
0 前言
由于部署时数据来源的硬件不同以及应用开发的高效性要求,往往会使得在板端部署阶段的数据准备操作与训练时有所差异。通过阅读本文您可以找到以下问答的答案:
一些常见的图像格式转换以及归一化处理是否支持硬件加速?(请参考本文1.1节)
若部署时数据来源于摄像头,我应该怎么配置?(ptq方案请参考本文1.2.1节,qat方案请参考2.2.1节)
若部署时数据来源于摄像头,可以如何验证板端和PC端模型精度一致性?(ptq方案请参考本文1.2.2节,qat方案请参考2.2.2节)
在什么情况下我需要在预处理时完成量化、数据对齐操作?(ptq方案请参考本文1.2.2&1.3节,qat方案请参考2.2.2&2.3节)
从PTQ方案迁移到QAT方案的话数据预处理方面需要做什么调整?(请参考本文第二章)
1 PTQ方案
PTQ方案:通过地平线提供的hb_mapper工具完成浮点模型向定点模型的转换。该方案只需要用户准备少量的校准数据并配置一份config.yaml文件即可通过一行命令完整模型量化。
1.1 与模型输入信息相关的配置项
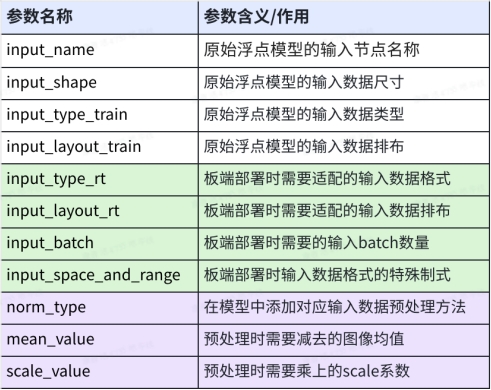
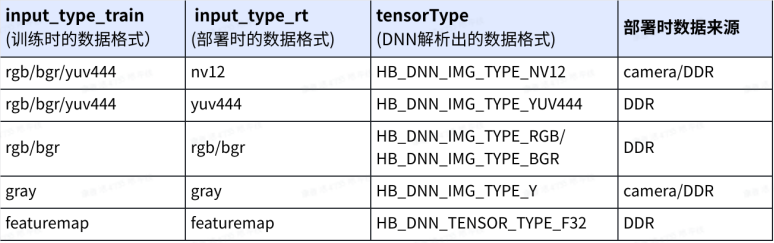
其中nv12支持两种数据分布范围,可通过input_space_and_range参数指定。默认为regular,数值范围为 [0,255];还可支持 bt601_video,数值范围为[16,235]。
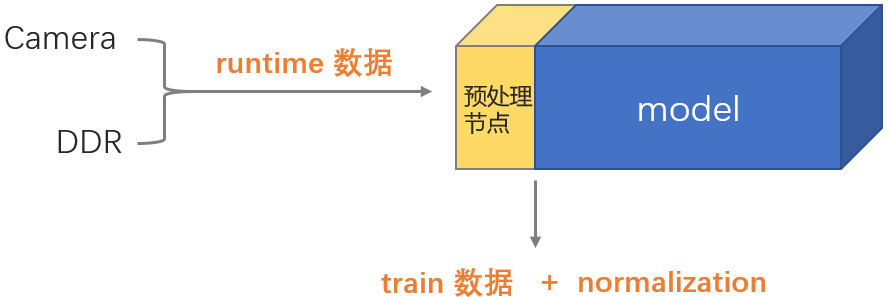
1.2 camera输入注意事项
本节我们以yolov5s模型为例,说明camera输入场景下模型转换配置以及模型精度验证的方式和注意事项。yolov5s模型浮点训练时的预处理代码为:
1.2.1 模型转换
依据前文1.1节介绍的配置项说明,yolov5s模型的config.yaml文件可按如下配置:
校准数据预处理代码:
1.2.2 PC端与板端推理一致性验证
在板端部署时nv12转yuv444_128的操作是在从DDR读取nv12数据时由编译器完成的,如下图所示。在PC端推理quantized.onnx则需自行在预处理时完成该转换。

1. yolov5s_672x672_nv12_quantized.onnx推理示例代码:
2. yolov5s_672x672_nv12.bin推理快速验证:
若仅做一致性验证,推荐使用hrt_model_exec infer工具,无需任何代码开发,按照前文参考代码,在Python端准备好nv12数据即可。使用下面这行命令即可得到txt格式的模型输出结果。
3. 调用BPU SDK API进行推理验证
从摄像头接入数据到送入模型推理的全流程示例及配套文档可通过如下路径获取:
X3派
示例:板端:/app/ai_inference/
X3
J3
请联系项目对接人获取
J5
示例:OE:/ddk/samples/ai_forward_view_sample
1.3 featuremap输入注意事项
此外,由于预测库DNN不支持featuremap类型数据的padding操作,因此用户还需在预处理时完成数据跨距对齐的padding操作。
2 QAT方案
QAT方案:通过地平线提供的基于pytorch框架定制化实现的量化工具plugin完成浮点模型向定点模型的转换。
该方案支持以下两种方案(异构与非异构):
