
1. 引论:写在前面的
性能评估和精度评估在模型开发和部署过程中是至关重要的两个部分。对于精度评估,地平线算法工具链提供了两中路径进行算法的精度评估。一条为服务器端精度评估,该路径通过PYTHON脚本使用PYTHON推理接口进行板端推理仿真,运行.BC或quantized.onnx量化量化模型以获取推理结果并进行后处理后与真值进行对比,最终计算出量化模型的精度;另一条另则是直接在板端推理量化后的hbm模型,获取推理结果,然后下载推理结果到服务器端并通过PYTHON评估脚本结合真值进行进行计算,最终计算出量化模型的精度。因为后者是在板端进行推理,可以充分利用硬件加速过程,在速度上相比服务器仿真要高效很多,不过,限于板端存储限制,评测所需要的大数据集还需要通过NFS在板端使用。
本文以bevformer精度评估为例,引到读者从评测环境构建到评测数据准备,最后到精度评测试试和最终结果计算的整个流程,以期给您一个进行板端精度评测的一个流程全貌。
2. 环境准备和评测实施
整个评测过程涉及 评测所用的数据集文件准备、NFS服务端安装和板端目录挂载、评测程序准备和相关文件配置、评测执行和结果收集 以及 评测结果计算 等5个小环节。其中评测所用的数据集文件准备、NFS服务端安装、评测结果结算是在服务器端进行,而板端目录挂载、评测程序准备和相关文件配置、评测执行和结果收集为板端执行部分。下面为针对这写过程逐步为大家展开说明。因为测评过程是基于算法工具链进行的,所以在开始测评之前需要大家先配置好工具链的docker环境并关在OE示例包。我这里以J6的OE-3.0.22为例进行说明,另外为了加速测试过程,这里仅以mini数据集加以阐述。
2.1 评测所用的数据集文件准备
下载的nuScenes的v1.0-mini.tgz、nuScenes-lidarseg-all-v1.0.tar.bz2、nuScenes-map-expansion-v1.3.zip和can_bus.zip后进行解压,解压后的目录如下所示:
在nuscenes下创建meta文件夹,将解压后的v1.0-mini文件夹、maps文件夹、lidarseg文件夹拷贝到meta文件夹内,构建如下:
进入工具链的/samples/ucp_tutorial/dnn/ai_benchmark/j6/qat/tools/eval_preprocess/目录修改bev_preprocess.py、
修改前 | 修改后 |
|---|---|
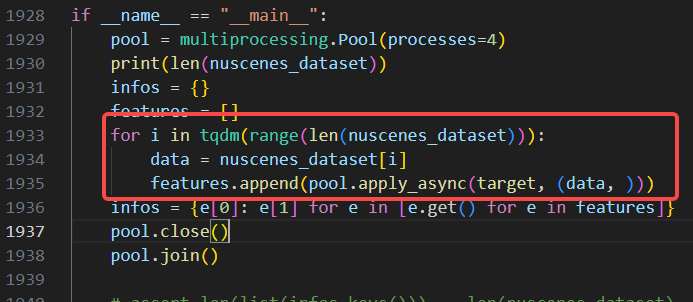 | 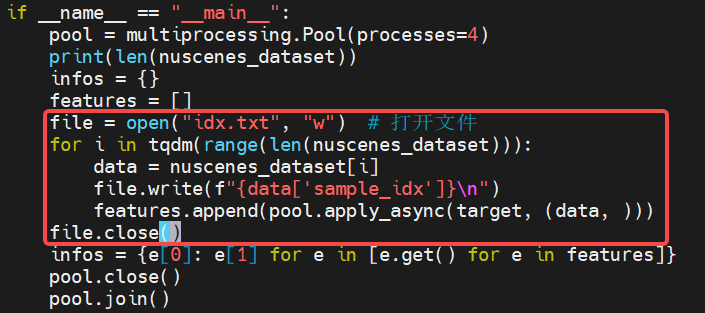 |
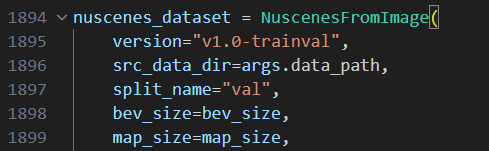 | 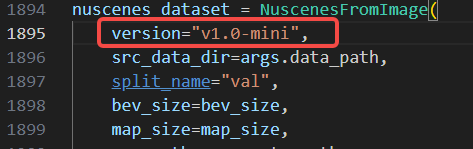 |
- 修改bev_preprocess.py后执行下列命令:
python3 bev_preprocess.py --model=bevformer_tiny_resnet50_detection_nuscenes --data-path=/data_set/nuScenes_mini --meta-path=/data_set/nuScenes_mini/meta --reference-path=../../script/config/reference_points --save-path=./nuscenes_bev_mini注:/data_set/nuScenes_mini 为上述准备的数据集的目录
上述命令执行后生成nuscenes_bev_mini目录(其中包含gt信息val_gt_infos.pkl)和idx.txt,他们作为精度评测过程依赖文件,在NFS server构建之后可以拷贝到NFS分享目录中,将来在板端挂载后使用。
2.2 NFS服务器安装、配置 以及 板端挂载使用
2.2.1 NFS服务器安装和配置( 此处为ubuntu2204系统 )
安装和启动
创建共享目录
- 使用命令 sudo vi /etc/exports 编辑配置文件,末尾添加如下内容:
/mnt/nfs_share *(rw,sync,no_subtree_check,insecure,no_root_squash) - 使用命令sudo systemctl restart nfs-server重启NFS服务
### 2.2.2 NFS板端挂载和可用性验证
创建挂载目录
mkdir -p /userdata/nfs
挂载NFS共享目录(这里假设服务器IP为:192.168.1.6)
sudo mount -t nfs 192.168.1.6:/mnt/nfs_share /userdata/nfs


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)