
在我们深入探索产品及相关技术应用的过程中,大家针对诸多关键环节产生了一系列疑问。针对这些疑问我们经过收集与系统整理,将高频问题及精准解答汇总呈现,该FAQ旨在为您扫清知识障碍,助力您高效使用产品或技术。另外,我们会根据用户的反馈情况持续进行FAQ的整理和迭代并分期分享给用户。当你遇到困难,不妨来此查找看看,也是这里有与你“志同道合”的伙伴。
1. 开发环境
- Q:hrt_model_exec工具板端运行提示缺少xxx库怎么解决?
A:该种情况一般是用户环境问题或用户没有对编译后的工具目录整体打包造成的,为避免该种问题,需要用户注意一下几个Checkpoints:docker环境已经为用户配置好了编译环境,hrt_model_exec工具的编译工作在docker容器中进行。
J6目前是通过动态链接进行的工具链编译,运行过程需要依赖其他的动态库。工具编译完成后将编译输出目录script整体打包(命令tar zcvf hrt_model_exec.tar.gz script供参考)后上传板端,而不是仅仅是编译后的二进制文件。
板端使用的BSP版本满足工具链配套版本约束。
如果通过环境变量(临时的export或修改/etc/profile)配置PATH和LD_LIBRARY_PATH配置使hrt_model_exec工具不限目录可用,务必保证配置目录的正确性。
- **Q**: 在拿到硬件开发板之前,是否有测试工具在x86 ubuntu系统下查看onnx模型中的算子被的j6支持情况? **A**:导出ONNX模型后直接仿照/open_explorer/samples/ai_toolchain/horizon_model_convert_sample/03_classification/01_mobilenetv1/01_check.sh做检查就好,需要注意的是:要在docker环境下测试。
2. 模型转换
2.1 PTQ
- Q:【J3】【v1.16.2c】在模型编译配置的yaml中,使用下面的配置欲使用精度debug工具时产生错误:


A: 问题的原因应该是open_explorer_v1.16.2c这个版本中还没有引入精度debbuger工具呢,所以配置不支持. 建议先将工具链的版本升级到最新的版本后再使用精度debbuger工具。
- **Q**:【J3】【OE-1.16.6】run_on_bpu配置失效(v1.16.2c上这么设置是生效的):算子节点用run_on_bpu后发现转模型依然在cpu上! **A**:该问题系有工具链BUG所致,会在新的版本发布时修复,可通过升级工具链版本解决。在可升级之前,可通过 [补丁包](https://pan.baidu.com/s/1Mc_vE2TkzsjVC2evPzgMWQ?pwd=1ytn)临时修复.
- **Q**:【J5】BPU是单核128TOPS算力,还是双核一共提供128TOPS算力? **A**:单J5芯片拥有两个BPU核,两个核心共同提供128TOPS的算力。
- **Q**:【J5】128TOPS INT8算力,能不能近似理解成64TOPS INT16算力,32TOPS INT32算力? **A**:不能这么认为,int8是硬件计算位宽,不能做等效理解。目前只是部分算子支持了int16,另外也不是说两个int8加起来就是int16这么简单计算的,int8是个系统性的工程,是不能折算成大位宽这么计算的。就像是在32位的CPU上跑64位的系统一样,是没法处理的。
