
概要
该文档主要介绍了地平线模型转换工具链中算子量化的内在逻辑,便于用户理解一些特殊场景的量化处理。
背景与问题
在用户使用地平线模型转换工具链时,偶尔会遇到如下问题:
模型成功转换成bin后,发现仍然有个别op运行在CPU上,但回头仔细对照地平线算子约束列表,明明该op是符合算子约束的,也就是理论上该算子应该成功运行在BPU上。为什么仍然是CPU计算呢?
此问题对较多用户都造成了一定的困扰,该文章即用来介绍模型转换工具链中内部的量化原理与背后的逻辑,并介绍几种解决解决方法。
一个op什么时候会运行在BPU上
对于模型转换工具链来说,一个op是否量化并运行在BPU上,取决于以下两点:
该op是否符合BPU支持规格;
该op在上下文能否找到合理的量化阈值;
考虑到算子运行在BPU的过程中有量化这一步骤,而第二点则是对量化的明确,即一个op能否从上下文子图中找到量化其自身的合理量化阈值。这点取决于转换工具链内部的校准和量化模块的设计,对于用户是透明的。而正是因为转换工具链内部设计的量化逻辑导致了上述“应该运行在BPU上但还是在CPU上”的问题出现。该文章会对工具链内部的量化逻辑的技术细节进行抽象,说明量化阈值的合理引入场景。
op量化逻辑分类
主动量化类算子
量化逻辑特点
主动量化类算子指的是能量化尽可能量化的算子,此类算子有以下特点:
往往算子本身是计算密集性算子,或者是BPU擅长的计算类型算子。
研发通过大量实验,验证了该类型算子在大多数场景下量化的精度风险很小。
典型代表
计算密集型算子:conv/matmul/gemm/convtranspose等。
激活和数学类算子:mish/hardswish/sin/cos等。
elementwise算子:mul/add等。
其它:argmax/reduce算子等
对于主动量化类算子,转换工具链会通过调整阈值校准位置等方法,尽可能的保证校准统计的阈值可以满足该算子的量化逻辑要求,进而保证其“尽可能的被量化并且运行在BPU上”。
被动量化类算子
被动量化类算子指的是该算子只有在其上下文的其它算子也比较“适合被量化在BPU”的情况下才会被动“跟随”量化的算子。更加简单但不严谨的说,就是当该算子前后都是主动量化算子的时候,该算子才会被动的也跟着量化。
量化逻辑特点
设计被动量化逻辑的主要原因是此类算子运行在BPU上精度和性能两个角度的考虑:
性能角度:
非计算密集型算子,相对而言,BPU没有那么“擅长”该类计算。
该算子所处的子结构整体不被BPU支持,避免出现单独量化该算子在BPU上运行了但整体运行效率却更低(引入了浮点quantize/dequantize的计算)。
精度角度:
相对而言,该类算子存在一定的量化精度风险。
由于BPU的特性,该类算子作为BPU最后输出节点时,为保证更高的精度该算子被放置在CPU上浮点计算(进而确保BPU的输出为定点32bit的高精度输出)。
典型代表
数据搬运和数据操作类算子:concat/slice/SpaceToDepth/gather/reshape/transpose等
Pooling类算子:averagepool/maxpool/globalaveragepool/globalmaxpool
resize算子:resize
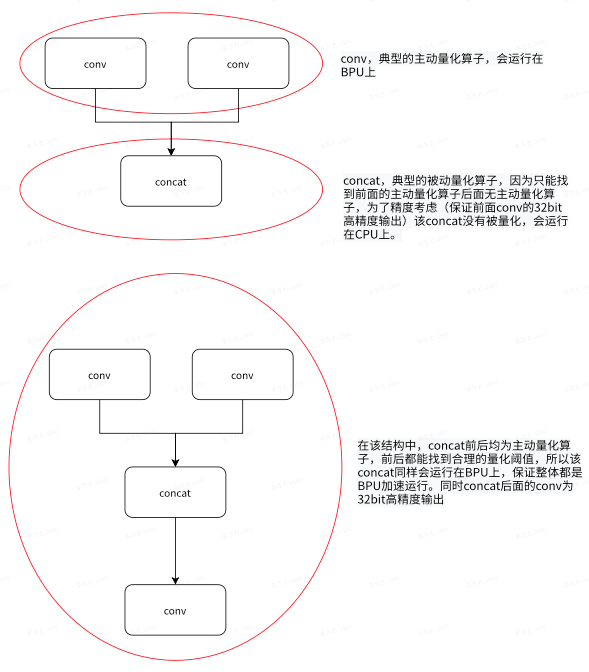
由于被动量化逻辑不是很好理解,让我们举个栗子:

而第二个子结构中的concat,因为前后都有主动量化算子,则该concat也会被动的跟随被量化,保证所有conv+concat+conv都在一段BPU上运行。
手动量化类算子
该类算子的典型代表是softmax。
同时,考虑到不同用户的不同模型和使用场景的不同,模型转换工具链在yaml中提供runonbpu功能,配置,只需要指定某个手动量化的算子名字为runonbpu,即可手动将该算子量化在BPU上运行。
如何配置被动量化节点运行在BPU上?
模型转换工具链如此设计量化逻辑的背后原因是各种场景的最大公约数+精度与性能的平衡。但针对某个具体用户的具体场景,用户有更好的平衡精度和性能的考虑,为此,工具链提供几种方法进修改量化阈值逻辑,进而可以将默认运行在CPU上的被动量化or手动量化算子配置在BPU上运行。
- runonbpu功能:部分被动量化算子和手动量化算子,在转换后发现该算子运行在了CPU上并且该算子符合BPU算子约束时,可以通过声明runonbpu的方法将该算子配置在BPU上运行(被动量化算子只有部分支持runonbpu功能,后续工具链版本会逐步支持)。
- 插入unitconv算子:在原始训练框架构建并导出模型时,在被动量化算子前面/后面插入一个unitconv算子。因为conv算子是典型的主动量化算子并且不改变输入输出(不需要重新训练),在被动量化算子的前面or后面插入unitconv算子,可以保证该被动量化算子所在的前后上下文都有主动量化的conv算子,进而该被动量化算子会被动的跟随被量化(详细例子可以参考上文的conv+concat结构)。
对unitconv算子的详细说明可见工具链社区文章,下面是一个典型unitconv在pytorch框架下的写法:
总结
本文介绍了地平线模型转换工具链的内部量化逻辑,解释了什么是主动量化、被动量化和手动量化,以及量化逻辑在工具链使用过程中的具象:为什么模型转换后,偶尔会出现个别算子明明符合算子支持约束但却运行在了CPU上的原因。
而随着地平线模型转换工具链的不断完善,算法的持续迭代优化以及BPU架构的更新,不同op的量化策略会动态的进行调整。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)