
1 what is QAT?
QAT全称为quantization aware training,是一种模型量化手段,通过在训练过的浮点模型中插入伪量化节点来实现后续的精度fintune,因此QAT相较于PTQ来说往往精度会更高。由于定点数值无法用于反向梯度计算,实际操作过程是在某些op前插入伪量化节点(fake quantization nodes),用于在训练时获取流经该op的数据的截断值或分布,便于在部署量化模型时对节点进行量化。
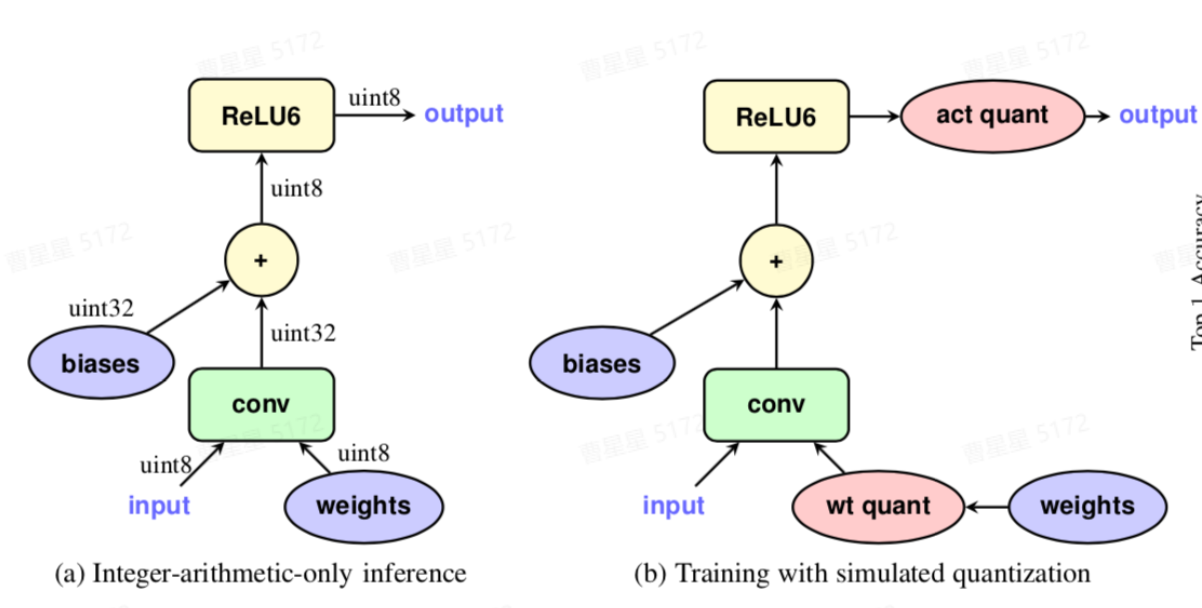
如上图所示,a为量化的定点模型,数据和模型权重均已变为定点数,通常情况下我们希望后量化(PTQ)能直接得到a所示的定点模型,并且精度不会损失太多。如果精度损失太多,则需要借助图b所示的量化感知训练(QAT)减少量化误差。QAT的基本原理是在浮点模型中插入伪量化节点,使得模型在训练中可以感知到量化误差,减少量化损失的精度。如上图b所示,在模型中针对conv-weight和activation插入FakeQuanti节点。由FakeQuanti模拟量化过程,weight会学习到量化的影响,最终损失精度会更小。
在地平线工具链中,QAT的上下游如下图所示:
_20220624101321.png)
2 Before start
2.1 环境部署
地平线提供两种环境部署方式:docker方式和虚拟环境安装方式,以下给出两种方式的部署方法,其中version根据实际发布包的版本号进行替换。
Docker 方式
实现QAT量化的环境已封在docker中,docker获取方式为:

虚拟环境方式

2.2 模型准备
QAT训练是一种finetune方法,最好是在浮点结果已经拟合的情况下,再用QAT方法提升量化精度。 即用户的训练分为了两个步骤,先训练浮点模型,将模型精度提升到满意的指标;再通过QAT训练,提升量化精度。
地平线主推的社区QAT功能是基于fx graph模式开发的,fx graph模式的社区qat不需要编写fuse_model和set_qconfig,但由于pytorch fx自身的局限性,需要对模型的forward方法进行一些调整以适配fx。注意事项有以下几点:
- a. 避免在forward中编写不运行在training状态的逻辑。避免生成的graph module会丢失training无关的逻辑(如模型后处理部分)。
- b. 由于fx不支持动态控制流,因此避免在forward中使用与动态输入有关的语句(if、for、assert等)。对于并非真正的动态(如:height, width),可以以成员变量的形式预先存储在模型中。如无法避免与动态输入相关的控制流,可以将这部分逻辑写为一个函数,使用wrap方法装饰起来,用法见pytorch社区wrap章节。