- **Q**:【J5】是否支持算子GridSample? **A**:目前j5支持的onnx opset为10/11, 而grid_sample是opset16中的算子,所以目前无法对原生的onnx的grid_sample进行支持。然而,在当前比较流行的transformer模型中grid_sample又被广泛使用,地平线针对此种情况引入了地平线特有的grid_sample进行支持,从参数上与onnx的grid_sample保持一致,具体信息可以参考:地平线开发者社区 (horizon.cc)
- **Q**:【J6】hbtl_call_quant_qcast\hbtl_call_quant_dcast的作用,怎么删? **A**:hbtl_call_quant_qcast和hbtl_call_quant_dcast分别对应的是Quantize和Dequantize,也就是量化和反量化节点。你可以通过在yaml文件的model_parameters配置节中通过配置:remove_node_type: Quantize; Dequantize;来移除他们。
- **Q**:【J6】J6全系支持TF32、fp16、fp8和int8等格式,还是仅部分产品支持? **A**:目前J6E和J6M上是支持FP16,init8和部分算子int16的, 暂时没有收集到其他型号设备的支持信息,更多信息请持续关注工具链版本发布情况。
- **Q**:【J6】是否支持 int16/int32计算? **A**: 大部分算子默认使用int8计算,部分算子支持int16、fp16计算,支持范围持续扩充中。更多信息请持续关注工具链版本发布情况。另外: + 若模型中的 BPU 部分以 Conv 结尾,则该算子默认为 int32 高精度输出; + DSP 硬件也具备 int8/int16/float32 的计算能力。
- **Q**:【J6】模型输入为batchn,PTQ转换失败该如何处理? **A**: 由于PTQ方案batchn Pyramid的支持方案还在设计中,因此用户暂时无法通过配置yaml文件中的相关参数直接编译出可上板推理的batchn Pyramid模型。若模型输入shape第一维不等于1,请务必将input_type_train和input_type_rt参数配置为featuremap。
- **Q**:【J6】onnx version 19 是否全部支持? **A**:onnx version19全部算子支持是目标,工具链会随版本替代不断完善,具体支持情况可以查看发布包中的支持算子列表。
- **Q**:【J6】【OE-3.0.22】参考随工具链OE3.0.22一起释放的《J6EM_OE_Pyramid_Resizer输入部署说明-v2.0.pdf》参考手册沿batch维度拆分时出现以下报错:  A:随工具链3.0.22的释放文档《J6EM_OE_Pyramid_Resizer输入部署说明-v2.0.pdf》中的参考代码存在错误,可参考如下代码完成拆分: ``` Python ...... # pyramid & resizer 节点只支持 NHWC 