
1. 引言
2. BEVPoolV2算子
BEVPoolv2是 BEVPoolv1的优化版本,其优化了图像特征到 BEV特征的转换过程,实现了在计算和存储方面极大的降低。本章首先说明BEVPoolv2 相对于BEVPoolV2的优化点,然后剖析BEVPoolV2源码。
2.1 先说说BEVPoolv1
BEVPoolv2是 BEVPoolv1的优化版本,其优化了图像特征到 BEV特征的转换过程,实现了在计算和存储方面极大的降低。BEVPoolv1 (左)和 BEVPoolv2(右) 的示意图如下:
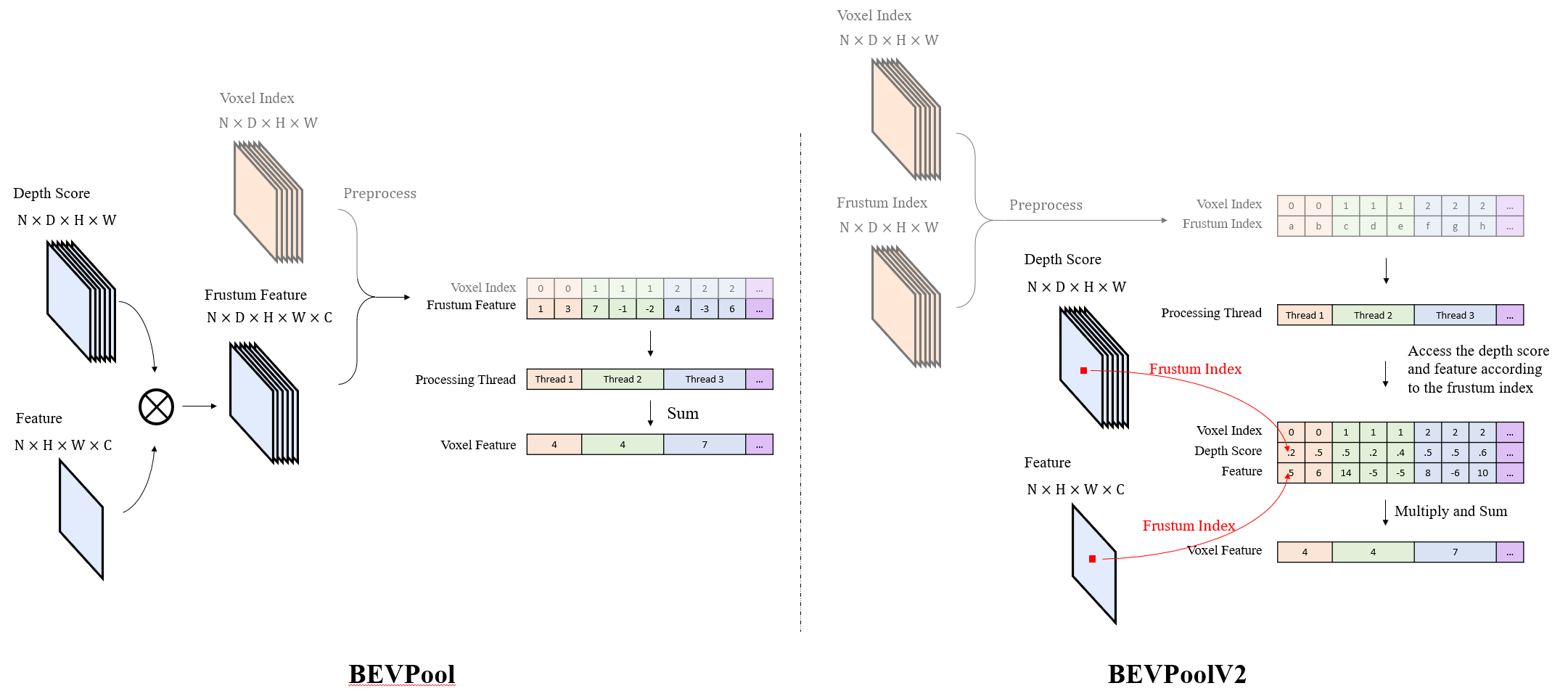
BEVPoolv1的主要计算流程如下:
首先将视锥点云特征reshape成MxC,其中M=BxNxDxHxW。
然后将get_geometry()输出的空间点云转换到体素坐标下,得到对应的体素坐标。并通过范围参数过滤掉无用的点。
将体素坐标展平(voxel index),reshape成一维的向量,然后对体素坐标中B、X、Y、Z的位置索引编码,然后对位置进行argsort,这样就把属于相同BEV pillar的体素放在相邻位置,得到点云在体素中的索引。
- 然后是一个神奇的操作,对每个体素中的点云特征进行sumpooling,代码中使用了cumsum_trick,巧妙地运用前缀和以及上述argsort的索引。输出是去重之后的Voxel特征,BxCxZxXxY。
最后使用unbind将Z维度切片,然后cat到C的维度上。代码中Z维度为1,实际效果就是去掉了Z维度,输出为BxCxXxY的BEV 特征图。
BEVPoolV1 方法具有计算效率相对较高以及融合效果良好的优点,但其缺点也较为明显,即需要对大尺度的视锥体特征进行显式计算、存储及预处理,该视锥体的尺度为(N,D,H,W,C),其中 N 表示相机数量,D 代表深度,H 和 W 分别为特征的高和宽,C 则是特征的通道数。在处理高分辨率图像时,计算量会大幅增加,从而导致推理速度受到限制。
2.2 BEVPoolv2
2.2.1 实现思路及性能
BEVPoolv2的思路如上图右侧所示,其避免了显式计算、存储和预处理视锥体特征,通过离线计算视锥索引和体素索引的对应关系表,在推理过程中固定使用该表,直接根据视锥索引找到对应的图像特征和深度特征进行计算,大大降低了显存占用,并加快了处理速度。其思路可以总结为以下步骤:
