
假设你在玩一款游戏,你是一个在充满谜题和任务的神秘城堡中探索的冒险者。在这个城堡中,每个房间都像是视频中的一个场景,里面布满了各种物品和线索。城堡的主人提出一个任务,比如 “我需要找到某个特定的魔法宝石并将它放置在城堡的特定位置”,这时你就开始探索,完成城堡主人的任务。但你可能会发现城堡内的道路错综复杂,像在走迷宫,根本找不到宝石,更别说放到目标位置。

这时,VideoAgent 就来帮忙了!VideoAgent 利用其构建的场景记忆(就如同它在城堡中绘制的详细地图),从以自我为中心的视频和具身感官输入中收集信息,就像冒险者在房间里仔细观察每一个角落和物品一样。VideoAgent 会像一个经验丰富的向导,首先通过其记忆回想在视频中是否见过类似的宝石以及相关的位置信息,这就如同在地图上标记出可能存在宝石的房间。然后它会利用多种工具来查询记忆,如同在城堡的图书馆(记忆库)中翻阅各种古籍(数据)来获取更准确的线索。最后,VideoAgent 激活具身动作原语与环境互动,就像向导带领冒险者在城堡中穿梭、打开宝箱(执行操作)等,直到成功找到宝石并放置在指定位置,有效地满足用户的请求,帮助用户完成在这个神秘城堡中的任务。以上过程涉及到动态 3D 场景理解并与之交互。