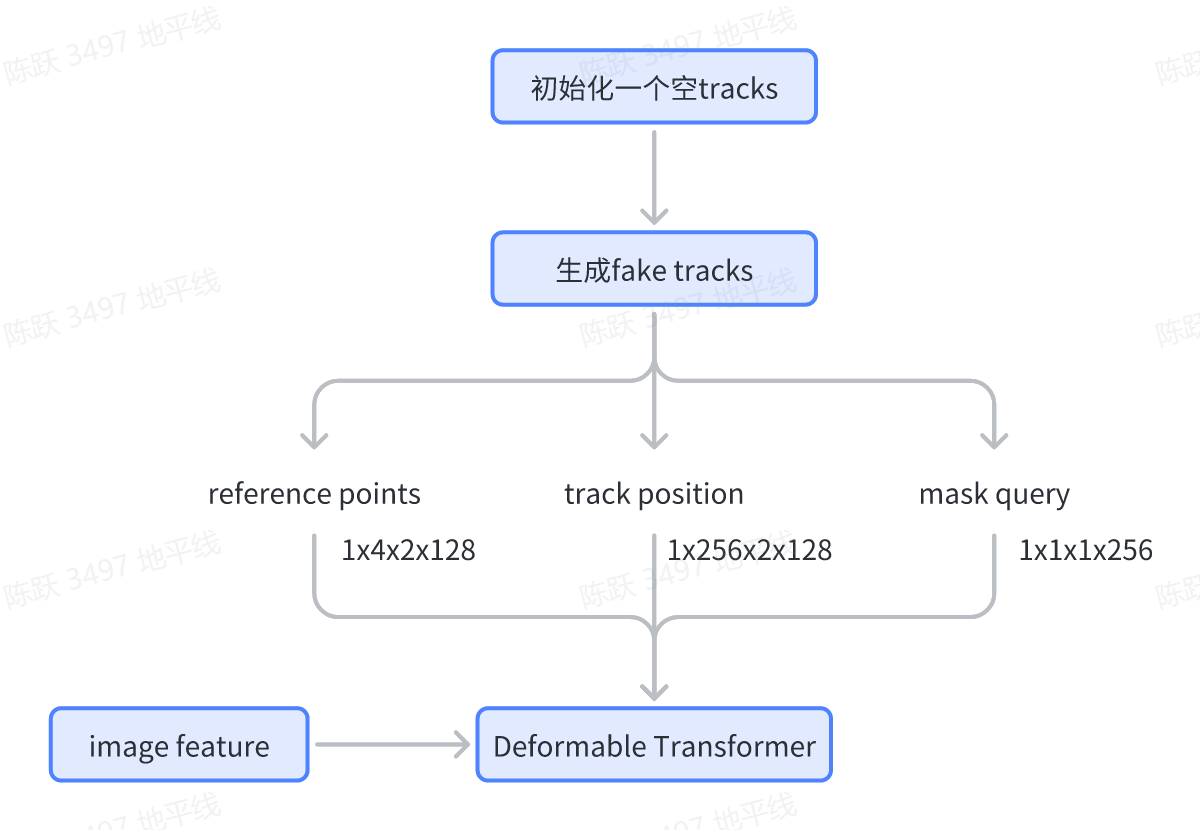
相关代码如下所示:
Deformable Transformer Encoder
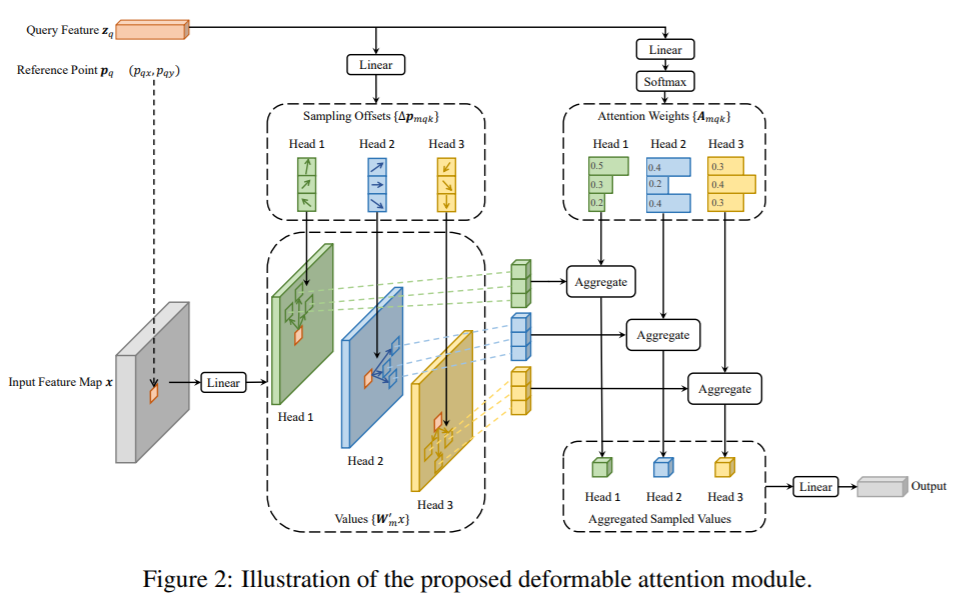
Deformable Transformer Encoder的基本组成结构为DeformableTransformerEncoderLayer,它主要由self attention层、LayerNorm层和ffn(feedforward neural network)层组成,这里需要注意的是:为了性能优化,Deformable Attention采样点数量都由公版的4个减少到1个,并且用sigmoid替换softmax。 如下为结构示意图:
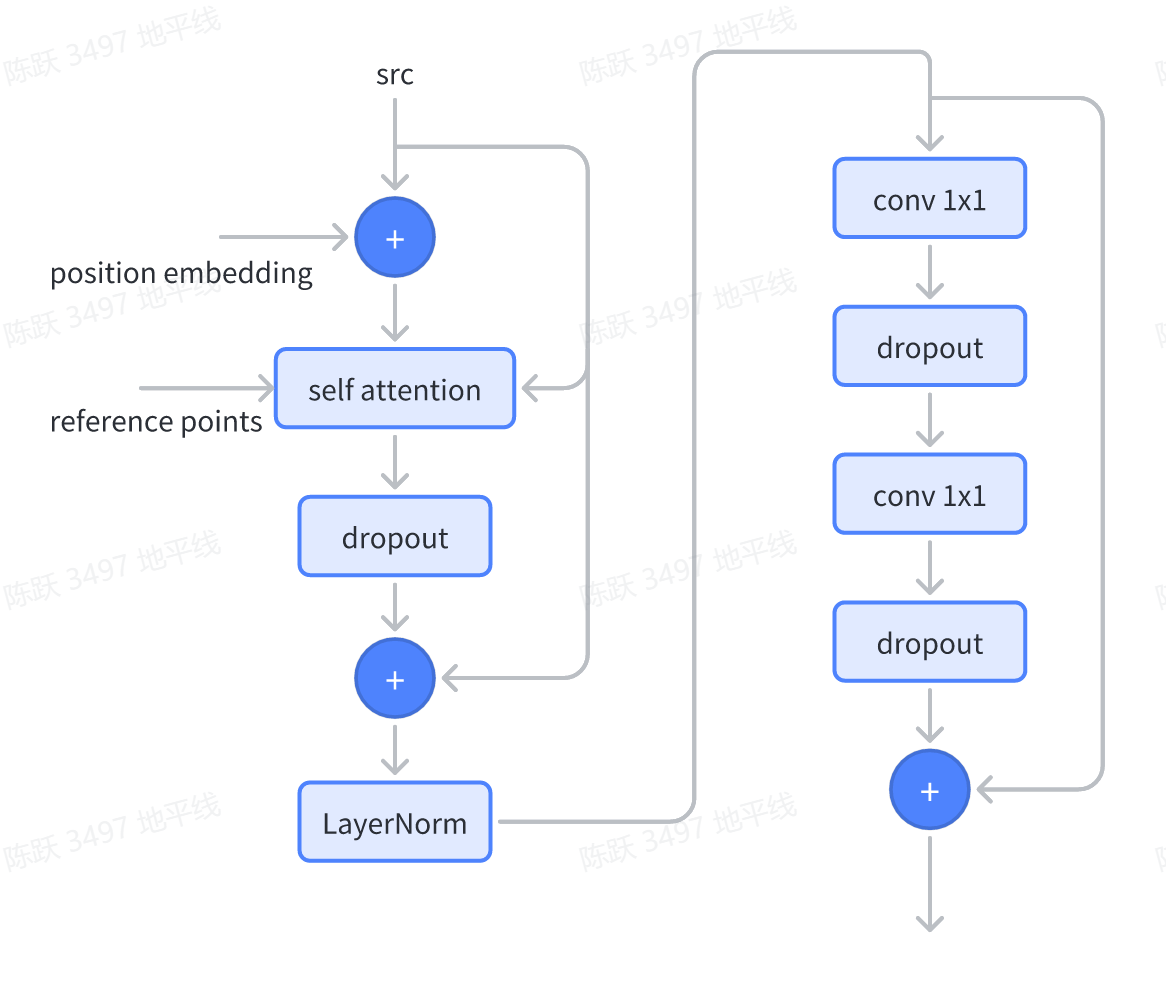
相关代码:
Deformable Transformer Decoder
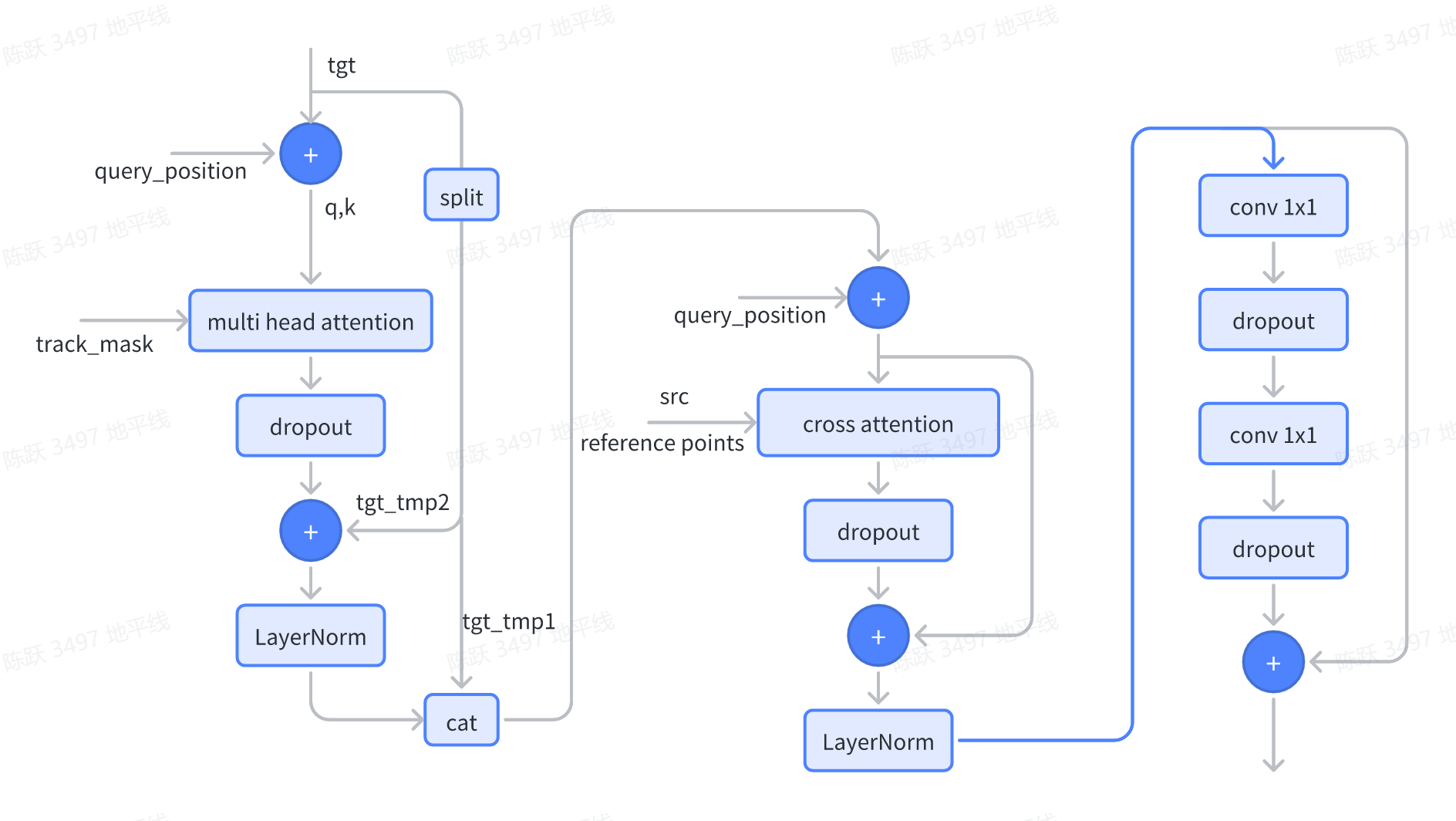
相关代码如下所示:
2.3.4 Post Process
MotrHead输出了目标的类别信息classes、bbox信息和decoder的中间结果hs,将这些结果进行处理后,然后再输入到QIM模块,相关过程如下所示:
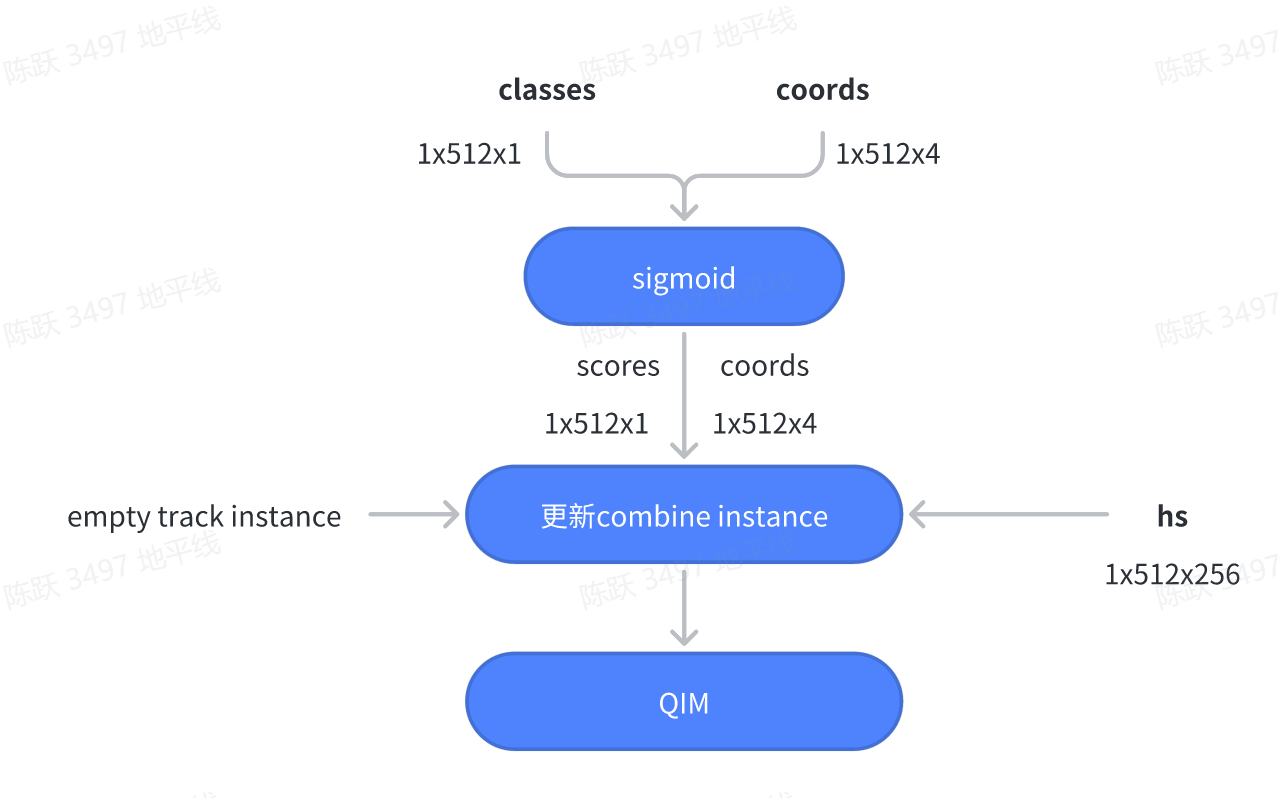
