
0、引言

在介绍本章教程之前,首先简单介绍一下地平线的 AI 工具链。这套 AI 工具链包含 horizon_plugin_tensorflow 量化框架和 horizon_vision_tensorflow 算法包两部分。horizon_plugin_tensorflow 负责提供量化训练的基本op和AI 芯片(BPU)所需的预测 op 以及一些权重量化的转换工具,而 horizon_vision_tensorflow 则是基于 tensorflow 和 horizon_plugin_tensorflow 开发的的算法包,包含一些常见的视觉算法任务,例如分类、分割、检测和实例分割等。
1、算法包训练入口
虽然这篇教程介绍的是一个分类任务,然而事实上,无论是分类、检测还是分割任务,horizon_vision_tensorflow 算法包都提供了一套统一的训练脚本和评测脚本,用户只需要指定相应的配置文件。对于本篇教程而言,你只需要提供相应的 vargnetv2 的配置文件。其中训练脚本提供用于训练的完整流程,而配置文件的内容会比较丰富,主要包含训练所需要的workflow,训练和验证数据集的加载pipeline以及其他网络训练所需要的超参数。如果你只是想利用 horizon_vision_tensorflow 训练出一个 state-of-the-art 精度的模型,而并不需要深入了解内部实现的逻辑,那么以 vargnetv2 为例,你只需要运行下面的命令即可:
完整训练一个基于 imagenet 的 state-of-the-art 精度的 vargnetv2 模型通常需要耗费较长的时间(不同性能的CPU和GPU时间也会不同),如果你只是想熟悉一下整个训练的 workflow,而暂时不需要一个精准的模型,那么你可以使用一个fast-mode模式来快速的完成整个训练。 Fast-mode 只提供一个训练 epoch,同时每个 epoch 迭代的 step 很少,所以可以很快结束。这也可以用来帮助客户快速而方便的调试和验证程序是否正常运行,体现了我们算法包更好的成就客户的心态。
当然,如果你没有提前准备好训练和验证的数据集,直接运行这条命令会报错,这也是下面章节需要介绍的内容。这一部分主要是为了让大家感受到horizon_vision_tensorflow算法包设计的友好性和简洁性,不论内部逻辑是多么的复杂,对新手用户的使用入口都尽量做到设计友好、快速上手。用户也可以很容易的修改配置文件中的num_classes,backbones等常见的配置,来达到切换数据集,切换模型的目的,事实上很多我们的客户已经在这么做了。
2、VargNetv2定点模型的搭建
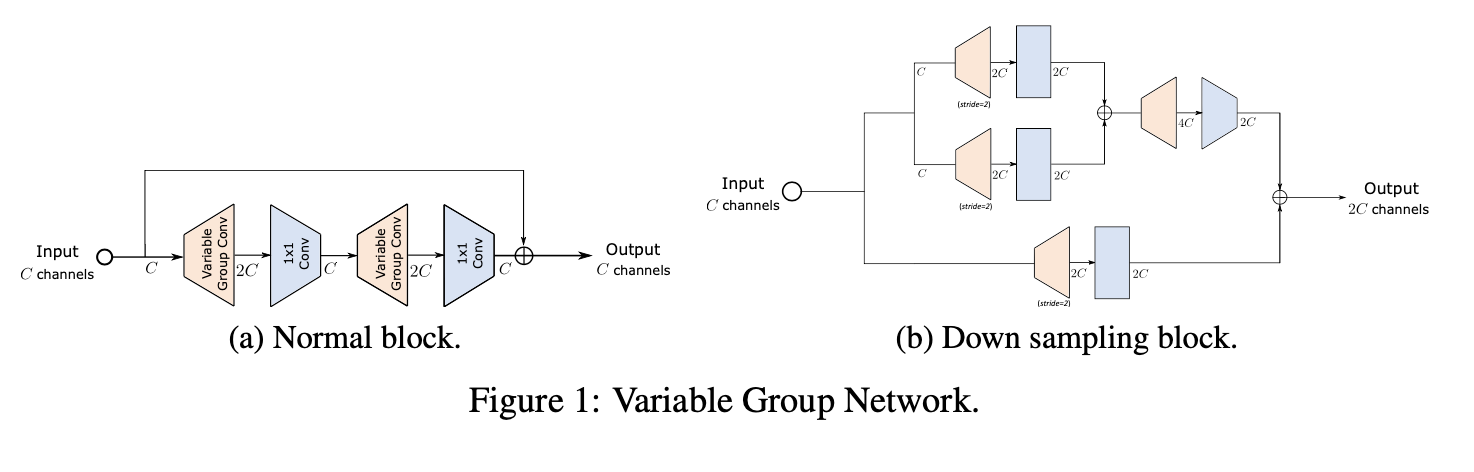
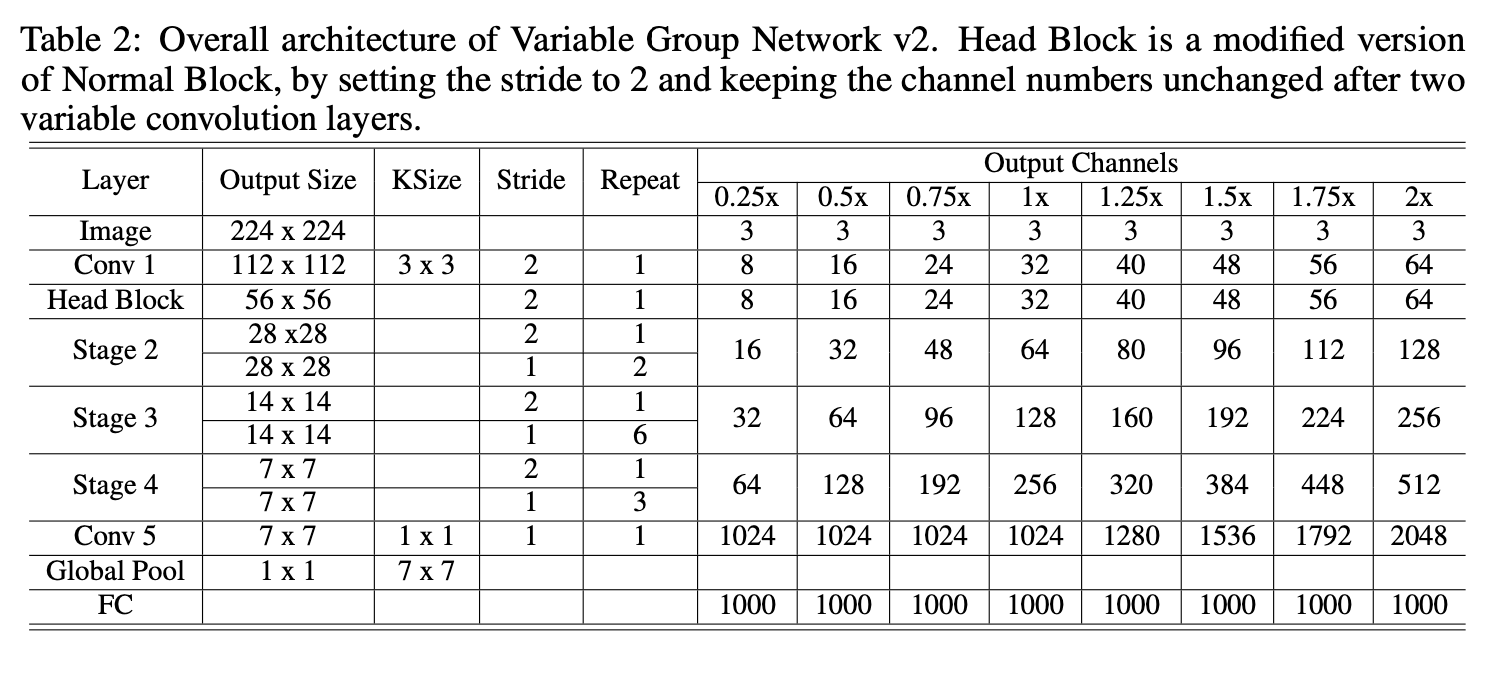
整个网络结构的构建可以参考下表:
原始论文中的相应指标都是基于浮点模型得到的。基于horizon_plugin_tensorflow量化框架搭建定点模型的时候,只需要将相应的卷积相关操作换成定点卷积操作即可,以普通卷积为例:tensorflow中原始的卷积操作为tf.keras.layers.Conv2D,而horizon_plugin_tensorflow提供的卷积操作为horizon_plugin_tensorflow.keras.layers.QuantiConv2D,这和原始卷积的操作并不是完全等价的。Horizon_plugin_tensorflow.keras.layers.QuantiConv2D除了具有常见的Conv2D和量化操作之外,还具有BatchNormalization,Relu的功能。因此一个QuantiConv2D的操作等价于Conv2D+BN+Relu。同时QuantiConv2D除了具备量化操作的功能之外,也具备float的功能。QuantiConv2D在QuantiScope的作用下可以有条件的切换QuantiConv2D的执行模式,当QuantiScope中的qnn_mode为kFloatTraning的时候,QuantiConv2D和原始的Conv2D+BN+Relu具有相同的操作意义。根据以上介绍的替换方法,便可以基于horizon_plugin_tensorflow的量化操作算子搭建出一套量化的Vargnetv2模型。这一部分听起来可能有点复杂,需要结合horizon_vision_tensorflow的源码来理解,你可以暂时不去管这些,先把模型跑通,清楚整个流程之后,再来理解这些。
接下来介绍我们提供的参与训练的配置文件中是如何使用定义好的Vargnetv2作为训练Imagenet过程中使用的backbone的。定义好的vargnetv2会利用horizon_vision_tensorflow的注册机制提供的register_module注册在全局的BACKBONES上,然后只需要在定义配置文件中的model变量的时候,定义一个classifier的模型,同时backbone使用VargnetV2作为对应的type即可,具体如下:
当我们指定了一个配置文件之后,程序就会自动去搜索配置文件中的model变量里面的type参数,根据type参数的名称可以找到相应的结构的具体实现,从而完成网络结构的搭建。
有时候你并不满足训练一个已有的模型,那么如何定义一个自己的backbone呢,我们的建议是接下来要介绍的,这也是我们在开发horizon_vision_tensorflow过程中用到的思路。
(1)、定义好自己的网络,并通过BACKBONES.register_module注册到全局。这个过程既可以使用自定义的函数,也可以使用自定义的类,注册的结果返回的是函数或者类本身。
(2)、如果是一个单独的文件,那么需要在models/backbone/__init__.py 中import对应的文件,这么做的目的是使得在引用之前CustomBackbone已经注册好了,可以直接调用。
(3)、在config中使用类似Vargnetv2的方法直接申明一个以CustomBackbone为基础的分类网络。
通过这种方法,你就可以自定义分类网络,并完成相应的训练
3、数据集准备
horizon_vision_tensorflow算法包提供的模型大多数都是在一些公开数据集上训练得到的,例如imagenet、PascalVOC、mscoco、cityscapes等,你需要提前下载好这些数据集,或者仅下载你需要用到的数据集。如果你不想改动任何代码,可以将这些数据集软链接到或放置在当前目录的data文件夹下,你的文件目录结构应该像下面这样:
为了提升数据的读取效率和减少训练时间,最终参与训练的数据集都是tfrecord格式的,因此我们需要提前将图片格式的数据集打包成tfrecord格式的数据集。这里算法包提供了一套统一的用于数据集打包的脚本toos/im2tfrec.py, 你只需要指定希望打包的数据集所对应的配置文件即可。例如,对于分类任务而言,你需要将图片格式的数据集打包成tfrecord格式,只需要运行如下命令即可:
所有的数据集打包的配置文件都在configs/datasets这个文件夹下。当所有的数据集都打包完成之后,你的文件目录应该像下面这样:
我们都知道,为了提升模型的泛化性能,数据增强通常是应用最广泛的一种方式。VargNetv2分类模型的训练同样也用到了数据增强,并且在相应的配置文件中以一种数据流的方式展示出来。每个配置文件中都提供了train_pipeline和val_pipeline两个变量,分别对应着训练数据集和验证数据集的预处理,训练数据集的预处理中就包含着丰富的数据增强。如下所示:
验证集的预处理则简单的多,唯一特殊的就是crop方法,是按照短边resize到256大小,然后从中心剪裁一个224x224大小的图片出来,同样需要进行格式的转换和归一化操作。
这里之所以可以通过一个dict定义一种数据预处理的方式,同样是因为使用了注册机制。每一个type变量所对应的函数或者类都提前注册到TRANSFORM里面,从而可以通过在配置文件中调用函数名来调用函数实体。你同样可以利用这种方式扩充数据增强的种类,并在配置文件中调用。
4、训练方法
模型搭建、数据准备完成之后,就可以开始训练了。虽然horizon_vision_tensorflow算法包是为了定点训练开发,但是也提供了浮点训练的方式,这个在上文说的op替换中也有介绍。你可以关注一下相应配置文件中的workflow这个列表变量,里面包含着五个字典元素,每个元素根据type的不同对应着不同的状态,分别是:
训练模型的时候,我们只需要关注前四个元素。它们都有skip这个关键字,当skip=True的时候,表示训练的时候跳过这一阶段,反之,则会运行这一阶段。由于我们需要训练的是一个定点模型,因此只需要设置with_bn和without_bn的skip为False即可。定点模型的训练都是需要经过with_bn和without_bn两个阶段。Model checker的作用是为定点模型能否在BPU上运行提前做一次检查,只有满足条件的网络结构才可以实际运行在BPU上,这个在前面的课程中也有详细的介绍,所以model checker也是量化训练中很重要的一步。
每个字典元素都包含着差不多类似的关键字,type表示对应的训练阶段,pretrained_weight表示预训练模型的路径,epoch表示整个训练完成的epoch次数,metric表示衡量模型效果好坏的指标,loss表示模型的损失函数,optimizer为模型训练的优化器,callbacks定义了我们训练过程中学习率的变化以及模型保存的路径。