动态 3D 场景理解对通用具身 AI 发展至关重要,但现有方法存在局限。如多数采用的端到端预训练多模态大模型处理长视频和具身感官观察能力受质疑,计算成本也可能过高,难以在机器人等边缘设备部署。主要挑战包括从冗长的以自我为中心的视频和其他具身感官输入中理解环境;处理因主体和其他角色动作产生的动态环境;维护可随时间更新的场景持久记忆。本期具身智能之心介绍的这篇文章提出了 Embodied VideoAgent,用于解决从以自我为中心的观察中理解动态 3D 场景的问题,在机器人和具身 AI 领域具有重要意义。
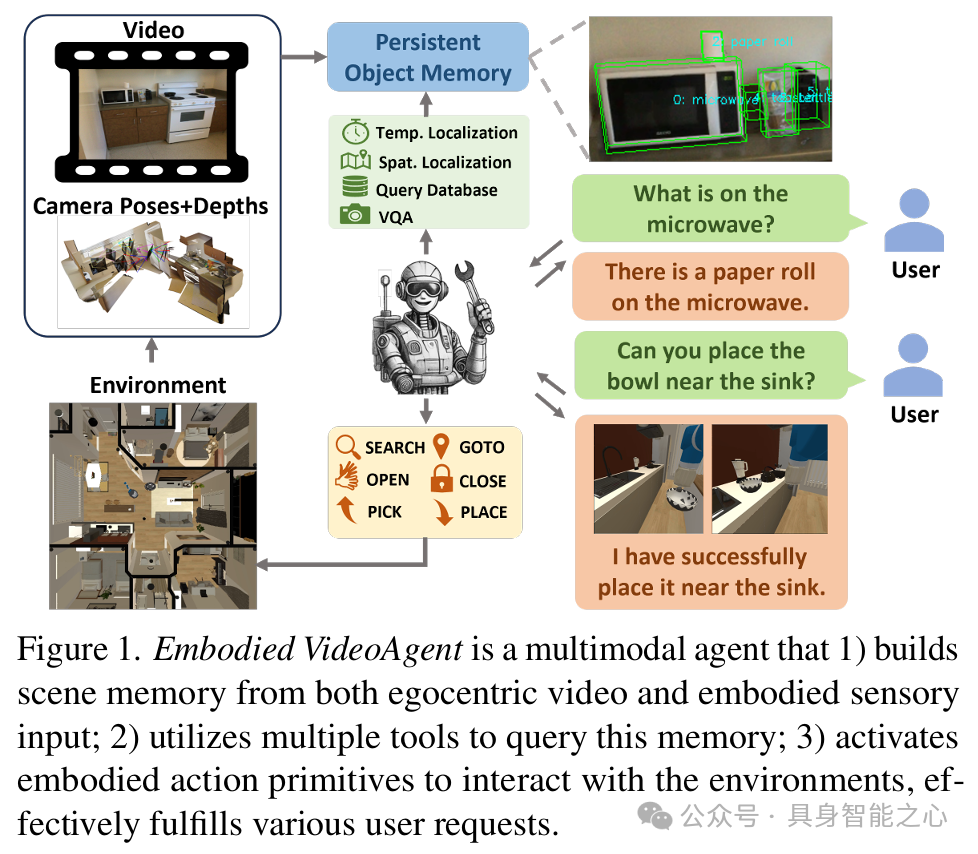
图 1 展示了 Embodied VideoAgent 作为一个多模态智能体的工作流程,它能够从以自我为中心的视频和具身传感器输入构建场景记忆,利用多种工具查询记忆,并激活具身动作原语与环境互动,从而有效满足用户的各种请求。
模型架构
VideoAgent处理流程为将视频切片后构建时间记忆和对象记忆,通过 LLM 分解任务并调用工具模型查询记忆,最后汇总结果生成最终答案。时间记忆是包含视频段信息的表格,对象记忆包括 SQL 数据库和特征表。
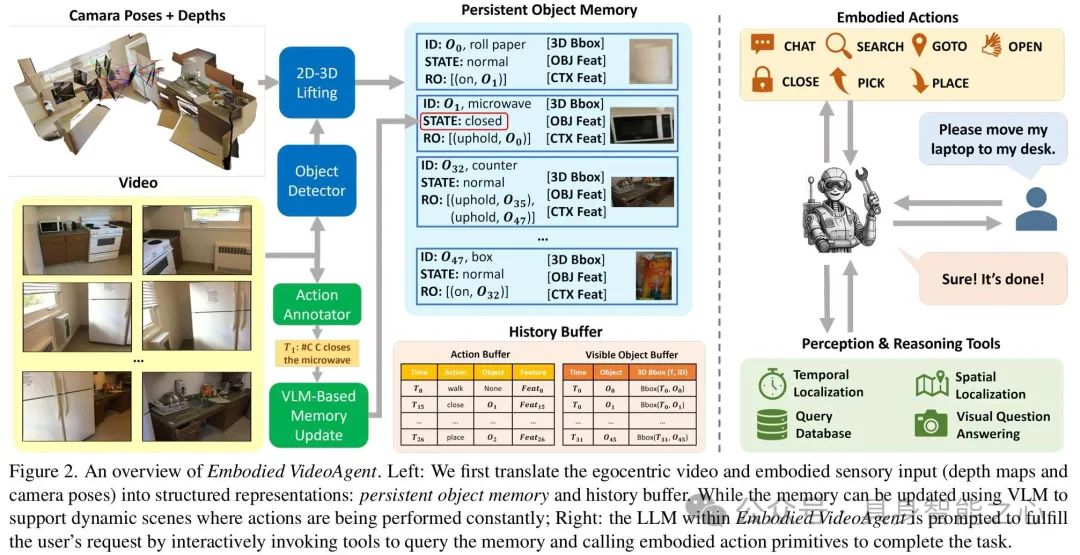
