
0、引言
接下来,我们会接着介绍 horizon_vision_tensorflow 中如何利用公开的 tensorflow 以及 horizon_plugin_tensorflow 中的量化 op 搭建并训练出一个检测模型,这里的检测模型我们以 SSD-mobilenetv2 为例,我们的训练数据集使用的是 PascalVOC 数据集。同样的,你不需要写代码就可以训练出一个 state-of-the-art 精度的 SSD 检测模型,从而对给定的一张图片可以检测出其中的目标物,如下图所示。这篇教程依旧是从模型搭建、数据集准备、开始训练这三个方面教大家如何上手我们的算法包。

1、算法包训练入口
正如前面所介绍的,我们的 horizon_vision_tensorflow 算法包提供了一套统一的训练和验证脚本,对于不同的任务,只需指定相应的配置文件,你可以不用去关注模型细节和超参数配置。因此你只需要运行如下命令,就可以训练出一个性能优越的 SSD-mobilenetv2 检测模型:
同样如果你只是想熟悉整个训练流程,暂时不需要一个精确的模型,可以运行下面的命令快速的结束整个训练过程,这也能帮助你更快的验证和调试程序。
当然,对于刚上手算法包的你来说,可能会遇到类似于数据集路径不对、预训练模型加载错误这些小问题,下面的教程将会详细告诉你如何提前配置好这些必要文件的路径。
2、SSD-mobilenetv2的定点模型搭建
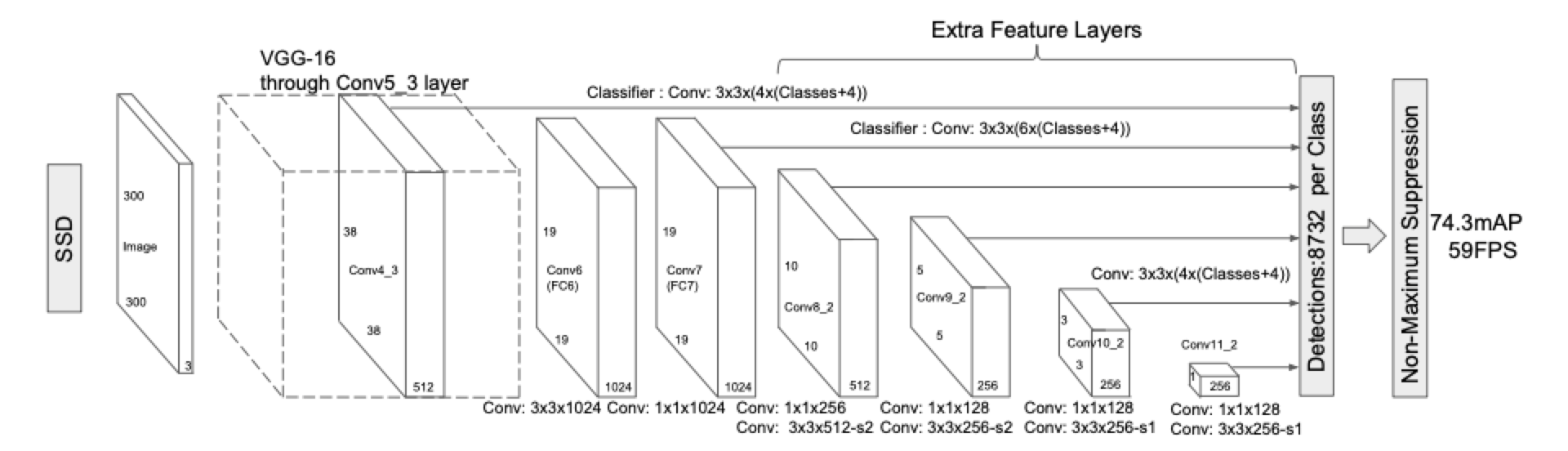
SSD的主要特征之一是使用了多尺度特征图用于检测,这一点从网络框架中便可以清楚的看到,其中比较大的特征图用来检测相对较小的目标,比较小的特征图用来检测大目标。SSD采用了VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图用于检测。SSD的细节这里就不做详细介绍了,大家可以阅读官方论文或者参考相应的网上资料。这里主要说明一下我们算法包实现的SSD模型和SSD官方论文相比主要有以下几点不同:
1) 论文使用VGG16作为Base network,我们采用的主干网络是MobilenetV2
2) 论文提取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2作为检测所用的6个特征图,我们提取MobileNet下采样为16和32的两层加上后接的四层卷积作为6个特征图
3) 论文中对Conv4_3做了L2 Normalization操作,我们的网络中没有这种处理
4) 论文中提供的模型输入包括512*512和300*300,我们提供的示例暂时只包含512*512
5) 论文中主干网络后面接的卷积之间添加了1*1卷积用于减小模型容量,我们的网络中没有添加
当然,我们的模型搭建中使用的op也都是 horizon_plugin_tensorflow 中的量化 op。
那么我们的配置文件是如何搭建 SSD-mobilenetv2 网络结构的呢?跟之前的 VargNetv2 一样,我们在构建SSDDetector这个类的时候,首先会利用horizon_vision_tensorflow提供的注册机制register_module将它注册到全局的 DETECTORS 中,接下来在配置文件中定义 model 这个字典参数时,只需要将 mode l的 type 关键字设为 SSDDetector 即可,model 中的其它关键字都是定义 SSDDetector 这个类时所需要的变量,这样当我们的程序读到 model 这个变量的 type 时,就可以根据字符串 “SSDDetector” 自动找到它的具体实现,从而实现网络结构的搭建。
