
0 精度验证推荐流程
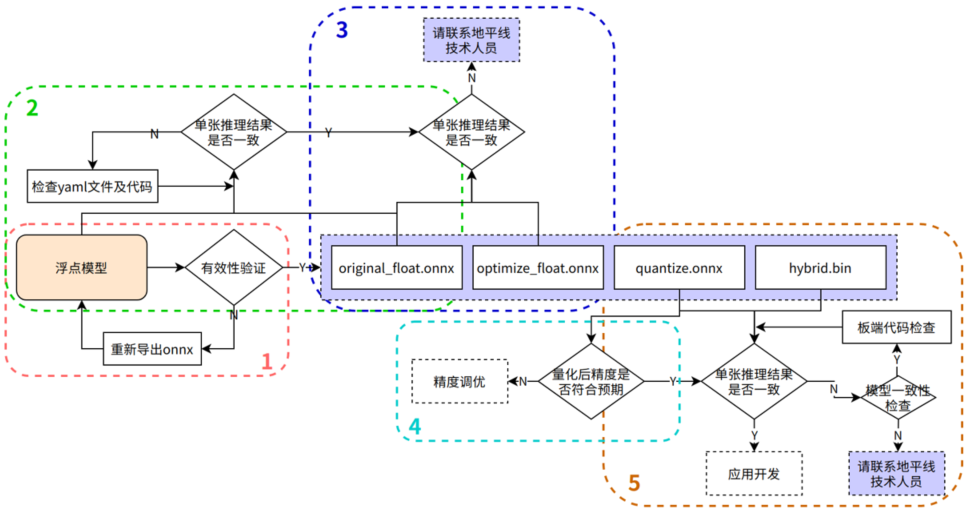
[精度调优推荐流程]
流程 | 验证目的 | 验证途径 | 参考代码/其他说明 |
|---|---|---|---|
1 | 确保导出的浮点onnx的有效性 | 测试浮点onnx模型的单张结果,应与训练后的模型推理结果完全一致 | 请参考后文:1.1 验证onnx模型推理结果正确性 |
2 | 确保yaml配置文件以及前后处理代码的正确性 | 测试original_float.onnx模型的单张结果,应与浮点onnx推理结果完全一致(nv12格式除外,由于nv12数据本身有损,可能会引入少许差异) | 请参考后文:1.2 yaml配置文件与前处理代码详解 |
3 | 确保图优化阶段未引入精度误差 | 测试optimize_float.onnx模型的单张结果,应与original_float.onnx推理结果完全一致 | 推理代码同上(若结果不一致,请先尝试更新OE开发环境至最新版本,若仍然有问题,请至地平线开发者社区工具链板块提问,并提供原始浮点onnx、配置文件、测试数据) |
4 | 验证量化精度是否满足预期 | 测试quantized.onnx的精度指标 | 建议可直接复用浮点模型评测代码:将模型加载/推理部分的代码改为加载/推理onnx模型dataloader的batchsize改为与onnx shape相对应预处理代码做对应修改(参照前文建议)若精度不满足预期,则可直接进入精度调优环节(可参考后文1.4 精度调优建议) |
5 | 确保模型编译过程无误且板端推理代码正确 | 使用hb_model_verifier工具验证quantized.onnx和.bin的一致性,模型输出应至少满足小数点后2-3位对齐 | hb_model_verifier工具目前只支持比对单输入模型,J5从OE1.1.40以及XJ3从OE2.5.2开始提供了hb_verifier工具,可支持多输入模型一致性校验,具体使用方式请参考后文1.3节相关介绍;此外,可在板端使用hrt_model_exec infer工具推理得到.bin模型原始输出与quantized.onnx做对比,同样可排除工程代码有误带来的影响。(若quantized.onnx与.bin模型一致性校验失败,请先尝试更新OE开发环境至最新版本,若仍然有问题,请至地平线开发者社区工具链板块提问) |
1 参考代码及注意事项详解
1.1 验证onnx模型推理结果正确性
1. 验证原始浮点onnx模型的正确性
特指从DL框架导出的onnx模型
2. 验证转换工具产出物的正确性
特指original_float.onnx、optimize_float.onnx、quantized.onnx
1.2 yaml配置文件与前处理代码详解
模型转换完成浮点模型到地平线混合异构模型的转换。 为了使得这个异构模型能快速高效地在嵌入式端运行, 模型转换重点在解决 输入数据处理 和 模型优化编译 两个问题。本节重点解析在输入数据处理方面的内部逻辑,便于大家理解预处理节点与模型前处理的配合关系。
1.2.1 预处理节点解析
由于HzPreprocess的存在,会使得转换后的模型其预处理操作可能会和原始模型有所不同,因此我们先来详细了解一下预处理节点的插入逻辑。
在mapper工具完成对caffe/onnx模型的转换时,首先会将caffe模型解析为onnx格式,并根据yaml配置文件中的配置参数(input_type_rt、input_type_train以及norm_type)决定是否为模型加入HzPreprocess节点,预处理节点会出现在转换过程产生的所有产物中。