相关代码如下所示:
查询交互模块(query interaction module,QIM)包括目标进出机制和时间聚合网络(TAN)。QIM的结构如下图所示:
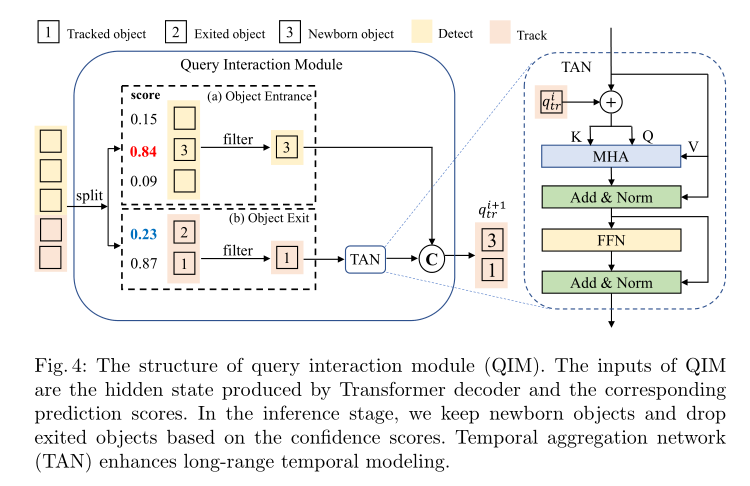
目标进出机制
对应代码:
对于跟踪查询,删除连续5帧的分类分数低于阈值的预测,同时保留其他隐藏状态,对应代码如下所示:
/usr/loacal/lib/python3.8/dist-packages/hat/mode/task_modules/motr/motr_utils.py
时间聚合网络
相关代码如下所示:
3 浮点模型训练
3.1 Before Start
3.1.1 发布物及环境部署
step2:解压发布包
解压后文件结构如下:
step3:拉取docker环境
release_models获取路径见:horizon_model_train_sample/scripts/configs/track_pred/README.md
3.1.2 数据集准备
3.1.2.1 数据集下载
由于官方的测试集无gt,因此我们将训练集拆成一半,每个视频前一半帧作为训练集,后一半帧作为验证集。 OE开发包中提供了脚本将训练集拆分,只需要运行下面的脚本:
--src-data-path为解压后的原始数据集路径;--out-dir为拆分后的数据集存储路径。