3、数据集准备
同样,对于我们的检测任务,配置文件也提供了一系列的在线数据增强的办法,你可以关注一下配置文件中的 train_pipeline 和 val_pipeline 变量,分别对应着训练数据集的预处理和验证数据集的预处理,这里以 train_pipeline 为例详细说明一下。
每个 dict 对应着一种数据预处理的方式,主要包括颜色空间增强(ColorAug)、随机采样(RandomSamplePatch)、随机翻转(RandomFlipBbox)以及尺度调整(RandomResize)等。同样,这里的每个数据预处理操作也都是通过设置注册机制将每个相应的函数或者类注册到 TRANSFORMS 这个注册类里面,当训练脚本读取配置文件的时候,就可以根据这些 type 的名称自动找到它们的具体实现。
4、训练方法
SSD-mobilenetv2 模型的训练方法和上一节教程的 vargnetv2 的训练方法几乎一致,你只需要关注一下配置文件里面的workflow这个变量即可。需要注意的是,type类型为with_bn的dict里面有个pretrained_weight变量,表示的是我们的base network的权重,在这里也就是主干网络mobilenetv2的权重。我们需要提前训练好一个mobilenetv2的模型,并将这个模型放置到相应的路径下面即可。
5、开始训练
当你准备好数据集、base network的权重之后,就可以使用训练入口提供的脚本命令开始训练一个 SSD-mobilenetv2 的检测模型了。同样,这里你要根据自己的环境配置修改你的配置文件中的batch_size和context参数。当训练完成之后,你可以在models文件夹下面得到你的定点化模型,文件目录如下:
最终的文件同样是都包含with_bn、convert_with_bn、without_bn和convert_without_bn四个文件夹。
6、模型验证和一致性对齐
同样的,模型验证就是 workflow 中 compile 的过程,这一步是将训练产生的 pb 文件,利用 hbdk 提供的编译工具,变成可以上板运行的 hbm 文件。如果 model checker 已经没有问题的情况下,那么请放心,只要设置正确这一步就没有问题,并不需要担心花了很长时间训出来的模型不可编译。你会在当前目录下得到一个 .hbm 文件,代表模型验证通过。
如果你想知道自己训练出来的模型最终的性能如何,同样只需要运行如下命令就可以在验证集上测试一下模型最终的性能:
在验证过程中,你也会得到每张图片的可视化结果,及其相应的分类结果,如下所示:





当验证集的所有图片都跑完之后,会打印出mAP、Average Recall、Accuracy三个指标,反应着该模型的性能。这个值应该和模型最终在板子上跑出来的精度是一致的。如果你不需要显示每张图片的可视化结果,你可以将visualize这个参数设置为False即可。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)