
该示例为参考算法,仅作为在J6上模型部署的设计参考,非量产算法
简介
在自动驾驶视觉感知系统中,为了获得环绕车辆范围的感知结果,通常需要融合多摄像头的感知结果。目前更加主流的感知架构则是选择在特征层面进行多摄像头融合。其中比较有代表性的路线就是这两年很火的BEV方法,继Tesla Open AI Day公布其BEV感知算法之后,相关研究层出不穷,感知效果取得了显著提升,BEV也几乎成为了多传感器特征融合的代名词。但是,随着大家对BEV研究和部署的深入,BEV范式也逐渐暴露出来了一些缺陷:
感知范围、感知精度、计算效率难平衡:从图像空间到BEV空间的转换,是稠密特征到稠密特征的重新排列组合,计算量比较大,与图像尺寸以及BEV 特征图尺寸成正相关。在大家常用的nuScenes 数据中,感知范围通常是长宽 [-50m, +50m] 的方形区域,然而在实际场景中,我们通常需要达到单向100m,甚至200m的感知距离。 若要保持BEV Grid 的分辨率不变,则需要大大增加BEV 特征图的尺寸,从而使得端上计算负担和带宽负担都过重;若保持BEV特征图的尺寸不变,则需要使用更粗的BEV Grid,感知精度就会下降。因此,在车端有限的算力条件下,BEV 方案通常难以实现远距离感知和高分辨率特征的平衡;
无法直接完成图像域的2D感知任务:BEV 空间可以看作是压缩了高度信息的3D空间,这使得BEV范式的方法难以直接完成2D相关的任务,如标志牌和红绿灯检测等,感知系统中仍然要保留图像域的感知模型;
实际上,我们感兴趣的目标(如动态目标和车道线)在空间中的分布通常很稀疏,BEV范式中有大量的计算都被浪费了。因此,我们希望实现一个高性能高效率的长时序纯稀疏融合感知算法,一方面能加速2D->3D 的转换效率,另外一方面在图像空间直接捕获目标跨摄像头的关联关系更加容易,因为在2D->BEV的环节不可避免存在大量信息丢失,地平线提出了Sparse4D及其进化版本Sparse4D v2,从Query构建方式、特征采样方式、特征融合方式、时序融合方式等多个方面提升了模型的效果。
性能精度指标
模型信息 | 定点精度 | J6E性能 | ||||||
|---|---|---|---|---|---|---|---|---|
模型 | 数据集 | Input shape | backbone | num_anchor | NDS | mAP | FPS | Latency |
SparseBevOE | Nuscenes | 6x3x256x704 | HENET | 384 | 0.5424/0.53 | 0.4040 | 62 | 13.28ms |
公版模型介绍
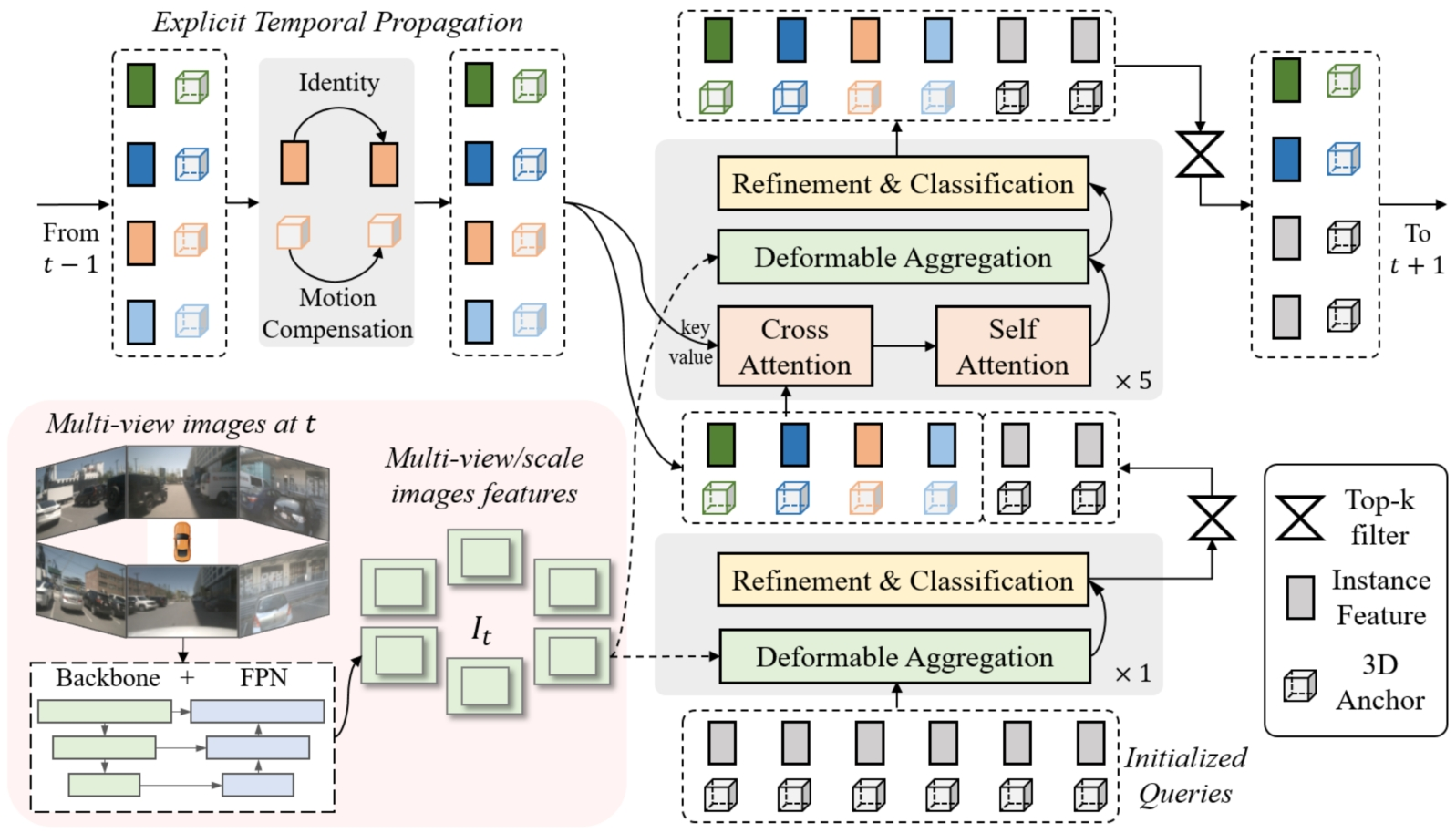
学习2D检测领域DETR改进的经验,我们也重新引入了Anchor的使用,并将待感知的目标定义为instance,每个instance主要由两个部分构成:
Instance feature :目标的高维特征,在decoder 中不断由来自于图像特征的采样特征所更新;
3D Anchor :目标结构化的状态信息,比如3D检测中的目标3D框(x, y, z, w, l, h, yaw, vx, vy);公版通过kmeans 算法来对anchor 的中心点分布进行初始化;同时,在网络中会基于一个MLP网络来对anchor的结构化状态进行高维空间映射得到 Anchor Embed ? ,并与instance feature 相融合。
基于以上定义,通过初始化一系列instance,经过每一层decoder都会对instance 进行调整,包括instance feature的更新,和anchor的refine。基于每个instance 最终预测的bounding box。