离线进行预计算和预处理:体素索引和视锥体索引;
输入深度分数、图像特征;
通过视锥体索引,找到对应深度分数和特征;
相同体素内的视锥体点通过累积求和进行聚合。
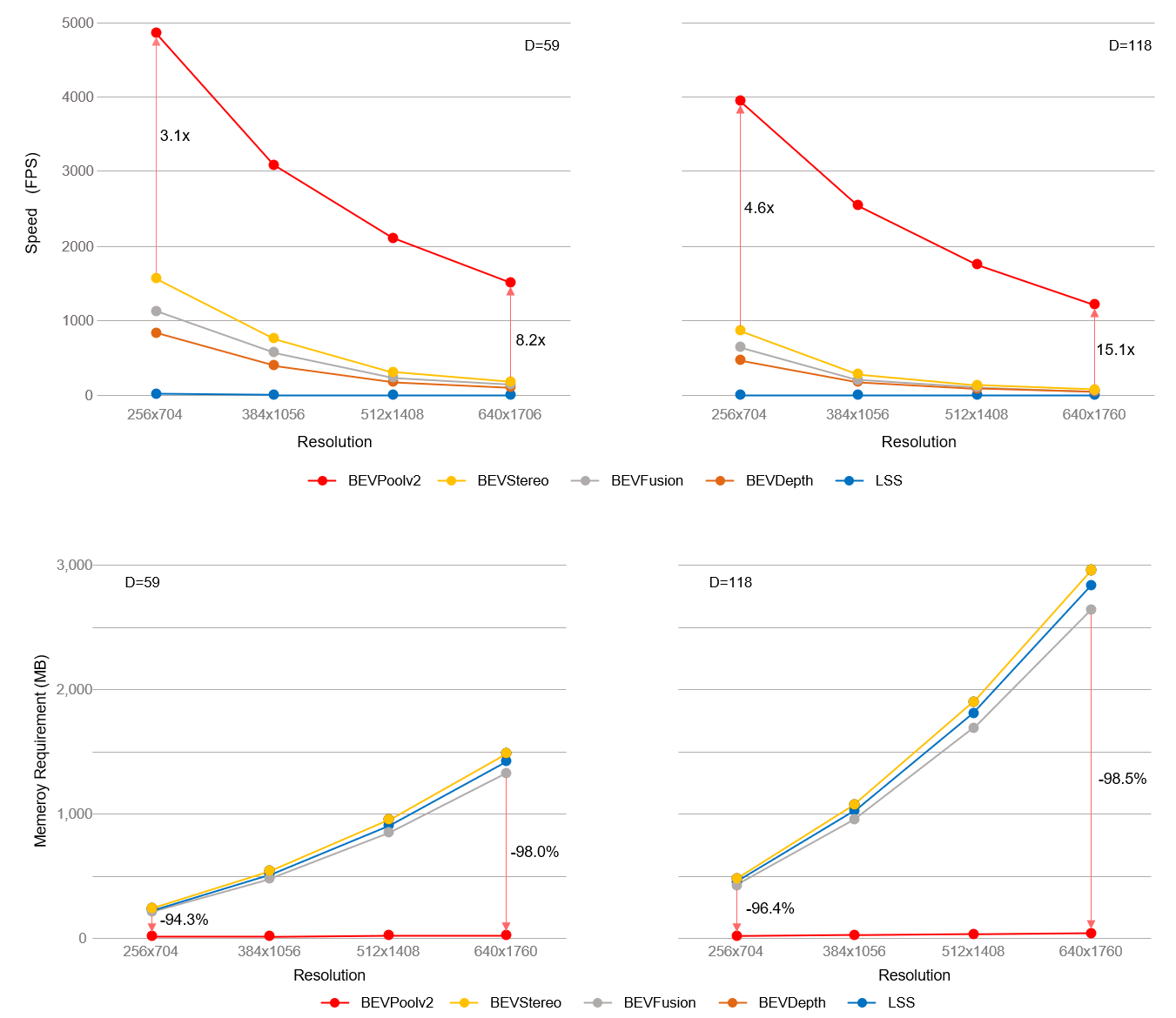
从下图可以看出,BEVPoolv2在 TensorRT的推理速度是Lift Splat Shoot(BEVPoolv1)之前最快实现的15.1倍(depth=118),同时,BEVPoolv2也大大减少了内存消耗。
2.2.2 实现代码解析
首先根据 depth 数值,构建单个相机的视锥空间
可以这样形象地去理解:有 DxHxW 个格子,每个格子都有三个元素,分别用来存放这个视锥格子对应的像素坐标 (u, v) 以及它和像平面的距离。
预计算体素索引和视锥体索引
计算每个相机图像对应的视锥在lidar坐标系中的位置
step1:
通过图像增强补偿,去掉视锥点云在图像预处理中因旋转和平移引入的变换,使其回归到未经增强的状态。
step2:
step3:
将点云坐标应用 Bird's-eye view 的数据增强变换。这一步通常用于生成增强后的 BEV(鸟瞰视图)表示,以便进行进一步的目标检测或场景分割。
计算索引关系
- 将输入的视锥空间坐标 coor 转换为体素(voxel)空间坐标。
生成每个点在深度维度(depth)、特征维度(feature)和 BEV中的索引。
对体素内点进行排序并划分为连续的区间(interval),为后续基于体素的操作(如 pooling)做准备。
step1:深度索引
step2:特征索引
step3:体素离散化
- grid_lower_bound 是栅格的最小边界。
- grid_interval 是体素的间隔大小。
结果是将连续的点云位置转换为体素空间的坐标。
step4:扩展 batch 信息
step5:筛选有效体素
step6:生成 BEV 索引
公式分解:
- coor[:, 3]:批次索引的偏移。
- coor[:, 2]:深度索引的偏移。
- coor[:, 1] 和 coor[:, 0]:平面索引的偏移。
step7:排序
将属于同一体素的点排序,使其在张量中相邻。
step8:找到区间起点和长度
- interval_starts:每个体素中第一个点的索引。
- interval_lengths:每个体素中点的数量。
返回值