运行完上面脚本后,将会得到如下结构的文件夹:
然后使用以下命令将训练数据集和验证数据集打包,格式为lmdb:
--src-data-dir为拆分后后的mot17数据集目录;
--target-data-dir为打包后数据集的存储目录;
验证精度时,需要用到验证数据集的标签数据,因此我们做一个软连接,如下所示:
train_lmdb和test_lmdb就是打包之后的训练数据集和测试数据集,也是网络最终读取的数据集:
3.1.3 config文件配置
ckpt_dir :浮点、calib、量化训练的权重路径配置,权重下载链接在config文件夹下的README中;
device_ids 、train_batch_size_per_gpu 、test_batch_size_per_gpu :根据实际硬件配置进行device_ids和每个gpu的batchsize的配置;
train_lmdb: 3.1.2.2中打包的训练集路径配置;
val_lmdb : 3.1.2.2中打包的验证集路径配置;
val_gt : 3.1.2.2中生成的test_gt路径;
float_trainer下的checkpoint_path:浮点训练时backbone的预训练权重路径。
3.2 浮点模型训练
configs/track_pred/motr_efficientnetb3_mot17.py文件中的参数配置完成后,使用以下命令训练浮点模型:
float训练后模型ckpt的保存路径为config配置的ckpt_callback中save_dir的值,默认为ckpt_dir。
3.3 浮点模型精度验证
浮点模型训练完成以后,可以使用以下命令验证已经训练好的浮点模型精度:
4. 模型量化和编译
4.1 Calibration
模型完成浮点训练后,便可进行 Calibration。calibration在forward过程中通过统计各处的数据分布情况,从而计算出合理的量化参数。 通过运行下面的脚本就可以开启模型的Calibration过程:
4.2 Calibration 模型精度验证
Calibration完成以后,可以使用以下命令验证经过calib后模型的精度:
模型经过 Calibration 后的量化精度若已满足要求,便可直接进行转定点模型的步骤,否则需要进行量化训练进一步提升精度。
4.3 量化训练
MOTR经过 Calibration 后的量化精度未能满足要求,所以需要使用以下命令进行量化训练:
4.4 qat模型精度验证
量化训练完成后,通过运行以下命令验证qat模型的精度:
4.5 量化模型精度验证
通过运行以下命令验证量化模型的精度:
4.6 仿真上板精度验证
除了上述模型验证之外,我们还提供和上板完全一致的精度验证方法,可以通过下面的方式完成:
4.7 3.7 量化模型编译
opt为优化等级,取值范围为0~3,数字越大优化等级越高,编译时间更长,但部署性能更好;
compile_perf脚本将生成.html文件和.hbm文件(out-dir目录下),.html文件为BPU上的运行性能,.hbm文件为上板实测文件;
两次编译的--out_dir最好不要设置为同一个文件夹,不然会出现编译产出物被覆盖的情况。
运行后,out-dir的目录下会产出以下文件:
5.其他工具
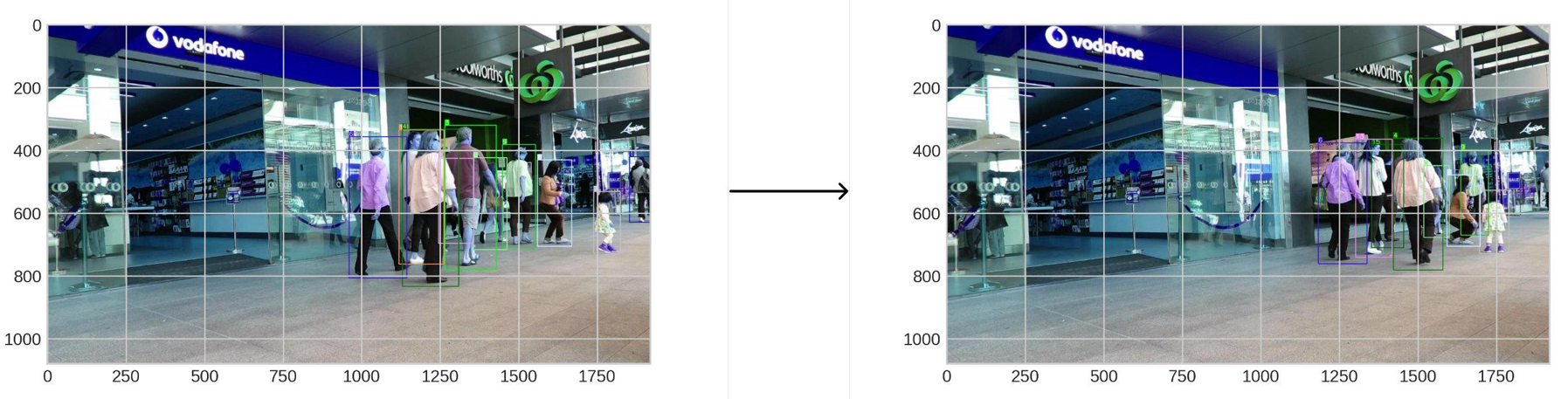
5.1 结果可视化
如果您想查看知道图像序列的多目标跟踪结果,tools目录下提供了多目标跟踪和可视化的脚本infer.py, 脚本运行方式如下:
1。 --save-path:可视化结果保存路径;
2.通过修改config文件中infer_cfg字段中的imagedir和num参数来配置图像序列根目录和图像帧数量。
可视化示例:
6.板端部署
模型编译成功后,可以在板端使用hrt_model_exec perf工具评测hbm模型的FPS,参考命令如下:
命令运行结束后,会在本地会产出profile.log和profile.csv日志文件,用以分析算子耗时和调度耗时。
6.2 AI Benchmark示例
OE开发包中提供了MOTR的AI Benchmark示例,用以在板端进行性能和精度的评测,ddk/samples/ai_benchmark/j5/qat/script/tracking/motr 目录下提供了三个评测脚本:
fps.sh:实现多线程fps统计(多线程调度,用户可以根据需求自由设置线程数);
latency.sh:实现单帧延迟性能统计,包含模型推理和后处理延迟(单线程,单帧);
- accuracy.sh:用于精度评测。
AI Benchmark示例需要使用交叉编译工具编译后,然后将文件夹传输到板端运行,建议在docker中进行交叉编译流程。执行ddk/samples/ai_benchmark/code/ 目录下的build_qat_j5.sh脚本即可一键编译真机环境下的可执行程序:
编译完成后,将ai_benchmark/j5/qat文件夹拷贝至板端:
然后在板端执行qat/script/tracking/motr文件夹下的评测脚本。进入到需要评测的模型目录下,运行latency.sh 即可测试出单帧延迟, 如下所示:
终端输出的延迟包含模型推理耗时(Infer latency)和后处理耗时(Post process)。
运行fps.sh 即可测试出双核多线程fps, 如下所示:


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)