理想状态下,这个HzPreprocess节点应该完成input_type_rt 到 input_type_train 的完整转换, 实际情况是整个type转换过程会配合地平线AI芯片硬件完成,ONNX模型里面并没有包含硬件转换的部分。 因此ONNX的真实输入类型会使用一种中间类型,这种中间类型就是硬件对 input_type_rt 的处理结果类型, 数据layout(NCHW/NHWC)会保持和原始浮点模型的输入layout一致。 每种 input_type_rt 都有特定的对应中间类型,如下表:
input_type_rt | nv12 | yuv444 | rgb | bgr | gray | featuremap |
|---|---|---|---|---|---|---|
中间格式 | yuv444_128 | yuv444_128 | RGB_128 | BGR_128 | GRAY_128 | featuremap |
表格中第一行是 input_type_rt 指定的数据类型,第二行是特定 input_type_rt 对应的中间类型, 这个中间类型就是模型转换中间产物三个onnx模型的输入类型。每个类型解释如下:
yuv444_128/RGB_128/BGR_128/GRAY_128为对应input_type_rt减去128的结果。
featuremap 是一个四维张量数据(J5支持非四维),每个数值采用float32表示。
为避免误用,并不是所有的input_type_rt和 input_type_train的组合都可以支持。依据实际生成经验,目前开放的组合如下:
nv12 | yuv444 | rgb | bgr | gray | featuremap | |
|---|---|---|---|---|---|---|
yuv444 | Y | Y | N | N | N | N |
rgb | Y | Y | Y | Y | N | N |
bgr | Y | Y | Y | Y | N | N |
gray | N | N | N | N | Y | N |
featuremap | N | N | N | N | N | Y |
此外,如果yaml文件中的norm_type参数配置为data_mean、data_scale、data_mean_and_scale,则预处理节点中还将包含norm操作。
请注意:yaml文件中的mean和scale参数与训练时的mean、std需要进行换算。
HzPreprocess节点中的计算公式为:norm_data = (data -mean)*scale,以yolov3为例,其训练时的预处理代码为:

[预处理示例代码]
1.2.2 预处理节点与前处理代码
由于HzPreprocess节点的存在,使得转换生成的模型其前处理会与原始模型有所差异。总的来说,有两点需要注意:
推理转换的中间模型(original_float_model.onnx / optimized_float_model.onnx / quantized_model.onnx),需要在预处理时将输入数据处理至input_type_rt的中间类型(-128的操作请通过配置onnx模型推理API的input_offset参数实现,该参数的应用可参考发布包中任意转换示例或前文1.1 验证浮点onnx模型正确性);
注意不要与HzPreprocess做重复的norm操作。
各阶段模型预处理示例如下图所示:
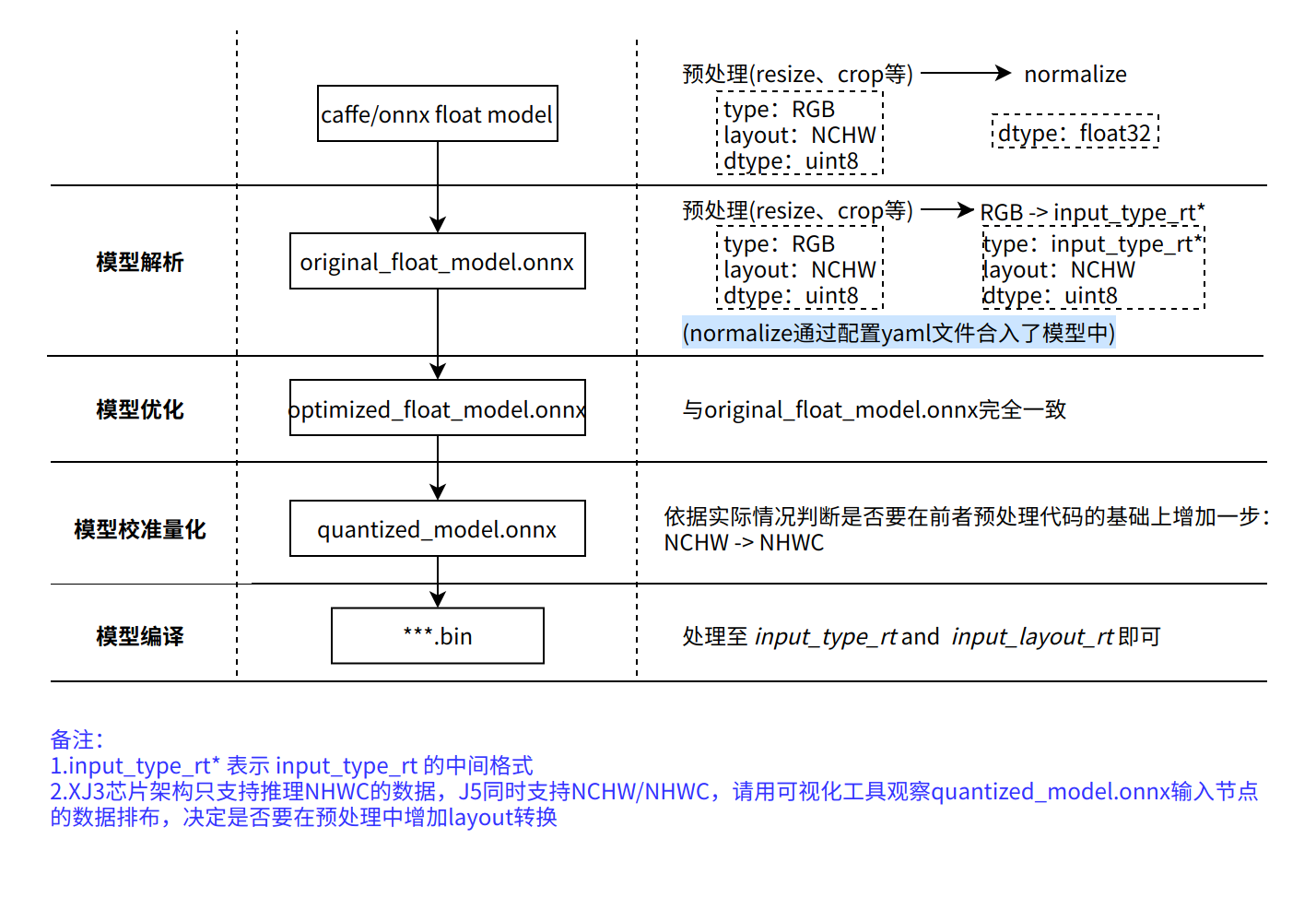
[预处理注意事项]
校准数据只需处理到input_type_train即可,同时也要注意不要做重复的norm操作。
1.3 python端与板端一致性校验
1.3.1 hb_model_verifier工具介绍
