
其中:
针对MobileVit_s的分析流程请参考:https://developer.horizon.ai/forumDetail/146176821770229921
针对mnasnet_1.0_96的分析流程请参考:https://developer.horizon.ai/forumDetail/146176821770229925
本文主要使用精度debug工具对repvgg_b2_deploy进行量化精度问题定位。repvgg_b2_deploy模型在 imagenet数据集的50000张图片上进行分类精度测试,在默认情况下,模型精度如下:
模型名称 | 架构 | 浮点精度 | 量化精度 |
|---|---|---|---|
repvgg_b2_deploy | bayes | 0.78788 | 0.71138(90.29%) |
量化后定点模型的精度没有达到浮点模型的99%,因此使用精度debug工具对该模型进行精度异常定位。
1. 确认单独量化权重 / 激活 的累积误差分布情况
1.1 API使用
save_dir='./', # 结果保存路径
calibrated_data='./calibration_data', # 校准数据
model_or_file='./calibrated_model.onnx', # 校准模型
quantize_node=['weight', 'activation'], # 量化节点列表,当设置为['weight','activation']时则分别只量化权重和激活
metric='cosine-similarity', # 计算误差的方式(度量方式)
average_mode=False # 是否采用平均累积误差作为输出
)
1.2 输出结果
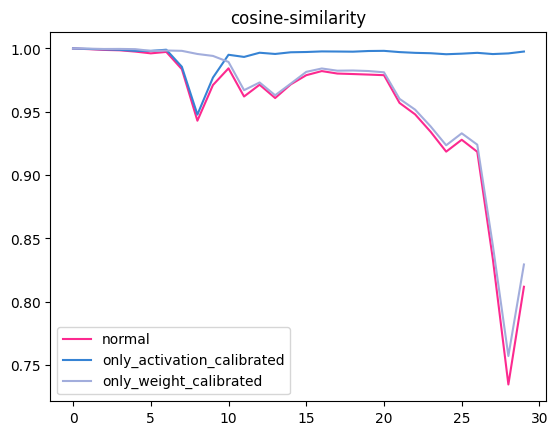
从分析结果可知,模型的量化误差主要来自于对权重的量化。
2. 权重校准节点敏感度排序
2.1 API使用
model_or_file='./calibrated_model.onnx', # 校准模型
metrics='cosine-similarity', # 计算敏感度的方式(度量方式)
calibrated_data='./calibration_data/', # 校准数据
output_node=None, # 选取模型中某个节点的输出用于计算敏感度,默认(None)则采用模型的最终输出
node_type='weight', # 节点类型
data_num=None,
verbose=True, # 是否在终端显示计算结果。True显示,反之,不显示
interested_nodes=None # 选择某些节点只计算这些节点的敏感度。默认(None)计算模型所有节点
)
2.2 输出结果
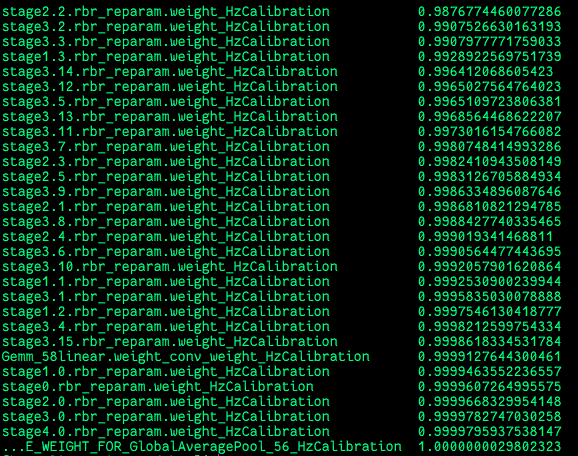