的输入layout,若原模型输入为NCHW则需要插入transpose input = input.insert_transpose(permutes=[0, 3, 1, 2]) # 插入前处理节点 input = input.insert_image_preprocess(mode="yuvbt601full2rgb", divisor=255, mean=[123.675, 116.28, 103.53], std=[0.01712475, 0.017507, 0.01742919]) y, uv = input.insert_image_convert("nv12") ``` - **Q**:【J6】【OE3.0.22】模型编译后使用hb_model_info查看BC模型信息报错? **A**:执行hb_model_info *.hbm 和hb_model_info *.bc时遇到错误的问题是因为工具链BUG造成的,问题会在下一版本更新时修复,为不影响用户使用,可通过以下方式临时改动代码(docker内代码文件路径:/usr/local/lib/python3.10/dist-packages/horizon_tc_ui/hbir_handle.py): 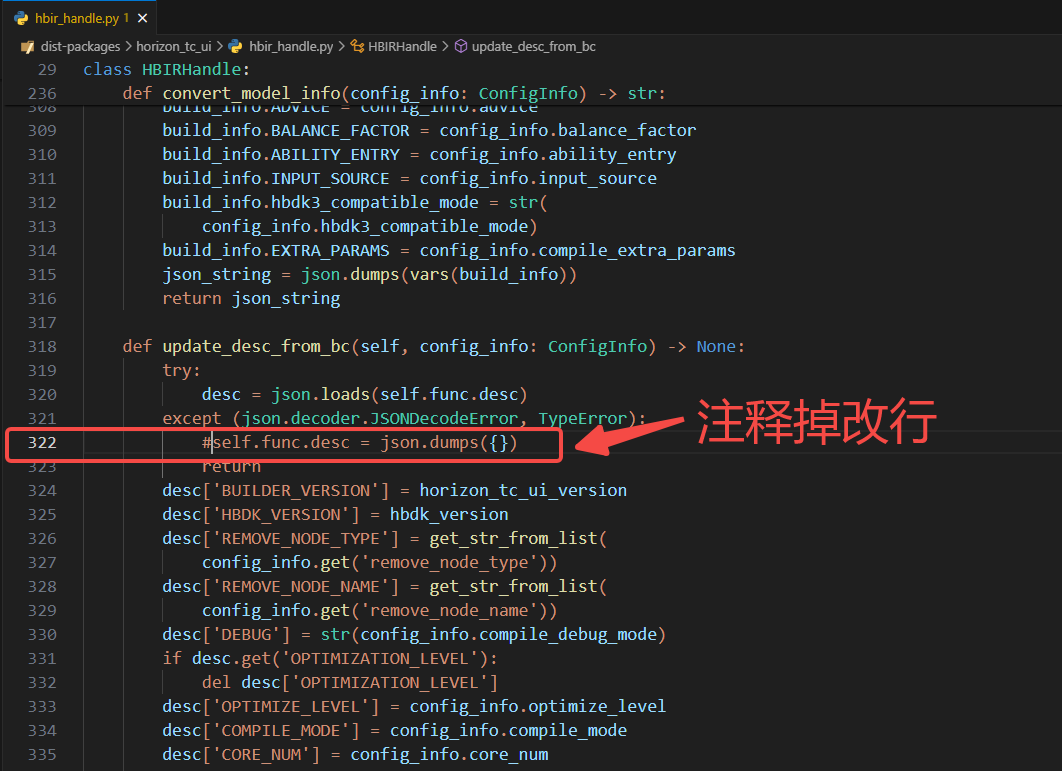
- **Q**:【J6】【OE-3.0.22】当前没有校准数据集时看不到每层算子是在CPU还是BPU上执行,这个是正常的吗? **A**:没有校准数据集目前的策略是不会进行余弦相似度计算,而每层算子都是在CPU还是BPU上执行就是在余弦相似度计算过程中输出的,因此没有校准数据集目前是不会显示计算单元的。
- **Q**:【J6】【OE-3.0.22】在OE文档“ONNX算子BPU约束列表”章节中没有列出的算子(比如pad、isNaN ScatterElements、Relu等)是目前算法工具链不支持的吗? **A**:不是的,示例所提到的算子都是支持的!有些算子在模型转换优化阶段会被折叠,所以之前做了屏蔽,为了避免类似的误解,内部已经做好同步,下次版本迭代时我们会更新将所有支持的算子列出。
- **Q**:【J6】【OE-3.0.22】J6转换模型时,LRN算子转换报错 **A**:LRN(Local Response Normalization)是目前无法支持,你可通过其他支持的算子进行等效替换后在进行转换。
2.2 QAT
- Q:QAT浮点训练后的模型执行calibration校准后精度下降,这个是正常的吗?
A:浮点模型执行calibration校准后精度下降这个是正常现象,不是问题。calibration校准会在模型中插入 Observer以及伪量化节点。对于部分模型,仅通过 Calibration 便可使精度达到要求(虽然精度没有浮点的好,到损失不大),不必进行比较耗时的量化感知训练。但是如果calibration校准后精度无法满足要求,calibration也可降低后续量化感知训练的难度,缩短后面量化训练时间,提升最终的训练精度。
3. 模型部署
- Q:【J3】官方部署示例horizon_model_convert_sample的01_mobilenet进行模型推理的前处理和horizon_runtime_sample生成板子上运行的可执行文件的前处理不一致,这个是对的吗?