- c. python的部分内置方法不支持trace,比如:len。可以使用wrap()修饰不需要被trace的方法,详细用法见pytorch社区。

- d. 如果有不需要量化的逻辑,可以使用wrap装饰不需要量化的逻辑,这部分逻辑会作为一个整体被trace,中间不会插入伪量化结点。用法见pytorch社区wrap章节

- e. 将需要运行在AI芯片上的、需要量化的部分封装为独立的module成员变量,可仅对该部分做量化感知训练。以下写法是地平线推荐的写法:

- f. 共享conv不共享bn会导致模型在fuse过程混乱导致模型预测完全错误。对于此类问题pytorch在fuse这里的代码中留了todo,后续版本应该会解决这个问题。在当前版本,为了避免这个问题,推荐重点检查参数共享中有无处理完一个分支后影响另一个分支的情况。这类参数共享问题的解决方法建议将QAT模型的conv拆开。
3 QAT模型量化
3.1 模型量化
地平线主推的社区QAT功能是基于fx graph模式开发的。用户只需要对模型结构做出少量调整。通过调用torch的量化接口prepare_qat_fx,使用地平线提供的量化策略配置,即可完成QAT模型的构造。本章节主要对prepare_qat_fx接口以及地平线提供的量化策略配置做介绍。
3.1.1 prepare_qat_fx
该接口为torch提供的模型量化接口,作用为将浮点模型转为一个可以进行量化感知训练的Prepare模型。定义如下:


当用户调用prepare_qat_fx时,会进行以下步骤:
- a. 构建静态图:使用fx工具trace整个网络结构(可使用prepare_custum_config_dict指定某一块不被trace),构建出一个静态的网络结构。
- b. 融合特定网络结构:加载默认的和用户定义的fuse pattern配置,对网络结构进行遍历、融合,例如pytorch默认会把conv+bn+relu融合为instrice.ConvBnRelu。
- c. 转换网络结构:加载默认的和用户定义的convert pattern配置,将网络中特定的网络结构转换为指定的网络结构。
- d. 量化网络结构:加载默认的和用户定义的quantize pattern,在需量化的节点位置插入伪量化结点。
3.1.2 qconfig_dict
qconfig_dict作用为声明量化节点的量化方法,例如非对称、per-tensor等方法,地平线支持的量化方式为:Weight: Int8 per channel symetric;Activation: Int8 per tensor symetric。目前地平线支持的量化qconfig为以下3种配置:
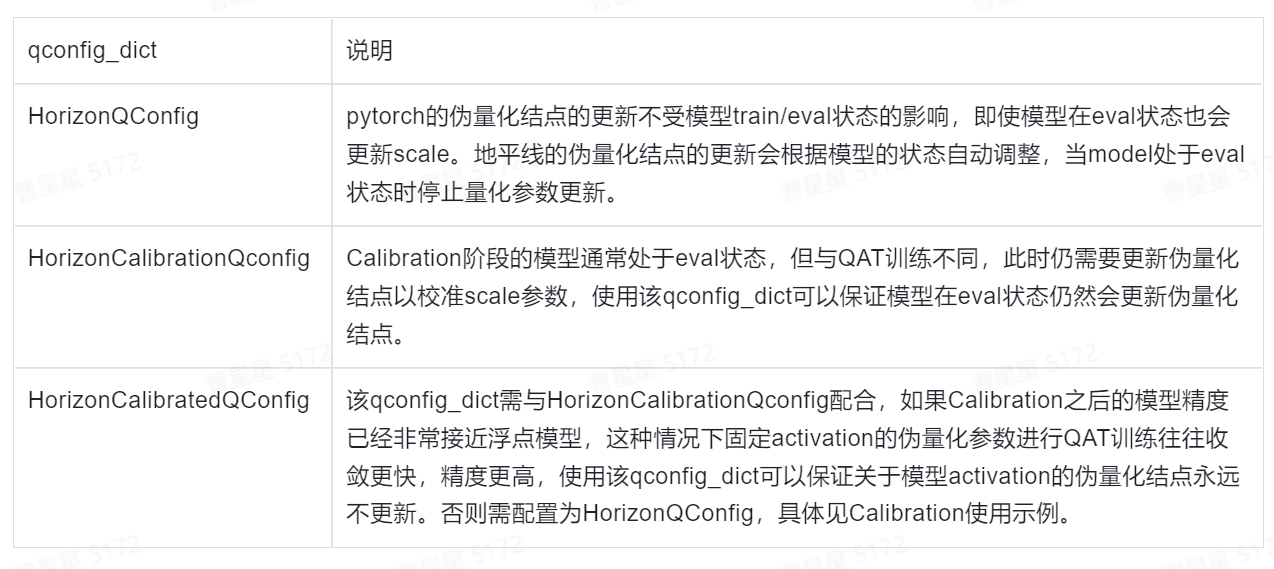
如果用户有自定义qconfig的需求,可以参照pytorch官方文档和地平线提供的三个qconfig_dict进行自定义,需要注意的是量化方式需要和地平线保持一致!
Calibration的使用不是必须的,但是几乎对于所有模型都有提升,因此建议您可以尝试先使用Calibration对量化参数做初始化,以下提供两个示例分别为使用Calibration和未使用Calibration下如何使用:
不使用Calibration

