
使用场景及原理
一个op能否运行在BPU上取决于两个条件:
1.该op是否可被BPU支持
2.能否找到该op的量化阈值
对于部分非计算密集op,其量化阈值依赖于上下游op的featuremap Tensor,因此若您在模型首尾处使用了非计算密集op(concat,reshape等),且为了追求极致性能想让该op运行在bpu上,则可通过在该算子前/后插入unitconv,通过unitconv的featuremap Tensor引入新的量化阈值统计,可以保证unticonv的上下游op找到量化阈值,进而可以将其量化在BPU上。
由于硬件特性,地平线工具链支持模型尾部的conv计算以int32高精度输出,若为其他算子(concat,reshape等),则只能以int8输出,同时会导致其前面的conv无法高精度输出,因此使用unit_conv量化非计算密集op有可能会对模型精度产生影响,若确认会导致精度降低,则建议您将concat等算子从模型中摘除,合入到前后处理中完成。
使用方式
在模型中插入unit_conv可参考如下代码:
class unit_conv(nn.Module):
def __init__(self):
super(unit_conv,self).__init__()
··· ···
self.cat = torch.cat
# in_channels = out_channels = 前一个节点输出tensor的channle
self.unitconv = torch.nn.Conv2d(8,8,1,1,groups=8,bias=False)
# 初始化 unit_conv 权重,确保unit_conv输入输出相等。该节点仅在部署时插入即可
torch.nn.init.dirac_(self.unitconv.weight.data,groups=8)
def forward(self, x):
··· ···
out = self.cat((a,b),axis=1)
out = self.unitconv(out)
return out
def __init__(self):
super(unit_conv,self).__init__()
··· ···
self.cat = torch.cat
# in_channels = out_channels = 前一个节点输出tensor的channle
self.unitconv = torch.nn.Conv2d(8,8,1,1,groups=8,bias=False)
# 初始化 unit_conv 权重,确保unit_conv输入输出相等。该节点仅在部署时插入即可
torch.nn.init.dirac_(self.unitconv.weight.data,groups=8)
def forward(self, x):
··· ···
out = self.cat((a,b),axis=1)
out = self.unitconv(out)
return out
原始模型:
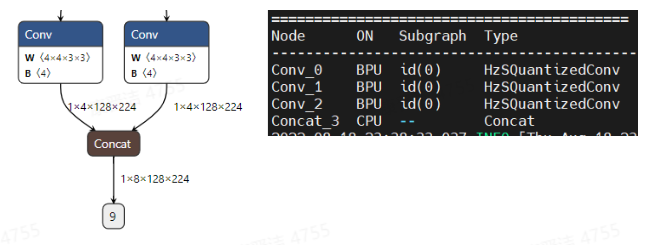
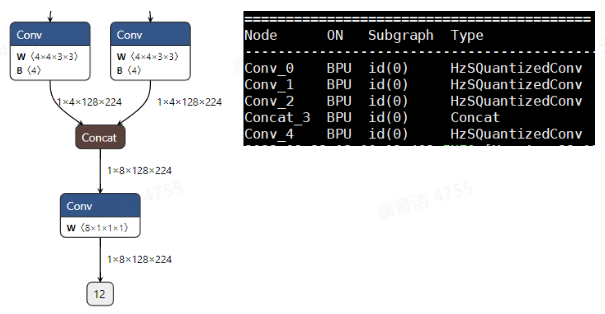
插入unit_conv后:


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)