A:1)前处理逻辑这个只是一个示意,主要用途是让你要考虑前处理,用户理解就OK了,具体部署时怎么进行缩放、裁剪策略,你根据自己的业务场景进行;2)目前示例中使用的图片是一张W=H的图,示例模型刚好需要的也是W=H=224的图,所以直接resize后面没啥问题,但是一旦原图变成了W不等于W了,直接使用示例代码进行推理就会出现问题,这个需要引起注意。用户可参考/open_explorer/ddk/samples/ai_benchmark/code/src/utils/image_utils.cc中的函数在工程中完成图像处理。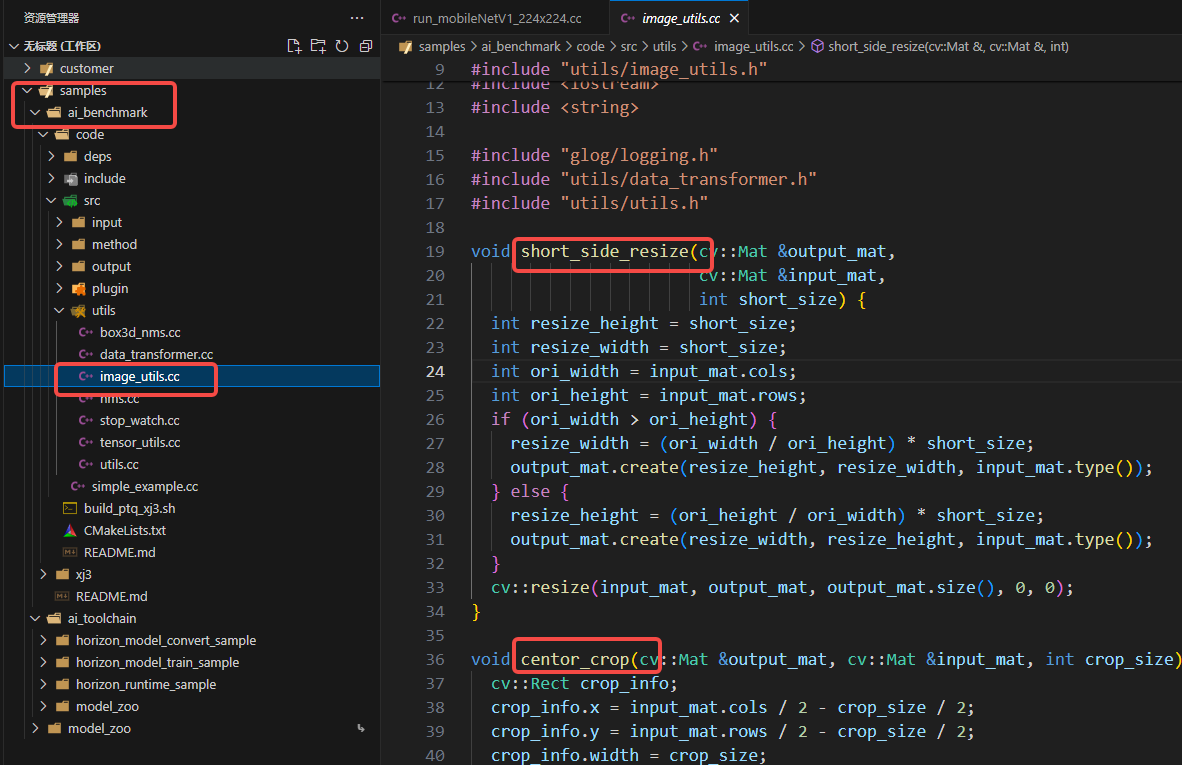
- **Q**:【J6】【OE-3.0.22】目录samples-->ucp_tutorial-->custom_operator下DSP自定义算子示例板端部署执行dsp_deploy.sh出错,错误日志:/aarch64/bin/image/vdsp_image_launch.sh: 40: echo: echo:I/0 erron **A**: 如果版本使用730系统版本确实存在该问题,系统升级到930后,问题便可解决。
- **Q**:【J6】【OE-3.0.22】执行基于DSP X86仿真的OE包自带示例/open_explorer/samples/ucp_tutorial/vp/vp_samples/script_x86/01_basic_processing/run_basic_processing.sh报错 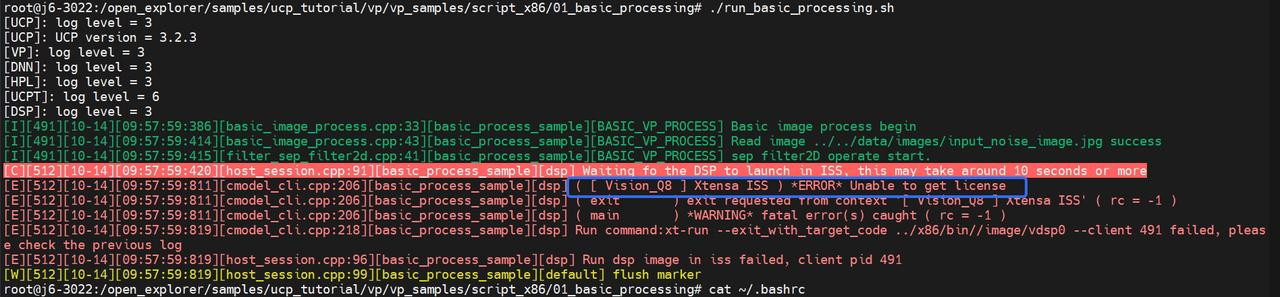 **A**:该报错可能是因为客户环境缺少 XT_ISS_TURBO License。该 License 用于仿真加速,但因为地平线并未买断,所以无法直接提供给客户,如客户需要,则需自行向 Cadence 购买。在新版本OE-3.0.27中,示例额已经替换成基于 XT_ISS_BASE_EDC90FD4 实现,示例程序可正常执行。更多信息可以参考[【问题整理】【J6-OE-3.0.22】【DSP】DSP自定义算子示例仿真测试失败。](https://developer.horizon.auto/forum/642215179972665344)
- **Q**:J6上量化编译的.hbm模型文件是否可以在J5上运行? **A**: J6和J5在架构设计上是不同的,支持的算子约束也是不一样的,所以J6上量化编译的.hbm模型文件是无法在J5上运行的