使用Calibration
Calibration的实现方式很多,这里给用户推荐两种最简单的实现:

3.1.3 prepare_custom_config_dict
prepare_custom_config_dict作用为自定义设置prepare的过程,例如指定不量化某一层、指定不使用FX追踪某一层、指定某些结构(avgpooling+relu)可以打包量化等。
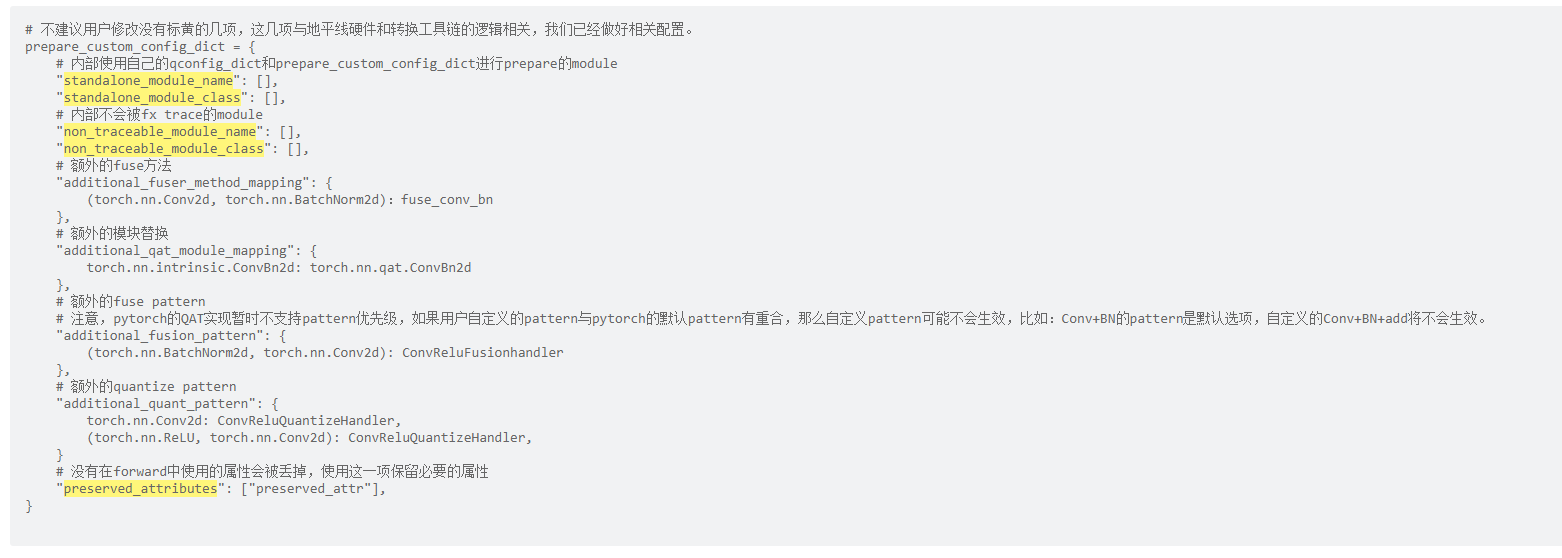
若您需要自定义prepare_custom_config_dict时,请在HorizonPrepareCustomConfigDict的基础上进行修改,以免add和pooling等算子的量化方式不正确。见示例:

3.2 其他量化配置
除了相关配置外,地平线也针对pytorch社区QAT制作了一些方便使用的接口。本章将对这些接口做介绍和使用说明。
3.2.1 输入/输出量化配置
使用情景:
disable_input_fake_quant :
如果确认模型的输入是量化过的,可以使用disable_input_fake_quant。对于_modules中存在但named_modules中没有的情况不能保证disable_input_fake_quant如预期工作,可以通过打印模型确认节点是否被禁用,如果没有被禁用则需要手动使用disable_fake_quant()摘除伪量化节点,详细用法参考3.3章节。
disable_output_fake_quant:
算子以conv、matmul结尾可使用disable_output_fake_quant实现高精度输出,如果输出是sigmoid,tanh等无法支持高精度输出的算子,且仍然希望这部分运行在BPU上,则不需要调用disable_output_fake_quant;对于_modules中存在但named_modules中没有的情况不能保证disable_output_fake_quant如预期工作,可以通过打印模型确认节点是否被禁用,如果没有被禁用则需要手动使用disable_fake_quant()摘除伪量化节点,详细用法参考3.3章节。
通过打印模型可以看到伪量化结点有fake_quant_enable变量,该变量控制该结点是否做量化操作,为1则量化,为0则不量化。

如不需要对输入输出量化可通过调用disable_input_fake_quant或disable_output_fake_quant将对应伪量化结点的fake_quant_enable置0。使用方式见示例:

在以上示例中仅对neck和head做了量化,neck的输入来自于backbone,未量化过,所以neck不需要调用disable_input_fake_quant,而neck不是模型的最终输出,所以也不需要调用disable_output_fake_quant。head的输入来自neck,已经经过量化,所以head的输入不需要量化,同时head的输出是模型的最终输出,所以两个方法都需要调用。
3.2.2 量化状态train/eval配置
打印模型可以看到伪量化结点有observer_enable变量,该变量控制伪量化的scale等参数是否更新。开启时值为1,伪量化的scale等参数在每次forward中都会根据observer统计到的min,max进行更新,关闭时为0,停止更新。

通过调用set_qat_eval && set_qat_train可以改变observer_enable的状态。当使用set_qat_eval 时observer_enable变为0,调用set_qat_train后,observer_enable将变为1。需要注意的是,当使用HorizonQConfig 时无需调用set_qat_eval && set_qat_train接口,在内部逻辑中量化参数的更新会根据模型状态做调整,模型处于eval状态时,量化参数不再更新,处于training时量化参数更新。具体使用方法示例:

3.3 模型结构检查
为保证量化的正确性,建议您在prepare_qat_fx后,将已插入伪量化的节点的QAT模型进行打印,通过观察以下四点来对模型伪量化结构进行检查:
检查需量化的模型节点
对需插入伪量化节点的位置检查是否正确插入,标识为“weight_fake_quant”和“activation_post_process”。下图为conv+BN+ReLU在prepare_qat时融合为ConvBnReLU2d,从图中可以看出weight有了伪量化,weight的伪量化一般都是放在模块内。
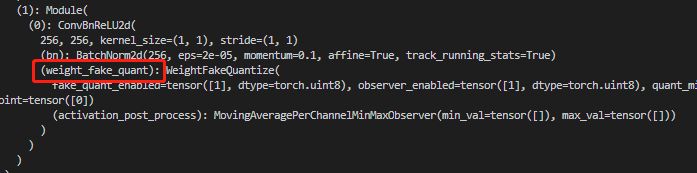
下图表明cls_seg_0模块的输出已经有了伪量化结点。输出的伪量化一般都放在模块外,且名称以activation_post_process结尾。

检查无需量化的模型节点

若出现无需量化的位置插入了伪量化节点可以通过查看节点所在位置,使用disable_fake_quant()手动去除量化节点。使用方法见示例:

模型输出节点的检查
查看输出的伪量化结点是否已经禁用。如果没有禁用,则需要调用disable_output_fake_quant将fake_quant_enable置0,具体用法和注意事项见章节3.2.1。