在模型所有权重校准节点中,top1节点的量化敏感度较低,小于0.99,其余节点均大于0.99。
3. 查看敏感层数据分布情况
3.1 API使用
model_or_file='./calibrated_model.onnx',
calibrated_data='./calibration_data',
nodes_list=['stage2.2.rbr_reparam.weight_HzCalibration',
'stage3.2.rbr_reparam.weight_HzCalibration',
'stage3.3.rbr_reparam.weight_HzCalibration',
'stage1.3.rbr_reparam.weight_HzCalibration',
'stage3.14.rbr_reparam.weight_HzCalibration'])
3.2 输出结果
节点名称 | 数据分布 |
|---|---|
stage2.2.rbr_reparam.weight_HzCalibration | 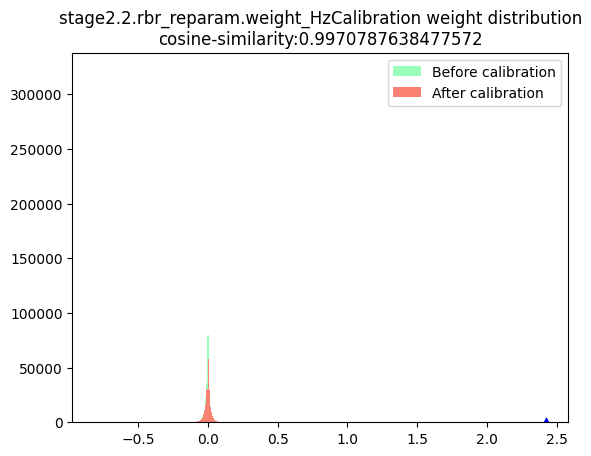 |
stage3.2.rbr_reparam.weight_HzCalibration | 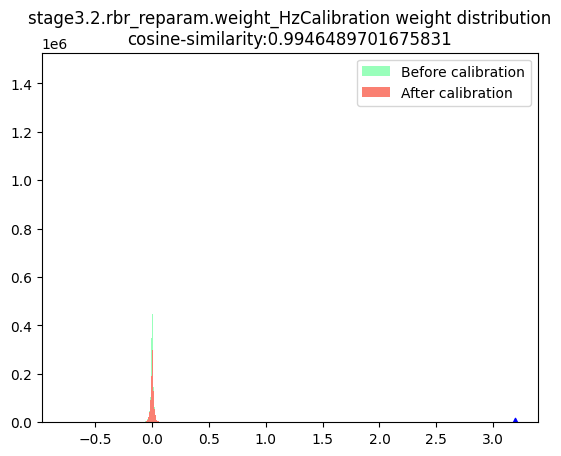 |
stage3.3.rbr_reparam.weight_HzCalibration | 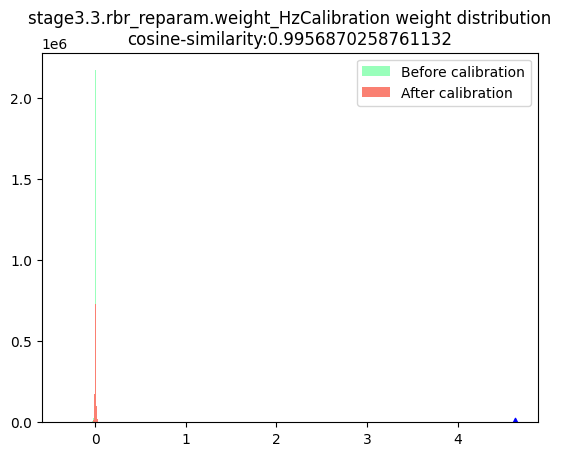 |
stage1.3.rbr_reparam.weight_HzCalibration | 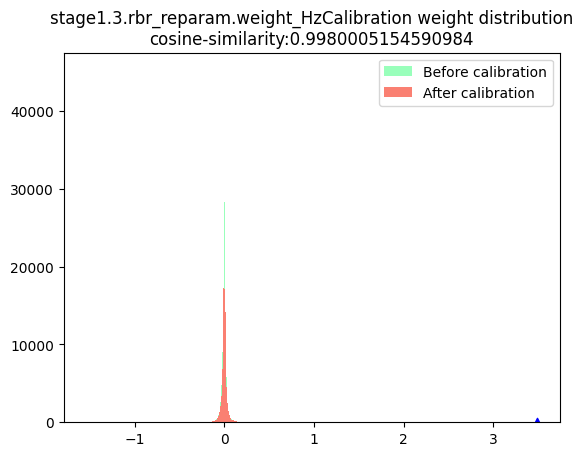 |
stage3.14.rbr_reparam.weight_HzCalibration | 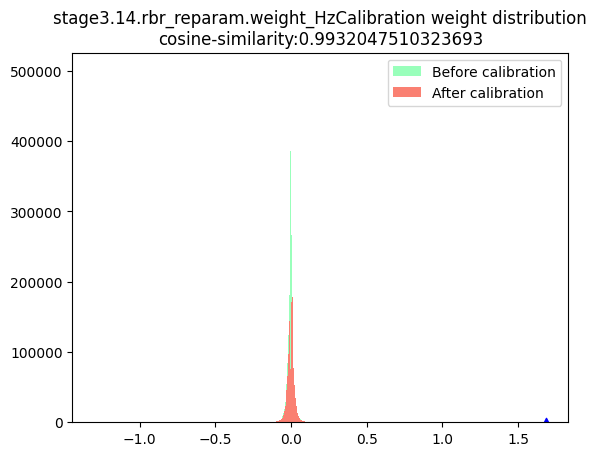 |
数据分布:数据分布的判断标准为是否满足对量化有好的正态分布,只要分布中只有一个很明显的单峰就认为满足正态分布,不需要严格满足正态分布。根据上述判断标准来看,表中节点的数据分布均满足正态分布。由于当前模型是权重量化导致的量化模型精度下降,且权重校准节点均为per-channel量化,因此不存在per-tensor量化风险,故此处不需要绘制节点数据的箱线图。
4. 部分量化性能测试
4.1 API使用
model_or_file='./calibrated_model.onnx',
metrics='cosine-similarity',
calibrated_data='./calibration_data/',
output_node=None,
node_type='weight',
data_num=None,
verbose=False,
interested_nodes=None)