- **Q**:文档中模型的单帧耗时latency与帧率Fps 统计是如何统计的?论上不应该是帧率=1000÷(推理耗时+后处理耗时)吗,但表格中的数据和这个不对应. **A**:文档中latency反应的是单线程情况下的推理耗时,理论上应包含有模型数据的前处理、推理以及后处理逻辑等,但因为性能测试工具hrt_model_exec是统一逻辑的而不同模型的后处理逻辑又不尽相同,所以使用hrt_model_exec进行性能测试时仅表示推理latency和少量的前处理逻辑。在单帧推理中,因为前处理阶段的存在,BPU并非是始终处于满负荷推理状态。而FPS是多线程(比如8线程)情况下的数据,多线程时可以保证BPU始终处于接近满负荷推理的状态,所以FPS上的数据比较高。latency和FPS数据上有差异其实是因为框架和线程原因BPU的状态不同,这也就是我们说部署时尽量通过多线程充分利用BPU,而不是让BPU等待数据的原因。
- **Q**:在X86仿真环境中基于C++对hbm模型进行推理时,推理时间较长并一直出现以下“Wait for fifo free”的log是正正常的吗? **A**: 这个是正常的提示,不会影响的模型的执行。推理任务在调度是被分成了多个functioncall送入BPU的FIFO(先入先出队列)中等待执行,如果BPU执行时间比较长,超过了所设置的预期返回时间变回出现日志提升。在X86仿真环境中怎么没有专用的加速硬件导致functioncal的执行时间很好,但这是正常符合实际的,不会影响业务执行。
- **Q**:使用hrt_model_exec工具是需要手动指定input_valid_shape和input_stride这两个参数,请问能否设置模型输入张量为非动态输入? **A**:模型动态输入是J6为了更好的适配和支持非四维数据而引入的,无法设置为非动态输入。但是对于hrt_model_exec工具的使用,3.0.17确实需要手动配置valid_shape和stride,但是3.0.22支持内部自动验算,无需手动提供。可以升级工具链版本到3.0.22及以后版本进行使用。 # 4. 其他 - **Q**: 使用docker load -i加载docker镜像失败该如何处理? **A**: 1)判断docker镜像文件是否具有度权限;2)使用md5sum获取和判断docker镜像文件的完整性。
- **Q**:【J5】两个bpu核共用一个sram吗?作用是啥?两个bpu核可以执行不同id的推理任务吗? **A**:1)SRAM片上存储用在CPU, BPU, VDSP, CODEC, ISP等IP之间交换数据,所以两个BPU核是共用一个sram。2)两个bpu核是相互独立的可以并行执行计算。
- **Q**:J5和J6E中有稀疏网络的硬件支持能力么? **A**:目前权重稀疏在运行时是支持的,但是目前没有提供模型的网络稀疏修改工具,可以使用其他公开的稀疏化工具完成模型稀疏后尝试测试。但是收益与模型结构有关,是否可以拿到收益视模型而定。
- **Q**:【J6】请问怎么获取XXXXX版本的J6工具链开发包? **A**:获取J6工具链开发包需要在NDA签署完成后由客户通过地平线接口人申请释放。



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)