注册算子节点的检查
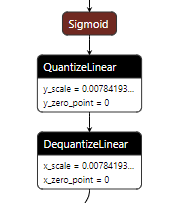
在import HorizonPrepareCustomConfigDict时,程序会自动向pytorch注册几个固定scale的算子(sigmoid,tanh...)的量化方法,这一部分无需用户显式调用,程序自动完成。用户可以检查QAT模型中的sigmoid等算子的输出伪量化对应的scale是否为同样的固定值。
3.4 量化训练策略
- a. 开启calibration。从下图可以看到,如果不做calibration,初始的scale值为1,做完calibration之后,该值应小于1,开启方法见章节3.1.2。

注:calibration阶段,数据不要使用augmentation,前处理和推理阶段保持一致。
- b. 若使用多卡且batchsize较小,建议开启同步BN
- c. 绝大部分情况下,batch size 尽可能大一些,最好打满显存。有的时候太大也不好(一般发生在大于128时),具体取值需调参尝试。原理见:https://www.zhihu.com/question/61607442
- d. 减弱data augmentation。由于量化误差的存在,QAT模型的拟合能力会弱于float模型。减弱并非全部关闭,可关闭较复杂的data augmentation,保留部分基础的data augmentation。
- e. 通过前处理改变输入分布,确保输入数据分布合理,均值为0,最好是均匀分布,其次为高斯分布,避免长尾分布,强烈推荐用户将输入映射到[-1, 1],尽量避免只有正/负数值域的表示。
- f. weight decay一般设置为4e-5,可根据实际实验情况调整。weight decay过小导致weight方差过大,weight decay过大导致输出较大的任务(比如检测的bbox回归)输出层weight方差过大。
- g. learning rate一般从0.001左右开始设置,可根据实际实验情况调整。一般可以搭配StepLrUpdater做1-2次scale=0.1的decay。learning rate的最小值最好不要小于1e-6
- h. 不推荐使用warmup。QAT属于finetune任务,warmup初期学习率过小,对QAT几乎没有加成,甚至会降低QAT精度。
- i. epoch长度不固定,一般选为float epoch大小的十分之一到二分之一不等。
- j. 最优.精度的QAT模型一般在第一个epoch结果的基础上提升不超过3个点,如果第一个epoch的指标较低,那么基本可以断定最后模型的结果不会很好。
- k. 如果单次训练的batch size较小,固定住BN的均值和方差可能取得意想不到的效果。示例见下:

