
技术背景
YOLOv5是一种高效的目标检测算法,尤其在实时目标检测任务中表现突出。YOLOv5通过三种不同尺度的检测头分别处理大、中、小物体;检测头共包括三个关键任务:边界框回归、类别预测、置信度预测;每个检测头都会逐像素地使用三个Anchor,以帮助算法更准确地预测物体边界。
本文主要提供以下几方面的指导:
1、对pytorch模型做适当的调整并导出onnx
2、以合适的方式准备校准数据并编译上板模型
3、板端部署时正确准备输入数据
4、进行反量化后处理融合以降低延时
5、提供正确的板端性能评测方法
模型输入输出说明
从pytorch导出的onnx模型,具体的输入输出信息如下图所示:
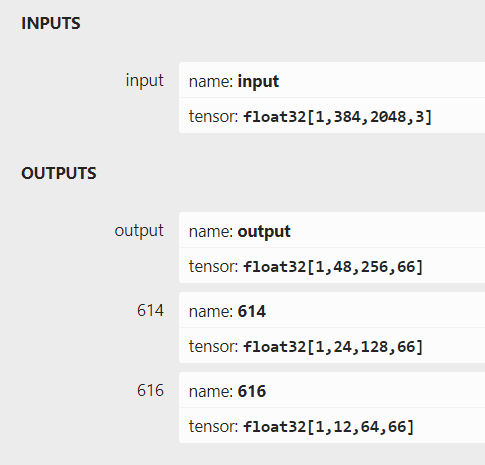
本示例使用的yolov5n模型,相较于公版在输入和输出上存在以下几点变动:
1、输入分辨率设定为384x2048,对应输出分辨率也调整为了48x256,24x128,12x64
2、类别数量设定为17,因此输出tensor的通道数变为了(17+4+1)x3=66
3、模型输入端插入了一个transpose节点,这样模型可以直接读取NHWC的输入数据

4、为了优化整体耗时,模型尾部的sigmoid计算被放在了后处理
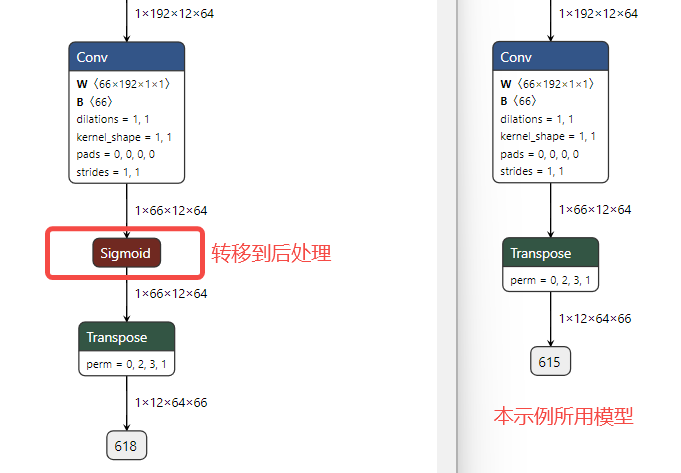
此外本文使用的v5n模型扩充了一定参数量,介于官方的v5n和v5s之间,因此推理耗时会比普通的v5n略高。
模型导出注意事项
因为pytorch模型训练时的layout通常都是NCHW,而opencv读图之后的layout都是NHWC,因此为了部署时的预处理更加简单高效,我们建议给pytorch模型的输入节点增加一个transpose,这个transpose的作用是把NHWC转换成NCHW(对应0312的参数),从而将提供给模型的输入数据从NCHW更改为NHWC,以契合opencv读到的数据。可参考如下代码,更改后再导出onnx。
工具链环境
全部工程基于OE 1.2.8进行。
PTQ量化编译流程
准备校准数据

