
AI开发流程
——算法部分
引言
在这个部分,你将会了解到在96board上面你能够实现的算法功能(有:classification (分类),detection(检测),segmentation(分割), instance segmentation,示例如图1),训练能够在96board上面使用的模型需要的步骤(量化训练,模型编译),以及地平线为大家方便实现整个流程提供的工具。
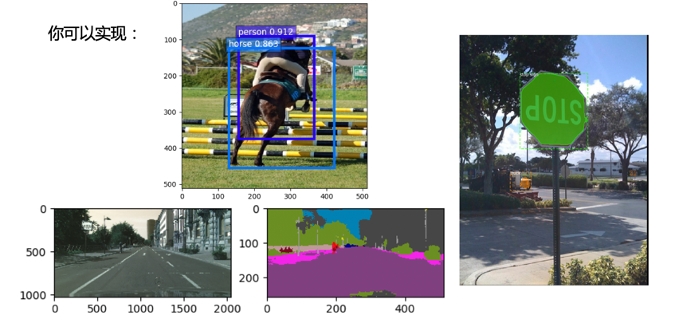
图表 1:96board上你能够实现的算法功能示例
具体地说,在算法功能的部分,你能够实现的如图2所示的算法,覆盖了大量的比较常用的轻量型模型结构,以及主流的benchmark如Imagenet, MSCOCO等。通过我们提供的解决方案,你可以高效便利地在96board上面实现并且应用这些算法
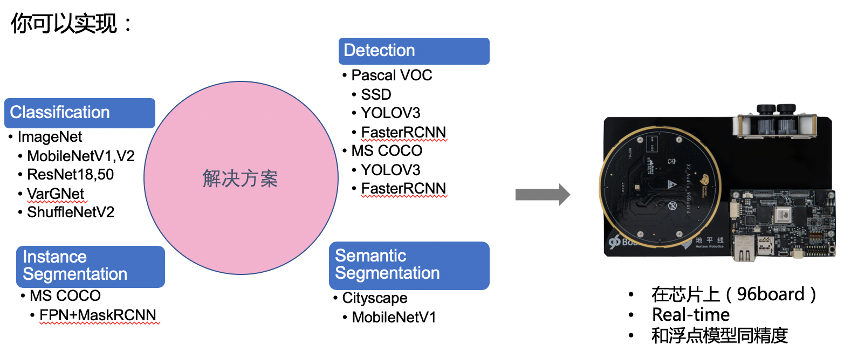
图表 2
这里要引入一个概念,解决方案。解决方案就是地平线根据不同的算法功能提供的将环境搭建,模型搭建,算法实现,模型训练,模型编译都实现好,以及串在一起,进行数据和参数简单调整后就能够得到在96board上面使用的模型的工具和代码实现。使用地平线提供的算法解决方案,可以很容易地得到能够在96board上面跑的实时的,和GPU上面训练类似精度的模型。
先验知识
图表 3
