
一:简介
ARM NEON 是ARM Cortex-A和Cortex-R系列处理器的一种SIMD指令集的扩展结构。其中SIMD表示单指令多数据指令,与之对应的是SISD,单指令单数据。早期的ARM指令集为通用计算型指令集,指令集都是针对单个数据进行计算,没有并行计算的功能。随着版本的更新,后面逐渐加入了一些复杂的指令以及并行计算的指令。而NEON指令是专门针对大规模的并行运算而设计的。 neon指令集的几个特点:寄存器被同一数据类型的元素的向量,例如float32x4_t 表示4个float数据构成的向量,可以放到一个四字的Q寄存器中。数据类型支持8/16/32/64bit的整数和单双精度浮点数。指令在所有通道中执行相同的操作,例如vmulq_f32(v_a, v_b) 表示将a向量和b向量中对应通道元素相乘。
Neon使用方法:
2. Neon instrinsics(c函数)
3. Neon assembly
xj3浮点转定点项目runtime实现中使用了Neon技术,主要用于相关cpu op的优化,对于使用custom op功能的客户,也可以用neon指令加速custom op的速度。
二:Neon Instrinsics
Neon intrinsics 函数为Neon操作提供C函数调用接口,编译器会将这些函数调用编译成相关的NEON指令。
几个常用函数介绍:
vdupq_n_type:用类型为type的数值,初始化一个元素类型为type的新vector的所有元素, 例如 float32x4_t v = vdupq_n_f32(3.5)
vldnq_type: 按交叉顺序将内存的数据装入neon的寄存器,并返回元素类型为type 纬度为n * (128/sizeof(type))的vector,例如:float32x4x4_t v = vld4q_f32(input), 表示从input指示的内存开始交叉加载16个数据,每四个一组构成二维数组的一行,最终返回4x4的一个vector,例如RGB分解,用vld3q_u8指令可以快速完成r, g, b的提取。
vstnq_type: 将元素类型为type 维度为n*(128/sizeof(type))的vector的所有元素装入内存。
vaddq_type:两个元素类型为type的vector对应通道元素相加,返回相加后的vector
vsubq_type:两个元素类型为type的vector对应通道元素相减,返回相加后的vector
vmulq_type: 两个元素类型为type的vector对应通道元素相乘,返回相加后的vector
vmlaq_type(a, b, c): 乘加操作 a+b*c
.........
三:示例
以两个简单示例介绍neon的使用
1. sigmoid(在xj3开发版上实测,速度可以优化4倍多)
2. 矩阵转置(以4x4矩阵为例,大矩阵可以切成4x4的矩阵块,再分别转置)
四:优化原则
先是c代码算法层面的优化,然后是intrinsics优化,最后是汇编优化。
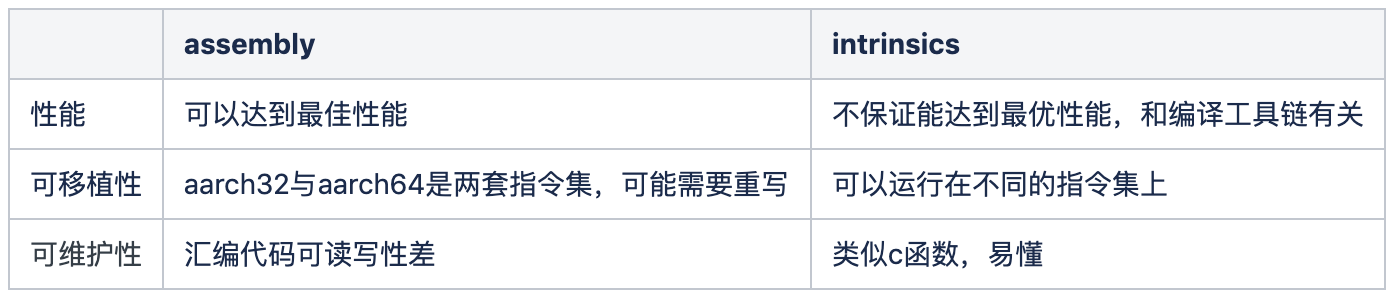
intrinsics与assembly方式对比
五:参考资料

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)