nodes = list(node_message.keys())
dbg.plot_acc_error(save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
non_quantize_node=[nodes[:1], nodes[:2], nodes[:3], nodes[:4],
nodes[:5], nodes[:6], nodes[:7], nodes[:8],
nodes[:9], nodes[:10], nodes[:11], nodes[:12],
nodes[:13], nodes[:14], nodes[:15], nodes[:16],
nodes[:17], nodes[:18], nodes[:19], nodes[:20]],
metric='cosine-similarity',
average_mode=False)
4.2 测试结果
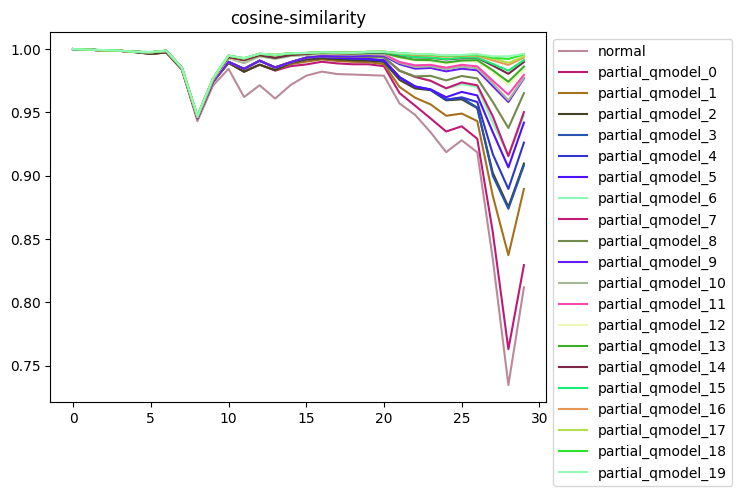
通过部分量化精度测试发现,当解除top14权重校准节点后,模型精度会有较大提升,继续增加不量化节点数量精度提升较小。因此,在此基础上进行模型部分量化精度测试。
model | 量化策略 | 浮点精度 | 校准方式 | calibrated_model |
|---|---|---|---|---|
repvgg_b2_deploy | default | 0.78788 | default_percentile_asy_perchannel | 0.71138(90.29%) |
repvgg_b2_deploy | 解除top14权重校准节点量化 | 0.78788 | default_percentile_asy_perchannel | 0.78004(99.00%) |
repvgg_b2_deploy | 解除top15权重校准节点量化 | 0.78788 | default_percentile_asy_perchannel | 0.78252(99.32%) |
5. 总结
5.1 误差原因分析
通过使用精度debug工具中的plot_acc_error分别对量化权重和量化激活的部分量化模型进行累积误差分析可知,量化权重会导致模型量化精度下降。
通过对节点量化敏感度分析发现,只有top1权重校准节点的量化敏感度小于0.99,进一步绘制其数据分布以及通道间的数据分布情况,发现数据分布符合对量化友好的正态分布,且通道间的数据分布波动不大,因此可以得出结论:导致模型量化误差的主要来源是对权重的量化,同时量化精度下降较多是由于模型各个节点的误差累积导致的。
5.2 提升精度建议
找到对量化敏感的权重校准节点对应的普通节点,并将其run on CPU。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)

