
为了加速BPU内存读写。针对BPU读写内存引入了对齐限制规则,主要包括包括起始地址要求,数据对齐等方面:
1. 起始地址要求:所有传入BPU的内存,起始地址都要求16字节对齐,内存物理空间必须为连续的。
2. 尺寸大小和奇偶限制:BPU原则上不限制模型输入大小或者奇偶,但是对于NV12输入比较特别,是为了满足UV是Y的一半的要求,它要求HW都是偶数。
3. Stride对齐要求:即本文所探讨的数据对齐的约束。
1. 数据对齐理解
如下图,绿色的部分是原始图片,黄色的部分是padding的部分,假如图片的原始宽度为org_w,原始高度为org_h。

假设对齐要求输入W是16的倍数,H是2的倍数,那么我们需要对org_w和org_h做padding。
对于BPU来说,数据输入采用NCHW或者NHWC的多通道数据输入,此时数据对齐的内容覆盖H,W,C三个维度,整体示意图如下所示。
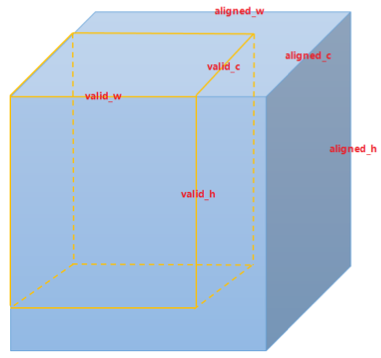
其中由黄色线条表示的valid_w,valid_h,valid_c即为原始数据尺寸,而aligned_w,aligned_h,aligned_c为对齐后的数据尺寸。
注意:在地平线数据对齐方案中,我们对Padding所填充的数据内容不关注,可以为原始输入类型范围内的任意值,BPU在实际进行计算过程中,只会对原始数据内容进行计算。
2. BPU对齐规则
虽然前面给出了BPU要求“输入W是16的倍数,H是2的倍数”的对齐假设。然而实际场景下,具体的对齐规则与模型以及编译器版本强关联。因此针对对齐规则不建议客户通过通过硬代码的方式来实现,而是基于模型的model_info进行获取,参考代码如下:
即通过模型BPU_MODEL_S元信息来获取模型输入和输出节点的shape和aligned_shape信息。并在构建hb_BPU_TENSOR_S对象时,直接利用指定节点的shape和aligned_shape信息来对hb_BPU_TENSOR_S的shape和aligned_shape字段进行字段填充。
3. Padding物理填充
构建BPU_TENSOR_S数据用于run_model推理时,除了准确的使用指定节点的shape来完整填充hb_BPU_TENSOR_S的shape信息以外,还有一个非常重要点就是:对输入数据数据的物理内存进行分配和填充,即BPU_MEMORY_S data和data_ext内存分配和填充。
但是注意注意:是否需要物理填充Padding对齐数据,和输入数据类型hb_BPU_TENSOR_S 的hb_BPU_DATA_TYPE_E是有直接关系,不同的数据类型的输入节点会有完全的不同的物理填充行为,其中完整hb_BPU_DATA_TYPE_E物理结构如下:
1. 以BPU_TYPE_IMG_开头为图像类型,目前支持的类型包括:单Y、YUV_NV12、YUV444、BGR、RGB、BGRP和RGBP。所有的图像的数据类型都是uint8类型,这也是符合图像数据定义的类型。
2. 以BPU_TYPE_TENSOR_前缀为Feature类型,目前支持int8、uint8、int32、uint32和float32类型的数据。
整体上是否需要物理进行填充的规则如下:
1. Feature类型数据需要严格按照aligned_shape大小来分配BPU_MEMORY_S data内存,并主动进行物理padding填充。
2. YUV444、BGR、RGB、BGRP和RGBP五种类型,在正确填写shape和aligned_shape基础上,可以直接用shape大小来分配BPU_MEMORY_S data内存,无需提前分配填充带来的内存空间,也无需业务手动进行填充,在HB_BPU_runModel接口内部,在数据预处理阶段,会自动进行内存填充。
3. Y和YUV_NV12,一般情况下,数据来源芯片内部的视频流通路,正常情况下,数据已经是做好了对齐和物理填充,此时在HB_BPU_runModel接口内部也不会自动进行填充。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)