图 2展示了 Embodied VideoAgent 的整体架构,包括将自我中心视频和具身感官输入转换为持久对象记忆和历史缓冲区,以及通过 LLM 调用工具查询记忆和执行具身动作原语来完成用户请求。持久对象记忆(M_{0}):为 3D 场景中每个感知对象维护一个条目,包含对象标识符、状态、相关对象及关系、3D 边界框、视觉特征和环境上下文特征等字段。通过 YOLOworld 检测对象并结合深度图和相机位姿构建,利用 2D - 3D 提升获取 3D 边界框,还进行对象重识别以避免重复条目,重识别后用移动平均更新相关字段。

图 3:可视化了持久对象记忆中条目的情况,每个 3D 边界框对应一个记忆条目,随着视频推进,对象可被跟踪和重新识别,其记忆条目也会更新。基于 VLM 的记忆更新:利用动作信息和视觉语言模型(VLMs)解决对象操作时的记忆更新问题。当动作发生时,检索相关对象条目,通过在帧上渲染 3D 边界框并提示 VLM 确定目标对象,然后更新对象状态等字段。
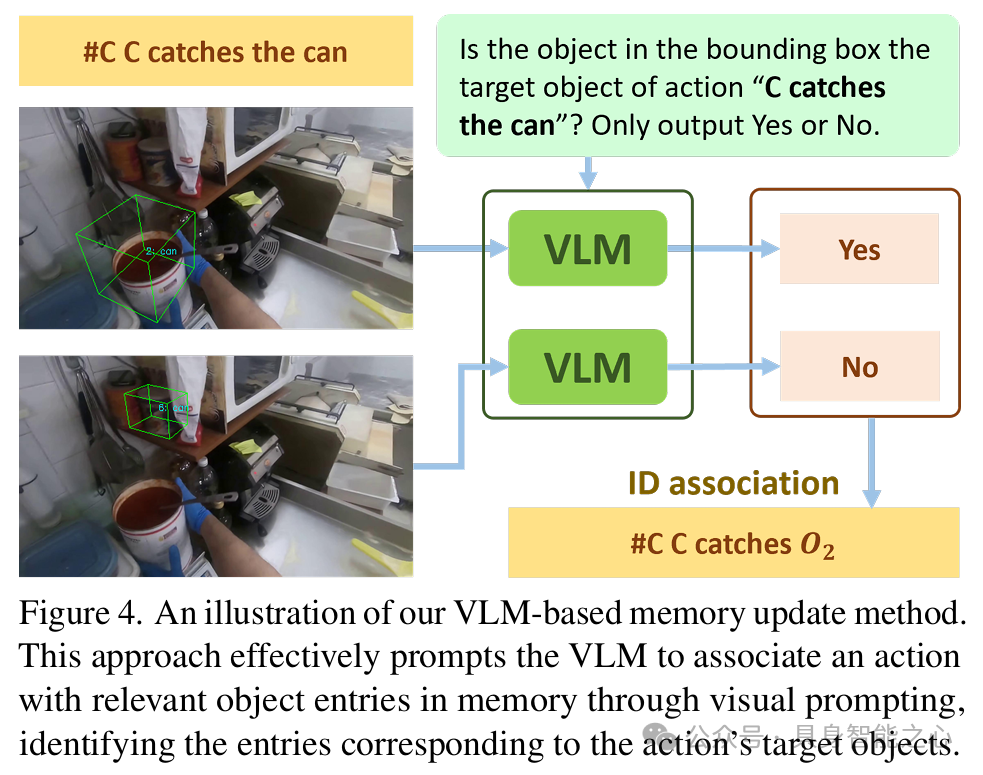
