
1 前言
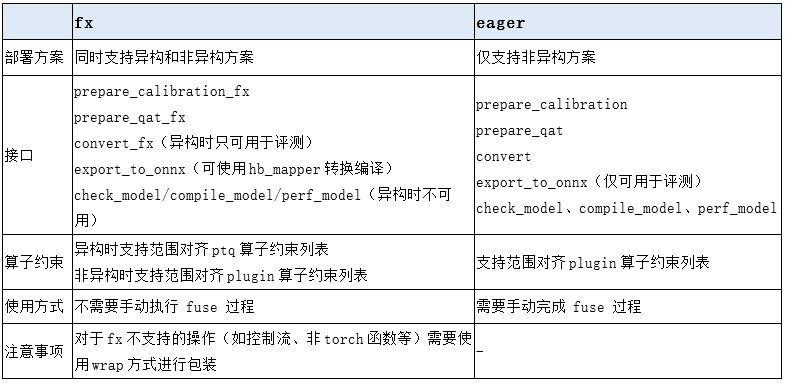
地平线基于PyTorch开发的horizon_plugin_pytorch量化训练工具(该工具将随2023年初的OE开发包释放给XJ3用户)同时支持Eager和fx两种模式。其中,fx模式是从plugin-1.0.0版本之后才开始支持的,相较于Eager方案,他们有如下不同:
2 异构&非异构方案的使用方式
异构以及非异构方案的优缺点如下图所示:
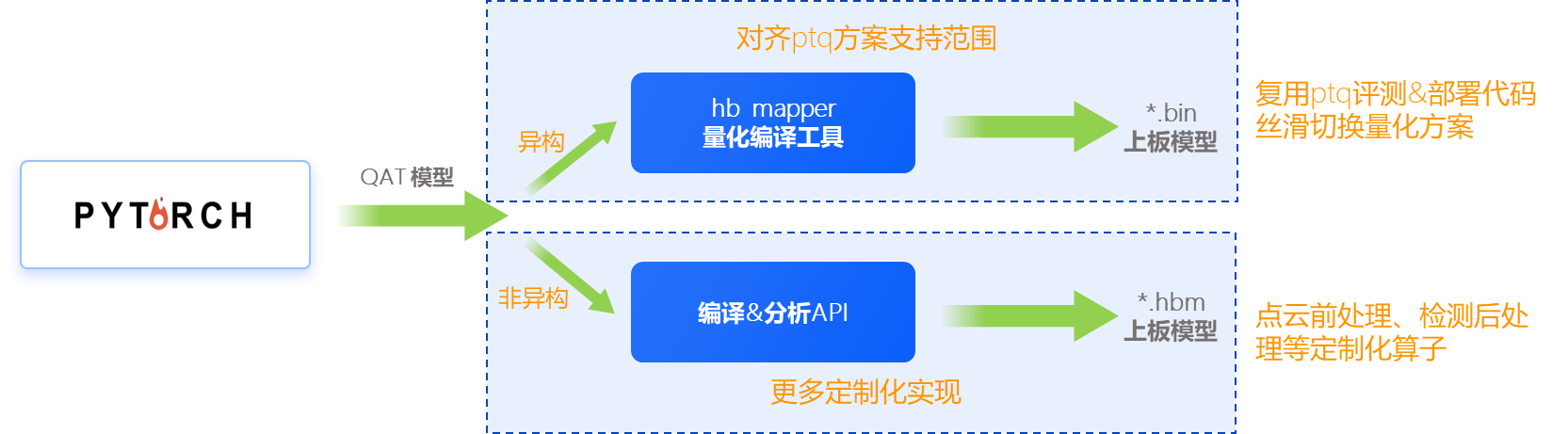
通常来说,我们只会在以下两种情形时使用异构方案:
模型中包含 BPU 不支持的算子。
模型量化精度误差过大,需要将某些算子放到 CPU 上进行高精度计算。
2.1 非异构方案
由于BPU算子性能远高于CPU算子,从性能优化的角度出发,建议您尽可能使用纯BPU算子搭建模型。
非异构方案的使用步骤大致如下:
2. 设置硬件架构
3. 校准(可选)
4. 模型量化
a. 设置qconfig(推荐先设置全局 qconfig 为get_default_qat_qconfig(),在此基础上根据需求修改,一般而言,只需要对 int16 和高精度输出的 op 单独设置 qconfig)
b. 转qat模型
5. 量化训练&精度验证
6. 转定点模型&精度验证
7. 模型编译
参考代码:
2.2 异构方案
异构方案的使用步骤大致如下:
a. 完成算子替换(参考ptq方案算子支持列表)
① 对于非 module 的运算,如果需要单独设置 qconfig 或指定其运行在 CPU 上,需要将其封装成 module,参考后文示例中的_SeluModule
b. 插入量化和反量化节点
① 如果第一个 op 是 cpu op,那么不需要插入 QuantStub