深度学习或者机器学习算法之所以成为学习,是因为他们能够去设置一个loss function,然后这对于这个loss function的结果对模型的参数进行调整,如图4. Loss function是使用预测结果和真实结果(ground truth)来计算一个损失,然后通过梯度下降的方法把损失往回传给网络的每一层,以此来更新模型参数。
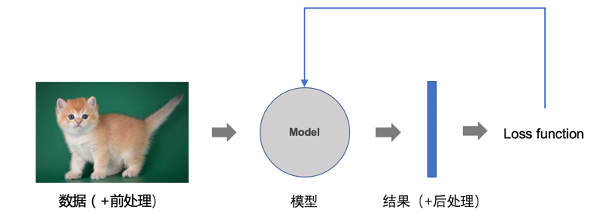
图表 4
图表 5
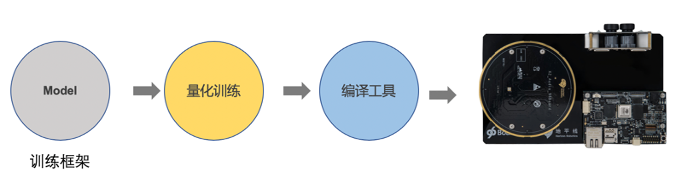
在地平线的解决方案中,变为大家提供实现以上流程的工具:docker帮助便捷搭建环境, Tensorflow(MXNet) plugin帮助量化训练, 编译工具编译模型,见图6.
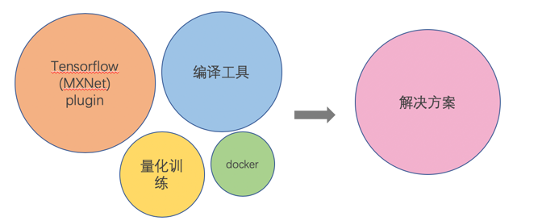
图表 6
Workflow
整体的开发流程workflow如图7所示,首先是环境搭建,可以使用我们提供的docker方便快捷在linux上面搭建环境。然后是模型搭建,可以使用我们提供的TensorFlow(MXNet) plugin。紧接着就是量化训练,使用我们推荐的量化模型训练流程,可以得到定点模型。最后是模型编译,使用我们提供的编译工具能够把模型转化为能够在96board上面使用的格式。
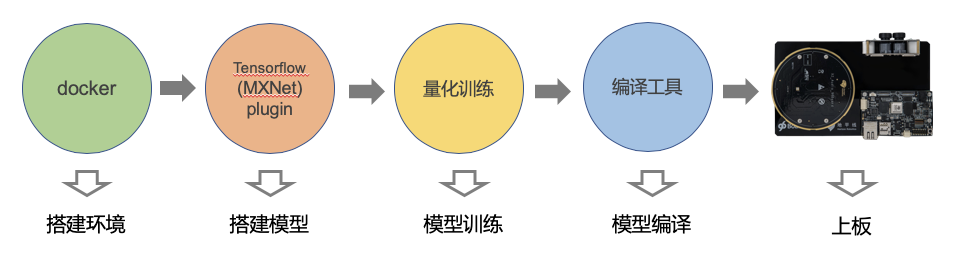
图表 7
接下来我们介绍每个部分。
l Docker
安装教程主要参考:(后续开放)