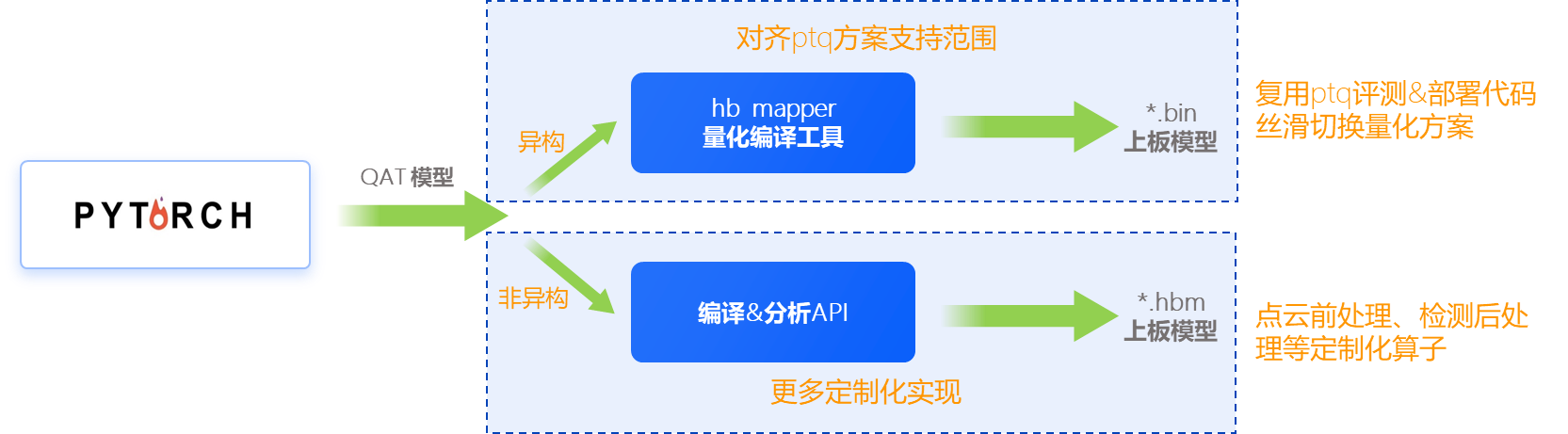
其中第一种异构方案的编译及部署方式与PTQ方案完全对齐,就不再赘述了,后文讨论的均是非异构方案。
第二种非异构方案是直接调用python API完成模型转换编译,最终生成的是.hbm后缀的模型,该模型由纯bpu指令组成,因此量化/反量化等cpu操作都需要用户自行在前后处理里完成。
2.1 与模型输入/输出信息相关的配置项
编译模型使用的API为compile_model,支持的配置选项如下:
该API只有input_source以及input_layout参数与模型输入信息相关(与PTQ方案中的编译参数组compiler_parameters相对应),因此缺少了预处理节点相关配置项。若想将图像格式转换(rgb、bgr转yuv)以及归一化操作放到模型中使用硬件加速的话,请参考下一节 2.2 camera输入注意事项
2.2 camera输入注意事项
同样的,我们依然以yolov5s模型为例,说明camera输入场景下如何将图像格式转换以及归一化操作配置进模型中实现硬件加速。(yolov5s浮点训练的预处理代码请参考前文1.2节)
2.2.1 模型转换
该算子为纯定点算子,不参与模型训练的过程。该算子使用方式如下:
通过QAT训练得到满意的精度之后,先使用convert()接口将qat模型转为quantized模型;
修改forward,在QuantStub后插入该算子;
设置QuantStub的scale=1(因为QuantStub已经被合入到了centered_yuv2rgb中,此处只有标识符的作用);
推理一次quantized模型。
参考代码:
可通过print model或visualize_model()观察是否已插入该算子。
若模型使用yuv444格式训练,建议数据归一化操作为减128并除以128,同时需要将QuantStub的scale设置为1/128。
编译模型时注意设置input_source为pyramid。与ptq有所不同的是,大家会发现编译出来的hbm模型在板端解析出来其输入数据类型不是HB_DNN_IMG_TYPE_NV12,而是HB_DNN_IMG_TYPE_NV12_SEPARATE,后者的y和uv分量是分别存储的,需要为其申请两个hbSysMem,这也是由于pyramid出来的数据是y和uv分量分开存储的两个地址,因此该数据类型更方便分开为y和uv赋值。
2.2.2 PC端与板端推理一致性验证
在PC端验证quantized模型精度时需要在预处理阶段完成rgb/bgr转nv12+nv12转yuv444的过程,具体原因请参考前文 1.2.2 节。
1. quantized模型(或是traced模型)推理示例代码:
若仅做一致性验证,推荐使用hrt_model_exec infer工具,无需任何代码开发,按照前文参考代码,在Python端准备好nv12数据即可。
2.3 featuremap输入注意事项
3 其他应用开发技巧
batch模型
crop/resize加速
示例:OE:/ddk/samples/ai_toolchain/horizon_runtime_sample/code/02_advanced_samples/multi_model_batch
优先级调度



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)