② 如果最后一个 op 是 cpu op,那么可以不用插入 DeQuantStub
2. 设置硬件架构
3. 校准(可选)
4. 模型量化
a. 设置qconfig:推荐先设置全局 qconfig 为get_default_qat_qconfig(),在此基础上根据需求修改,一般而言,只需要对 int16 和高精度输出的 op 单独设置 qconfig
b. 转qat模型:设置 hybrid=True,并通过 hybrid_dict 指定需要运行在cpu上的节点
5. 量化训练&精度验证
6. 导出onnx
7. 评测定点精度
8. 使用hb_mapper工具完成定点转换&模型编译
参考代码:
8. 使用hb_mapper工具完成定点转换&模型编译
最简config.yaml配置示例:
模型转换:
从转换日志可见,selu、layer1.conv以及conv0都运行到了cpu上:
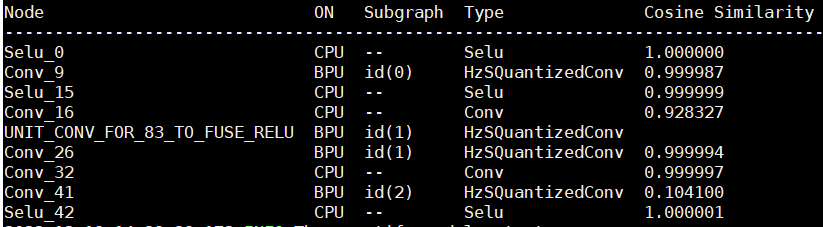
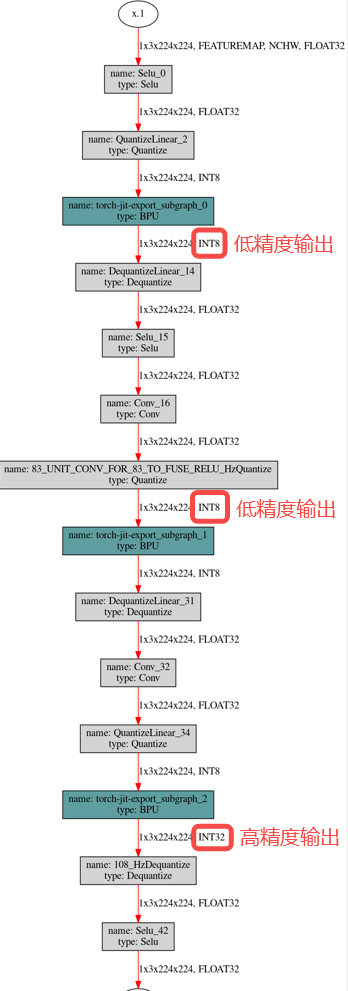
使用hb_perf工具生成模型结构图,可观察到第一段以及第二段bpu结尾的conv未设置高精度输出,仅对第三段bpu的尾部节点设置了高精度输出:
3 其他常见问题
打印qat_model发现多出了一些generated_add节点,这是为什么?

答:这是因为模型中直接使用了“+”号运算符,工具会通过新注册的generated_add来实现将其自动替换为FloatFunctional.add。建议大家最好在浮点模型准备阶段自行完成算子替换,因为工具自动转换时会依据执行顺序为add命名,若您后续修改了模型,可能会出现无法加载原ckpt的问题。



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)