图表 8
在算法部分主要涉及到到是HBDK包,TensorFlow Horizon算法包,这些在TensorFlow镜像(docker)里面都已经包含。所以直接安装docker就可以进行算法相关的模型训练和编译了。要特别提到的是其他环境的支持,如图9,需要Python3.6版本以及CUDA10.
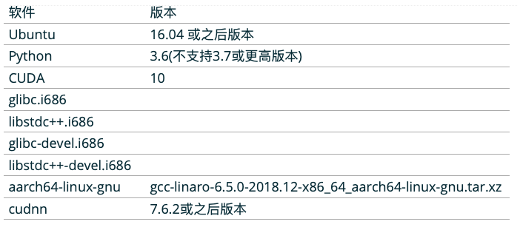
图表 9
l TensorFlow plugin
接下来是训练框架工具,TensorFlow plugin的介绍。我们提供的horizon_plugin_tensorflow包里面包含如图10。

图表 10
(后续开放)
因为96board上面数据输入的格式是YUV格式,而不是我们常用的RGB的格式,所以需要使用我们提供的data augmentation工具在数据读入之后做预处理再送入网络。

图表 11
(后续开放)
l 量化训练
(后续开放)

图表 12
(后续开放)
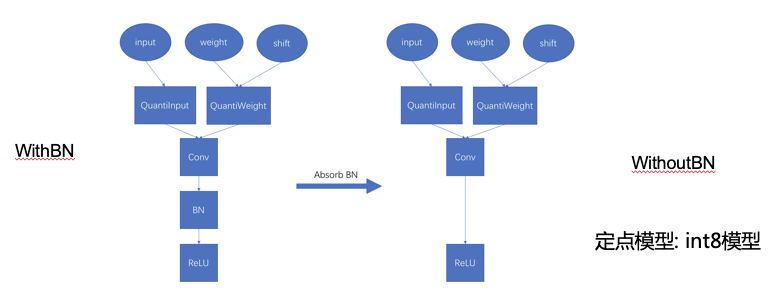
图表 13
在我们讲解完量化训练之后,我们可以再回到我们在TensorFlow plugin中提供的五种mode。这里详细介绍其中四种mode,如图14。其中kFloatTraining mode就是一般在GPU上面使用的浮点训练方式,在定点模型训练中不是必要的步骤。kTrainingWithBN是刚刚我们提到的量化训练第一阶段。kTrainingWithouBN是刚刚我们提到的量化训练的第二阶段,吸收BN的参数,没有BN层的阶段。kIntInference是进行定点模型inference的mode。

图表 14
l 编译工具
在模型训练完毕之后,我们会得到模型文件比如用TensorFlow进行训练的话会得到pb文件,用MXNet进行训练的话会得到params和json文件。有了这些文件之后我们需要用编译工具进行模型编译,得到能够在芯片上面使用的目标文件.hbm。这样的模型编译可以使用我们提供的编译工具X2/J2 Compilation Tools (HBDK)进行实现。我们的编译工具提供的功能如图15所示。

图表 15
想到得到编译好的模型其实使用模型编译工具hbdk-cc就可以了,但是我们提供了很多其他功能,是因为在模型编译好之后的验证工作非常重要。要进行模型编译之后的验证工作,需要提前了解三个概念:BPU开发板,BPU模拟器和TensorFlow预测库。BPU开发板也就是我们使用的96board,搭载了我们的BPU芯片。BPU模拟器是模型编译工具提供的可以在PC上面模拟BPU开发板inference效果的模拟器。TensorFlow预测库就是在X86上面能够使用的可以进行定点模型inference的预测库。我们编译好的模型验证方式就是比对这三种平台上面输出的结果(相同输入输出数值)是否一致,如图16(BPU对应BPU开发板,simulator对应BPU模拟器)。如果一致,那么模型编译就没有问题,编译好的模型可以上板使用。如果不一致,那么其中可能某些环节产生了问题,可能存在bug,需要反馈给我们的技术支持人员进行调试。
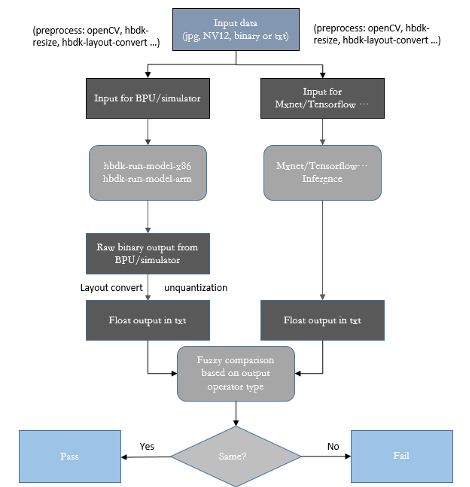
图表 16
相关参考:(后续开放)
总结
到此,我们整个AI开发流程的算法部分的就基本介绍完毕了。回顾一下,我们的算法开发流程一共有四个阶段,第一个阶段是环境搭建(docker),第二个阶段是模型搭建(TensorFlow Plugin), 第三个阶段是量化训练,第四个阶段是模型编译。每个阶段你可以参考的资料我汇总如下,希望能够帮助到你。如果有其他不了解的问题,可以在社区发帖提问,或者将问题发邮件到我的邮箱(mengjia.yan@horizon.ai),我会帮助大家解答问题。
环境搭建: 后续开放
模型网络结构和op限制:后续开放
量化训练:后续开放
模型编译:后续开放

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)