- ranks_bev : 一维tensor,数量与有效的视锥数量一致,每个元素存放bev空间中voxel 的索引值;包含多段连续重复元素,注意:并不是所有voxel都被视锥栅格击中,会有大量的空voxel(fbocc作者统计将近50%,所以只有被击中的voxel 的index会留在这里)
- ranks_depth: 一维tensor,数量与有效的视锥数量一致,每个元素存放depth score的索引值
- ranks_feat: 一维tensor,数量与有效的视锥数量一致,每个元素存放context feat的索引值
- interval_starts: 一维tensor,数量与voxel的数量一致,每个元素标识着ranks_bev feat的每段"连续片段"的起点
- interval_lengths:一维tensor,数量与voxel的数量一致,每个元素标识着ranks_bev feat的每段"连续片段"的长度
voxel_pooling计算
- 前向传播:
- bev_pool_v2_kernel:实现pooling 的核心操作。将 3D 空间中的深度和特征映射到 BEV 表示中。
- bev_pool_v2:封装了内核的调用,提供方便的接口。
- 反向传播:
- bev_pool_grad_kernel:计算pooling 操作的梯度,包括对深度图和特征图的梯度。
- bev_pool_v2_grad:封装内核调用,用于梯度计算。
- 优化特性:
使用 CUDA 内核并行计算,充分利用 GPU 的计算能力。
- 通过索引 (ranks_*) 和区间信息 (interval_starts, interval_lengths) 高效定位需要处理的数据。
参考链接
BEVPoolv2论文:https://arxiv.org/abs/2211.17111
mmdet3d实现代码:https://github.com/HuangJunJie2017/BEVDet/blob/6fd935a084d403d097d5e2f18a45568e11bf3dc0/mmdet3d/ops/bev_pool_v2/bev_pool.py#L95
https://zhuanlan.zhihu.com/p/557613388
https://zhuanlan.zhihu.com/p/675738148


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)