地平线部署说明
公版sparse4d在J6上部署的改动点为:
resnet50替换为henet。
num_anchor和num_temp_instances降低。num_abchor 900num_anchor和num_temp_instances降低。num_abchor 900num_anchor和num_temp_instances降低。num_abchor 900num_anchor和num_temp_instances降低。num_abchor 900-->384;num_temp_instances 600384;num_temp_instances 600-->384;num_temp_instances 600384;num_temp_instances 600-->128。
去除instance的update
get和cache对当前帧的anchor、feature 和temp帧做融合(cat)
一阶段生成的featuremap只使用FPN的第二层(stride=16),非公版的使用4层。
DeformableFeatureAggregation中kps_generator直接使用offset(linear)生成,非公版的基于anchor生成。
RefinementModule对速度没有做refine计算,公版使用了。
下面将部署优化对应的改动点以及量化配置依次说明。
性能优化
改动点1:
backbone换为henet
改动点2
一阶段生成的featuremap只使用FPN的1层(公版使用4层),通过实验验证level_index=2(stride=16)时精度和性能平衡的更好。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/head.py
改动点3:
DeformableFeatureAggregation中kps_generator直接使用offset(linear)生成,非公版的基于anchor生成。(公版的方式会导致延迟增加)。
改动点4:
RefinementModule的velocity没有refine。经过实验公版的vx的refine对精度影响较小,基于性能考虑去除该操作。
改动点5:
InstanceBankOE模块:
num_anchor数量降低(900num_anchor数量降低(900num_anchor数量降低(900num_anchor数量降低(900-->384),num_temp_instances数量降低(600384),num_temp_instances数量降低(600384),num_temp_instances数量降低(600384),num_temp_instances数量降低(600-->128)
update:取消原instance_bank的update
精度优化
浮点精度
改动点1
get中对当前帧的anchor和instance_feature融合temp_anchor 和temp_feature(num_temp=128)
改动点2
cache时,仍使用topk(k=128)获取当前帧高得分的instance作为下一帧的输入
新增融合上一帧的cache(memory_cache),最后返回num_memory个instance作为当前帧最终的Cache。cache=memory_cache+cache
cache_instance部分v1、v2均不量化!
量化精度
为量化精度保证,我们将以下的算子配置为int16或int32输出:
temp_interaction、interaction操作中对输出的instance_featuremap使用固定scale的int16量化
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/head.py
注:fix_Scale不同的数据集数据范围不同,需要根据私有数据集的数据范围固定,scale计算方式为:输入最大值的绝对值(比最大值稍大保证可覆盖)除以int16 或int8最大值
获取instance的anchor时,对anchor的量化以及结合时序anchor的cat算子使用int16保障精度:
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/memory_bank.py
KeyPointsGenerator:key_points的生成中对offset、keypoints_add做int16量化。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/det3d_blocks.py
RefinementModule:对中间的add层和输出层做int16和int32的输出(注意cache不能int32输出,还需输入给下一帧)
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/det3d_blocks.py
DeformableFeatureAggregation:对point做固定scale和int16量化。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/blocks.py
注:fix_Scale不同的数据集数据范围不同,需要根据私有数据集的数据范围固定,scale计算方式为:输入最大值的绝对值(比最大值稍大保证可覆盖)除以int16 或int8最大值
总结与建议
部署建议:
可以使用单层feature来做特征提取,根据精度和性能表现选择某层stride特征。
根据实际情况配置anchor数,对anchor个数做合理裁剪,在精度影响较小的前提下提升性能。
适当减轻模型,例如降低self_attn和cross_attn 输入维度,减少embedding_dim、num_points、decoder layer、num_head数量,选择对浮点精度影响较小的性能最优的配置组合。
对points相关的计算(anchor_projection、project_points、key_points计算)建议开启int16和手动固定scale的方式。
使用精度debug工具、敏感度分析工具来降低量化损失。
若追求更高的性能,可以使用地平线征程6的高效backbone-henet。训练策略上对backbone单独配置较大的学习率
本文通过对SparseBevOE在地平线征程6上量化部署的优化,使得模型在该计算方案上得到latency为13ms的部署性能,同时,通过SparseBevOE的部署经验,可以推广到其他模型部署优化,例如包含使用稀疏BEV的模型部署。
附录
论文:https://arxiv.org/abs/2311.11722
公版代码:https://link.zhihu.com/?target=https%3A//github.com/linxuewu/Sparse4D
课程:https://www.shenlanxueyuan.com/open/course/210
知乎专栏:https://zhuanlan.zhihu.com/p/637096473


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