我们已经对该工具进行了升级,升级后的新工具为hb_verifier工具(J5 OE1.1.40/XJ3 OE2.5.2及以上版本可支持),我们推荐您优先使用新版工具,当前工具会在之后的版本中逐渐弃用。
hb_model_verifier 工具是用于对指定的定点onnx模型和bin模型进行结果验证的工具。 该工具会使用指定图片( 若未指定图片,则工具会用默认图片进行推理,featuremap模型会使用随机生成的tensor数据),进行定点模型推理,bin模型板端和x86端模拟器上的推理, 并对其三方的结果进行两两比较,给出是否通过的结论。
bin模型在板端的推理需确保给定ip可以ping通且板端已经安装 hrt_tools, 若无则可以使用OE包中 ddk/package/board 下的install.sh 脚本进行安装。
1.3.1.1 工具简介
1. 参数说明
定点模型名称。
--bin_model, -b
bin模型名称。
--arm-board-ip, -a
上板测试使用的arm board ip地址。
--input-img, -i
推理测试时使用的图片。 若不指定则会使用默认图片或随机tensor。 对于二进制形式的图片文件需要后缀名为 .bin 形式。
--compare_digits, -d
比较推理结果数值精度,若不指定则会默认比较小数点后五位。
2. 输出内容解析
结果对比最终会在终端展示, 工具会对比ONNX模型运行结果, 模拟器运行及上板结果的两两对比情况, 若无问题应显示如下:
在定点模型和runtime模型精度不一致时会输出不一致结果的信息并提示check FAILED。
1.3.1.2 使用示例
hb_model_verifier 目前只支持单输入模型。若模型有多个输出,则只会比较第一个输出的结果情况。暂时不支持对已打包的*.bin模型进行验证
1.3.2 hb_verifier工具介绍
hb_verifier 工具是用于对指定的定点onnx模型和bin模型进行结果验证的工具。 该工具会使用指定图片( 若未指定图片,则工具会用默认图片进行推理,featuremap模型会使用随机生成的tensor数据),进行定点模型推理,bin模型板端和x86端模拟器上的推理, 并对其三方的结果进行两两比较,给出是否通过的结论。同时该工具支持比对移除了Dequantize节点的.bin模型与定点onnx模型的比对。
1.3.2.1 工具简介
1. 参数说明
定点模型名称和bin模型名称,多模型之间用”,”进行区分。
上板测试使用的arm board ip地址。
设置是否使用X86环境的libdnn做bin模型推理,默认为False。
当该参数设置为 True 时,工具将会使用x86环境的libdnn做bin模型推理。
当该参数设置为 False 时,工具不会使用x86环境的libdnn做bin模型推理。
指定推理测试时使用的图片。
若不指定则会使用随机生成的tensor数据。
若指定图片为二进制形式的图片文件,其文件形式需要为后缀名为 .bin 形式。
多输入模型添加图片的方式有以下两种传参方式,多张图片之间用”,”分割:
input_name1:image1,input_name2:image2, …
image1,image2, …
设置比较推理结果的数值精确度(即比较数值小数点后的位数),若不进行指定则工具会默认比较至小数点后五位。
设置是否保存模型中各个算子的输出结果,并对算子输出名称相同的结果进行对比,默认为False。
当该参数设置为 True 时,工具将会获取模型中所有节点的输出,并根据节点输出的名字做匹配,从而进行对比。出于性能考虑,暂不支持在X86环境下使用 dump 功能。