正如上面已经介绍的,定点训练有两个阶段。因此对于两个阶段的学习方法,我们这里可以给出一些建议。通常在withbn阶段的学习方法可以直接参考公版通用情况下的float设置,理想情况下不需要改变任何训练超参(有时候需要延长一定的epoch,因为量化相当于一个很强的正则)即可训出不错的模型。withoutbn和withbn阶段最大的区别在于,withoutbn依赖于withbn的结果,在吸收BN之后做一个量化结果的finetuning,因此这个阶段的lr不能很大,否则会破坏withbn阶段训出来的模型,当然这个也看情况而定。
除此之外,两个阶段的loss,metric均才用相同的设置。
5、开始训练
了解了这些背景之后你就可以根据自己的情况训练一个定点模型了,考虑到硬件环境的差异(显卡数量、每张卡的内存),你可以视情况修改配置文件中的batch_size大小和context数量。默认使用的是4卡,batch_size大小为256。此时如果你已经按照第3节介绍的准备好数据集,就可以直接运行第1节介绍的命令开始训练模型了。
当训练完成之后,你可以在models文件夹下面得到你的定点化模型,文件目录如下:
我们的训练工具一方面在训练脚本上做到了统一,同时生成的量化模型文件结构也是统一的。无论是分类、分割还是检测任务,最终的文件都包含with_bn、convert_with_bn、without_bn和convert_without_bn四个文件夹,相同文件夹下面的文件名称也都是一样的。
6、模型验证和一致性对齐
模型验证就是workflow中compile的过程,这一步是将训练产生的pb文件,利用hbdk提供的编译工具,变成可以上板运行的hbm文件。如果model checker已经没有问题的情况下,那么请放心,只要设置正确这一步就没有问题,并不需要担心花了很长时间训出来的模型不可编译。你会在当前目录下得到一个.hbm文件,代表模型验证通过。
当模型训练完成之后,你通常想知道这个模型的性能如何,以及本地验证结果和上板精度是否对齐。我们的算法包同样提供了这样一套精度一致性对齐的方法。用户只需要指定相应模型的配置文件即可得到和上板完全一致的精度。在本教程中,当你想知道训练出来的VargNetV2性能如何,只需要运行如下指令即可:
为了得到和上板完全一致的性能,我们单独提供一个align_bpu_pipeline的数据预处理方法,这套方法作为模型inference前处理是和板子上实际执行的预处理是完全一致的。同样的,对于配置文件中的align_bpu_pipeline关键字,你需要把data_dir和data_list修改为自己的路径就可以正常运行。
在验证过程中,你会得到每张图片的可视化结果,及其相应的分类结果,如下所示:

label: rock python

label: ski

label: Shetland sheepdog
当验证集的所有图片都跑完之后,会打印出acc指标,代表着该模型的精度。这个值应该和模型最终在板子上跑出来的精度是一致的。当然如果你不需要显示每张图片的可视化结果,只需要将visualize这个参数设置为False即可。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)