先准备100张如上图所示的色选机数据集图片存放在seed100文件夹,之后可借助horizon_model_convert_sample的02_preprocess.sh脚本帮助我们生成校准数据。
02_preprocess.sh
preprocess.py
校准数据仅需resize成符合模型输入的尺寸,并按照HWC转换成RGB即可。
配置yaml文件
input_type_rt指模型在部署时输入的数据类型,这里使用rgb
input_layout_rt指模型在部署时输入的数据排布,由于rgb本身就是NHWC,且为了简化预处理,这里使用NHWC
input_type_train指浮点模型训练时使用的数据类型,这里使用rgb
input_layout_train指浮点模型训练时使用的数据排布,虽然pytorch原生是NCHW,但由于我们在输入处插入了transpose节点,因此这里使用NHWC
norm_type和scale_value根据浮点模型训练时使用的归一化参数设置,这里配置scale为1/255(mean和scale的具体计算方法可参考文章 https://developer.d-robotics.cc/forumDetail/71036815603174578)
编译上板模型
执行以上命令后,即可编译出用于板端部署的bin模型。
根据编译日志可看出,yolov5n模型的三个输出头,量化前后的余弦相似度均>0.99,符合精度要求。
Runtime部署流程
在算法工具链的交付包中,ai benchmark示例包含了读图、前处理、推理、后处理等完整流程的C++源码,但考虑到ai benchmark代码耦合度较高,有不低的学习成本,不方便用户嵌入到自己的工程应用中,因此我们提供了基于horizon_runtime_sample示例修改的简易版本C++代码,只包含1个头文件和1个C++源码,用户仅需替换原有的00_quick_start示例即可编译运行。
通常来说,模型编译完成后,尾部会有CPU计算的反量化节点。一个常见的优化策略是将反量化计算和后处理一起运行,节约一遍数据遍历次数,从而降低耗时。本文同时提供了不删除反量化算子和删除反量化算子的后处理代码示例。反量化融合的具体原理和实践参考可以阅读这篇文章:
https://developer.d-robotics.cc/forumDetail/116476291842200072
头文件
该头文件内容主要来自于ai benchmark的code/include/base/perception_common.h头文件,包含了对argmax和计时功能的定义,以及目标检测任务相关结构体的定义。
源码
为方便用户阅读,该源码使用全局变量定义了若干参数,请用户在实际的应用工程中,避免使用过多全局变量。代码中已在合适的位置添加中文注释。需要特意说明的是,置信度阈值使用了score_threshold_objness和score_threshold两个变量,第一个需要设置成经过sigmoid反函数的值,比如原来设置的0.2,那么sigmoid经过反函数以后的值大概是-1.38,这样设置可以大大降低后处理的时间,第二个变量则是正常的置信度阈值,通常二选一即可。
这里强调一下read_image_2_tensor_as_rgb函数:
由于input_type_rt配置为rgb/bgr时,板端模型的输入是int8,而不是uint8,
因此需要用户在预处理中遍历所有输入数据手动做-128处理,
未来的工具链版本会针对RGB输入场景做更多的适配,以避免这种额外操作。
运行说明
用户可将头文件和源码放入horizon_runtime_sample/code/00_quick_start/src路径,并执行build_x5.sh编译工程,
再将horizon_runtime_sample/x5文件夹复制到开发板的/userdata目录,
并在/userdata/x5/script/00_quick_start/路径下存放上板模型、测试图片等文件,并编写板端运行脚本:
运行结果如下(以未删除反量化的模型为例):
对于这次推理,我们的输入图像为下图:

可以看到,推理程序成功识别到了目标物体,并且给出了正确的坐标信息:
模型推理耗时说明
需要强调的是,应用程序在推理第一帧的时候,会产生加载推理框架导致的额外耗时,因此运行该程序测出的模型推理耗时是偏高的。
准确的模型推理时间应当以hrt_model_exec工具实测结果为准,参考命令:
hrt_model_exec perf --model-file ./yolov5n.bin --thread-num 1(测试单线程单帧延时,关注latency)
hrt_model_exec perf --model-file ./yolov5n.bin --thread-num 8(测试多线程极限吞吐量,关注FPS)
耗时优化对比
是否做反量化后处理融合 | 前处理-128时间 | 模型单线程推理时间 | 后处理时间 | 总耗时 |
否 | 0.7ms | 7.6 ms | 1.5 ms | 9.8 ms |
是 | 0.7ms | 4.6 ms | 2.9 ms | 8.2 ms |


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)

