
1.模型简介
1.1关键特点
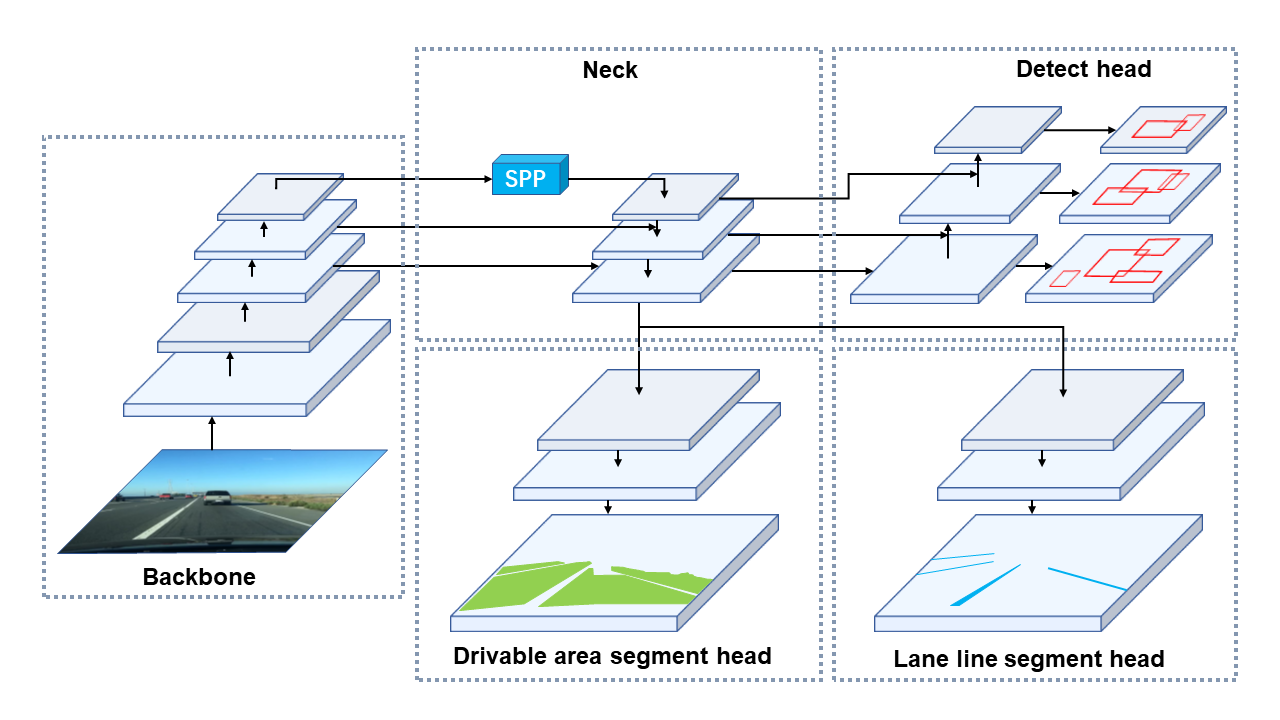
1.2模型结构
YOLOP的模型架构是基于YOLO的,具体包括:
- 主干网络(Backbone):用于提取图像的基本特征,类似于传统的YOLO模型,但进行了调整以适应多任务需求。
- 检测头(Detection Head):用于执行目标检测任务,类似于YOLO中的检测机制。
- 分割头( Segmentation Head):用于道路场景的分割任务。
- 车道线检测头( Lane Detection Head):用于检测道路中的车道线。
1.3应用场景
YOLOP主要应用于自动驾驶领域,特别是需要实时做出决策的场景。它可以帮助车辆快速感知前方道路的情况,包括识别车辆、行人等目标,同时还能识别车道线和分割路面区域,该模型具有以下优点:
- 实时性强:YOLOP模型的设计使其能够在边缘设备上以较低的延迟完成感知任务,满足自动驾驶场景的实时性要求。
- 多任务融合:通过将多个任务集成到一个模型中,YOLOP不仅提高了推理速度,还减少了部署的复杂性。
YOLOP模型的设计体现了在自动驾驶场景下的需求,即希望通过一个轻量化、高效的模型来完成多种感知任务,从而增强驾驶安全性和效率。
2.ONNX模型精度验证流程迁移
2.1导出onnx
参考repo https://github.com/hustvl/YOLOP.git 中的步骤配置环境。
2.2搭建onnx评测流程
1. 准备data_loader
参考lib/dataset/AutoDriveDataset.py中AutoDriveDataset和lib/dataset/bdd.py中BddDataset的实现,构建能够实现同样功能的数据集BDDValidLoader。
2. 推理过程逐步对齐结果
构建推理class BDDDetection完成模型的推理流程,整体推理流程参考torch的验证流程lib/core/function.py中validate函数。
加载数据集图片并进行预处理,验证BDDValidLoader加载的图片数据跟torch val_loader加载的图片数据相同。
torch推理得到的输出结果与ONNX推理引擎得到的输出结果进行对比,保证结果相同。
将torch输出后处理代码迁移到onnx评测流程中,保证后处理输出能够对齐。
3. 计算评价指标
检测任务评价指标:将lib/core/general.py中的ap_per_class迁移到onnx流程中,计算检测任务结果。
分割任务评价指标:将lib/core/evaluate.py中SegmentationMetric的实现迁移到onnx评测流程中,计算可行驶区域分割以及车道线分割指标结果。
最终得到指标与torch的计算指标基本一致,保证ONNX模型的精度跟torch评测精度对齐,至此ONNX的评测流程搭建完成。
3.校准模型精度调优
首先采用HMCT default量化,测试结果分别为det精度为0.61507(80.46%),da_seg精度为0.88863(99.84%),ll_seg精度为0.65357(100.19%),校准算法选择了percentile。
从精度结果看出,只有det分支的精度未达到99%,推断da_seg分支和ll_seg分支以及公共的backbone部分存在敏感节点的可能性较小,后续调优需重点关注det分支上的敏感节点。
3.1 INT16精度调试
3.1.1 全INT16精度
设置模型all_node_type为INT16,校准模型精度分别为det 0.75890(99.27%),da_seg 0.88950(99.93%),ll_seg 0.64821(99.37%),校准算法选择了percentile。全INT16精度能够满足要求,可以使用INT8+INT16混合精度完成调优。
3.1.2 INT8+INT16混合精度调试
通过分析模型结构设置高精度节点
根据上述量化模型精度分析可得,HMCT default量化模型只有det任务精度不满足99%,而全INT16精度测试说明使用INT16精度可以满足精度要求,因此将det分支head部分算子精度设为INT16,测试模型精度。该量化配置以Conv_559、Conv_707、Conv_855算子作为子图输入,Concat_1003作为子图输出,将子图中包含的节点配置为INT16。
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)