当该参数设置为 False 时,工具将会只获取模型最终输出的结果,并进行对比。
结果对比最终会在终端展示,工具会对比多个模型在不同场景下的运行结果,若无问题应显示如下:
在定点模型和runtime模型精度不一致时会输出不一致结果的信息并提示check FAILED。
1.3.2.2 使用示例
1. quanti.onnx模型推理、.bin模型板端推理、.bin模型x86端推理结果对比:
2. quanti.onnx模型推理与.bin模型板端推理结果对比:
3. quanti.onnx模型推理与.bin模型在X86端推理结果对比:
4. .bin模型在板端和端推理结果对比:
5. 保存quanti.onnx模型推理、.bin模型板端推理过程中各个算子的输出,并对算子输出名称相同的结果进行对比:
1.3.3 hrt_model_exec infer工具介绍
1.3.3.1 参数说明
该命令也会输出单线程运行单帧的模型运行时间。
可选参数 | 说明 |
|---|---|
core_id | 指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 0。 |
roi_infer | 使能resizer模型推理;若模型输入包含resizer源,设置为 true,默认为 false。 |
roi | roi_infer 为 true 时生效,设置推理resizer模型时所需的 roi 区域以分号间隔。 |
frame_count | 设置 infer 运行帧数,单帧重复推理,可与 enable_dump 并用,验证输出一致性,默认为 1。 |
dump_intermediate | dump模型每一层输入数据和输出数据,默认值 0,不dump数据。 1:输出文件类型为 bin; 2:输出类型为 bin 和 txt,其中BPU节点输出为aligned数据; 3:输出类型为 bin 和 txt,其中BPU节点输出为valid数据。 |
enable_dumpdump | 模型输出数据,默认为 false。dump_precision控制txt格式输出float型数据的小数点位数,默认为 9。 |
hybrid_dequantize_process | 控制txt格式输出float类型数据,若输出为定点数据将其进行反量化处理,目前只支持四维模型。 |
dump_format | dump模型输出文件的类型,可选参数为 bin 或 txt,默认为 bin。 |
dump_txt_axis | dump模型txt格式输出的换行规则;若输出维度为n,则参数范围为[0, n], 默认为 4。 |
enable_cls_post_process | 使能分类后处理,目前只支持ptq分类模型,默认 false。 |
1.3.3.2 使用示例
1. 普通模型
2. resizer模型(J5 OE1.1.29后可支持,XJ3 OE2.4.2后可支持)
3. 移除了反量化节点的模型,仍然输出反量化后的浮点结果(J5 OE1.1.37后可支持,XJ3 OE2.5.2后可支持)
1.4 精度调优建议
经过大量实际生产经验验证,如果能筛选出最优的量化参数组合,地平线的转换工具在大部分情况下,都可以将精度损失保持在1%以内。依据精度损失情况,可参照以下建议进行解决:
1.4.1 精度损失明显(4%以上)
1. pipeline及模型转换配置检查
pipeline是指您完成数据准备、模型转换、模型推理、后处理、精度评测Metric的全过程。前文精度验证推荐的前两个步骤可以帮助您排查前后处理及yaml文件配置是否有误,精度评测Metric则需要您确保与原始浮点模型完全一致。
2. 数据处理一致性检查
该部分检查主要针对参考OE开发包示例准备校准数据以及评测代码的用户,主要有以下常见错误:
未正确指定read_mode:02_preprocess.sh中可通过--read_mode参数指定读图方式,支持opencv及skimage。此外preprocess.py中亦是通过imread_mode参数设定读图方式,也需要做出修改。使用 skimage的图片读取,得到的是RGB通道顺序,取值范围为0~1,数值类型为float; 而使用 opencv,得到的是BGR通道顺序,取值范围为0~255,数据类型为uint8。
校准数据集的存储格式设置不正确:目前我们采用的是numpy.tofile来保存校准数据,这种方式不会保存shape和类型信息,因此如果input_type_train为非featuremap格式,需要通过yaml中参数cal_data_type来设置二进制文件的数据存储类型。若为J5-OE1.1.16以及XJ3-OE1.13.3以前的版本,则会通过校准数据存放路径是否包含“f32”来判断数据dtype,若包含f32关键字,则按float32解析数据;反之则按uint8解析数据。
transformer实现方式不一致:地平线提供了一系列常见预处理函数,存放在/horizon_model_convert_sample/01_common/python/data/transformer.py文件中,部分预处理操作的实现方式可能会有所区别,例如ResizeTransformer,我们采用的是opencv默认插值方式(linear),若为其他插值方式可直接修改transformer.py源码,确保与训练时预处理代码保持一致。
精度debug工具计划于23年5月释放,包含节点敏感度分析、模型误差累计曲线绘制、节点统计量等分析功能。
1.4.2 精度损失较小(1.5%-3%)
1. 调整校准方式
① 手动指定 calibration_type,选择mix;(mix校准会先使用kl校准方式量化模型,取余弦相似度低于0.999的节点作为敏感节点,再分别使用max、max0.99995校准这些节点,取余弦相似度最佳的校准方式得到混合校准模型)
② 将 calibration_type 配置为 max,并配置 max_percentile 为不同的分位数(取值范围是0-1之间),我们推荐您优先尝试 0.99999、0.99995、0.9999、0.9995、0.999,通过这五个配置观察模型精度的变化趋势,最终找到一个最佳的分位数;
③ 在前面尝试的基础上选择余弦相似度最高的方案,尝试启用 per_channel。
2. 调准校准数据集
① 可以尝试适当增加或减少数据数量(通常来说检测场景相较于分类场景需要的校准数据要少;此外可以观察模型输出的漏检情况,适当增加对应场景的校准数据);
② 不要使用纯黑纯白等异常数据,尽量减少使用无目标的背景图作为校准数据;尽可能全面的覆盖典型任务场景,使得校准数据集的分布与训练集近似。
3. 将部分尾部算子回退到 CPU 高精度计算
① 一般我们仅会尝试将模型尾部输出层的 1~2 个算子回退至 CPU,太多的算子会较大程度影响模型最终性能,判断依据可通过观察模型的余弦相似度;(若将某些中间节点run_on_cpu,发现精度没有提升,这是正常现象,因为反复重量化可能还会带来更大的精度损失,因此通常只建议将尾部节点回退cpu)
② 指定算子运行在 CPU 上请通过yaml文件中的 run_on_cpu 参数,通过指定节点名称将对应算子运行在cpu上(参考示例:run_on_cpu: conv_0)。
③ 若run_on_cpu之后模型编译报错,请直接联系地平线技术支持人员




'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)