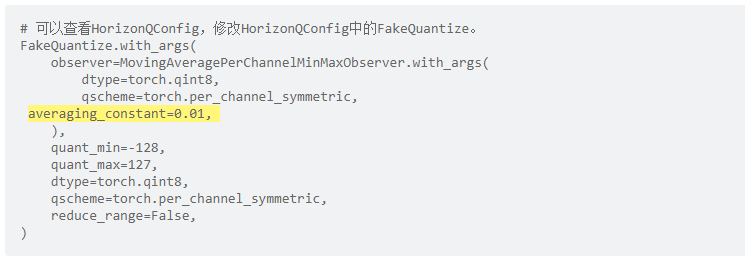
- l. 调整averaging_constant,取值范围为(0, 1]。伪量化结点中的observer通常采用滑动平均的方式更新,averaging_constant控制当前值的影响程度。averaging_constant越大,当前值影响越大,反之影响越小。在scale初始化不靠谱时,调大averaging_constant效果较好;在训练稳定性较差或者数据集较小的任务,调小averaging_constant效果较好。averaging_constant定义见示例:
- m. 多选用不同epoch的浮点模型做QAT,有时并非最好的浮点模型就能训出最好的QAT模型。最好的浮点模型往往处于过拟合的边缘,此时进行QAT不一定最好。
- n. 没有calibration的情况下Weight与fake quantize交替更新效果比较明显。weight与fake quantize scale的收敛方向可能不一致,同时调整两者可能产生冲突。
3.5 量化精度验证
3.5.1精度验证
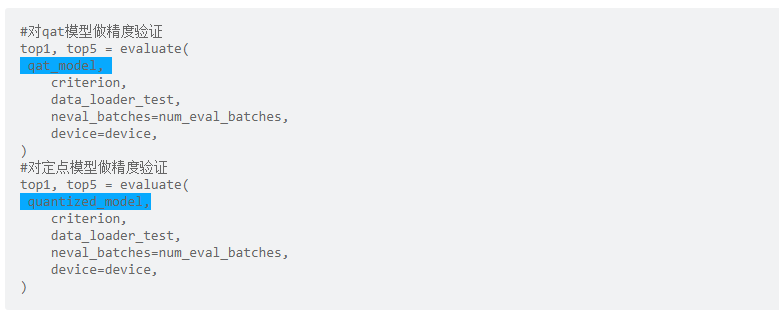
QAT的精度验证过程与浮点精度验证原理相同,可直接复用浮点模型评测代码,见代码示例:
3.5.2 问题定位
得到QAT模型精度以后,如果发现掉点问题,请按照如下步骤定位问题:
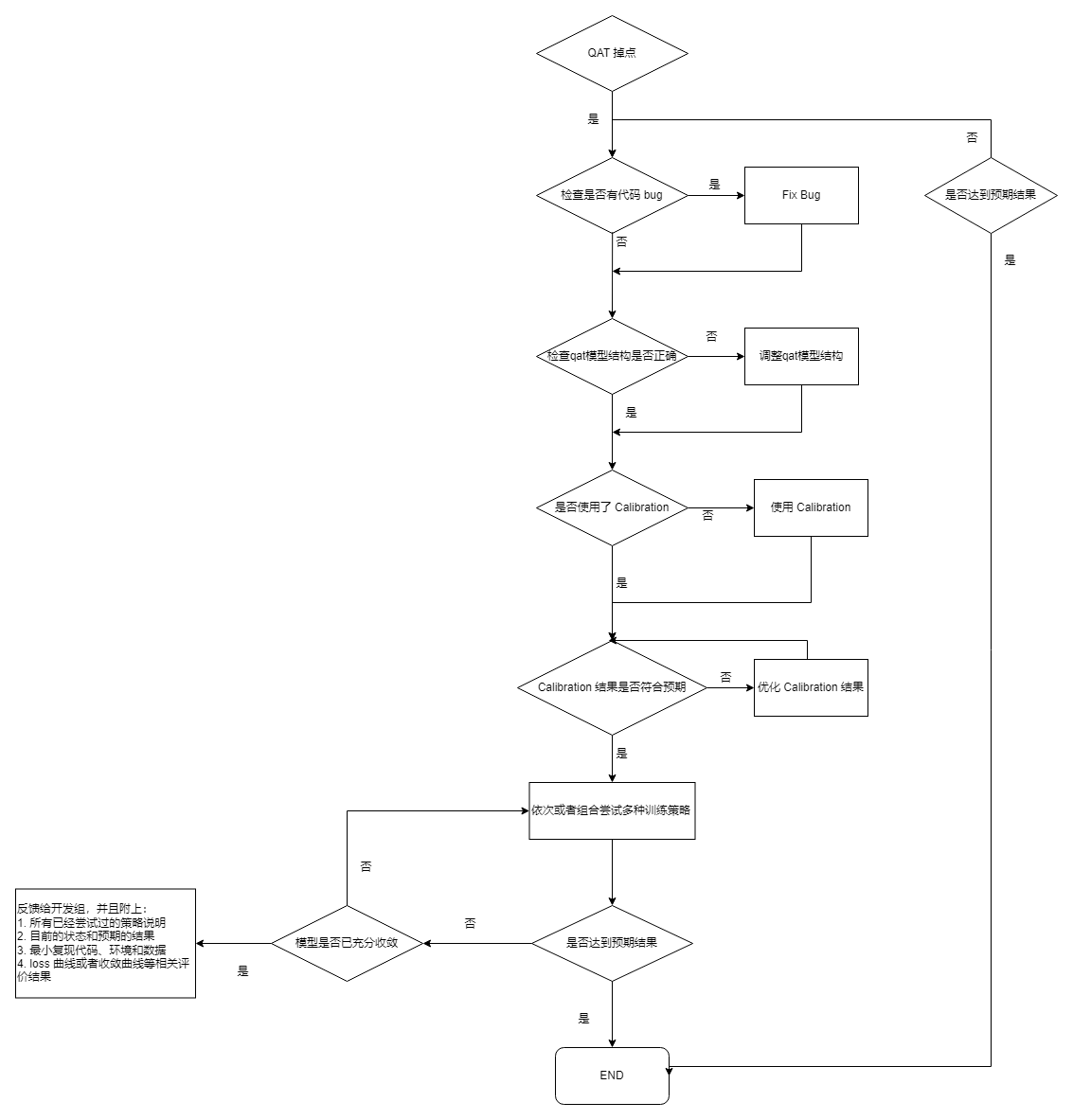
4 模型编译
模型上板需编译为.bin,地平线提供以下两种方式实现:
- export to onnx + hb_mapper makertbin 工具(推荐首选方式)
使用export_to_onnx接口将qat_model导出qat_model.onnx,再使用工具链hb_mapper makertbin工具通过对yaml文件中的calibration_type设置为'load' ,即可实现将qat_model.onnx编译为.bin文件. 该方法的工具开发比较完善, 因此推荐用户优先使用该方法. export_to_onnx使用方法见示例:

- convert + compile
使用convert将qat model转化为quantilized model,再通过compile接口将quantilized model编译为可上板的.bin,convert过程中会产出中间结果onnx_temp.onnx,与后文介绍的export_to_onnx接口的产物相同。该方法由于尚在开发中, 因此部分功能实现并不完善,使用见示例:

附:完整示例
import torch
from torch.quantization.quantize_fx import prepare_qat_fx
from hemat.torch.quantization import (
HorizonQConfig,
HorizonPrepareCustomConfigDict,
disable_output_fake_quant,
)
from hemat.torch.quantization import set_qat_eval, set_qat_train
from horizon_nn.torch import export_onnx, convert
def load_model():
pass
def accuracy():
pass
def evaluate():
pass
def train():
pass
def prepare_data_loaders():
pass
data_loader = prepare_data_loaders()
float_model = load_model()# 用户训练好的模型
# 按照HorizonQConfig配置量化策略
qat_model = prepare_qat_fx(float_model, HorizonQConfig, HorizonPrepareCustomConfigDict)
# 设置最后一层卷积高精度输出 (若无此要求, 该步骤可省略)
qat_model = disable_output_fake_quant(qat_model)
# 检查一下QAT模型结构是否正确
# print(qat_model)
for nepoch in range(epoch_size):
# 设置模型为训练模式, 开启量化参数更新
qat_model = set_qat_train(qat_model)
train(qat_model)
# 设置模型为评测模式, 停止量化参数更新
qat_model = set_qat_eval(qat_model)
top1, top5 = eval(qat_model)
# 将训练好的模型进行保存
save_dict = {'state_dict':qat_model.state_dict()}
torch.save(save_dict,"qat_best.pth")
# 将qat模型导出为 onnx 格式
dummy_data = torch.randn(1, 3, 224, 224,device=device)
export_onnx(qat_model, dummy_data, export_name="qat_model.onnx",opset_version=11)
# 得到 qat_model.onnx 之后, 就可以使用 hb_mapper makertbin工具进行后续的定点化及编译流程了.
# 如果使用该方法的话, 流程至此就可以结束了.
# 上述储存的pytorch模型在储存后读取方式的介绍.
float_model = load_model()
qat_model = prepare_qat_fx(float_model.train(), HorizonQConfig, HorizonPrepareCustomConfigDict)
state_dict = torch.load('qat_best.pth')['state_dict']
qat_model.load_state_dict(state_dict)
# 若不打算导出onnx模型, 由hb_mapper makertbin工具进行后续转换, 则需要使用
# convert + compile 接口的组合.
# 如果输入数据为yuv444 这种定点输入的数据, 则需要配置preprocess_setting
# expected_input_type 为上板输入的数据类型, yuv444_128为yuv444数据减去128结果, 数据类型为int8
preprocess_setting = {
"img": {
"means": np.array([128.0]),
"scales": np.array([1 / 128.0]),
"original_input_type": "yuv444",
"expected_input_type": "yuv444_128",
}
}
quantized_model = convert(
qat_model, # qat model
dummy_data, # dummy data, which is the input data to feed the qat model
march='bernoulli2' # bernoulli2 for xj3, bayes for j5
preprocess_setting=preprocess_setting, #定点输入的前处理
)
# 将定点onnx模型转为异构bin模型
compile(quantized_model,
"test.bin",
march="bayes",
rt_input_type="yuv444",
rt_input_layout="NCHW",
opt=opt,
)
该文章的pdf版本见附件

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)