图 4:说明了基于 VLM 的记忆更新方法,通过视觉提示使 VLM 将动作与记忆中的相关对象条目关联,识别动作目标对象并更新相应条目。历史缓冲区:包括动作缓冲区和可见对象缓冲区,分别记录动作和检测到的对象信息,供工具参考。工具和具身动作原语:配备 query_db、temporal_loc、spatial_loc、vqa 四种工具和 chat、search、goto、open、close、pick、place 七种具身动作原语。生成具身交互的双智能体框架:利用一个 LLM 模拟用户,Embodied VideoAgent 作为助手,在具身环境中交互,用户基于有限场景图知识提出任务,助手探索环境完成任务并反馈。
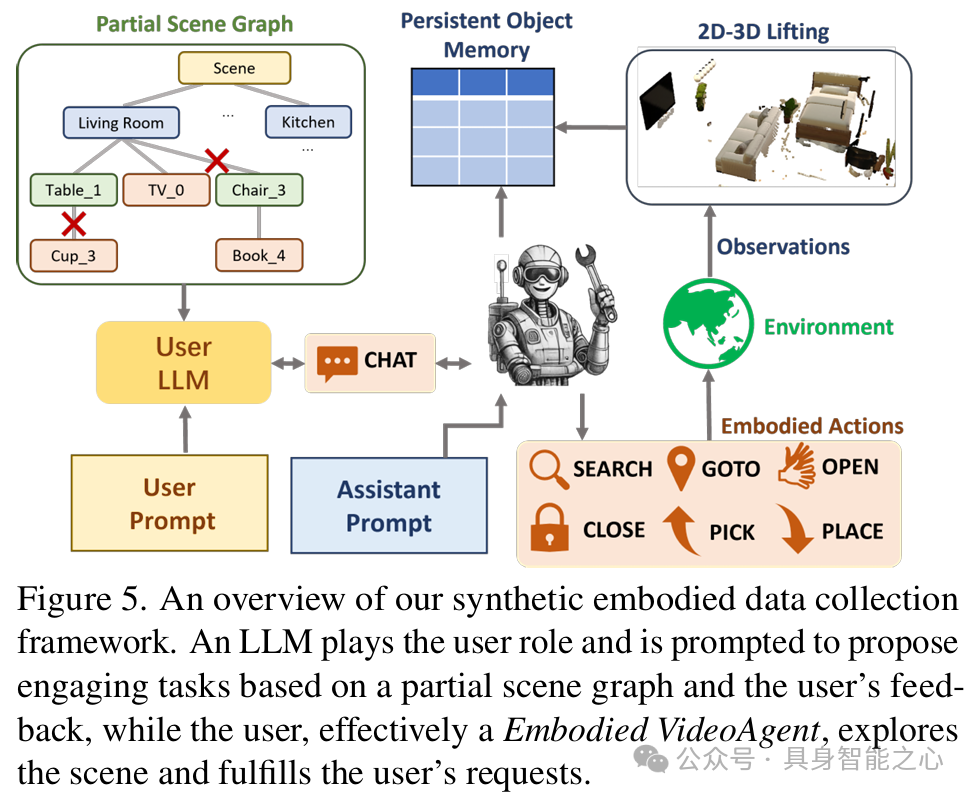
图 5:呈现了合成具身数据收集框架的概述,一个 LLM 扮演用户提出任务,Embodied VideoAgent 作为助手探索场景完成任务,用户基于部分场景图知识和反馈提出任务。
实验
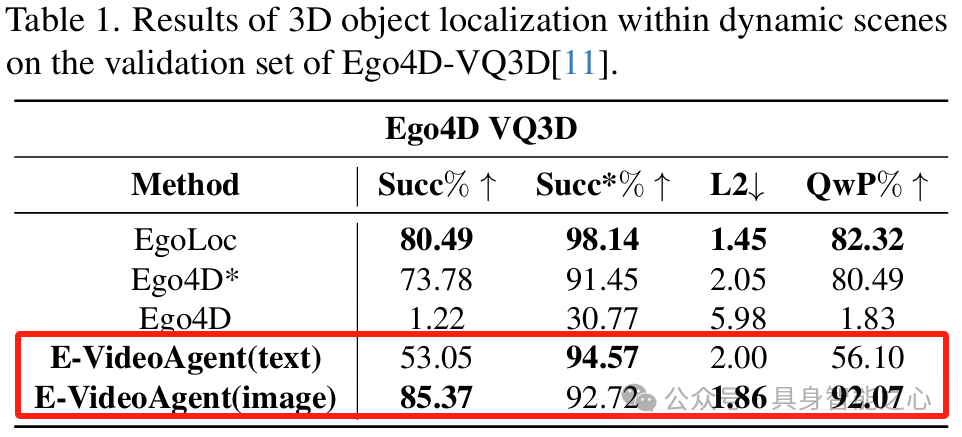
3D 对象定位(Ego4D - VQ3D):测试了两种 Embodied VideoAgent 变体,与其他方法对比。结果显示 Embodied VideoAgent(image)成功率最高,原因是开放词汇对象检测器提供更多候选对象,且视觉相似性对动态场景中的对象重识别至关重要。
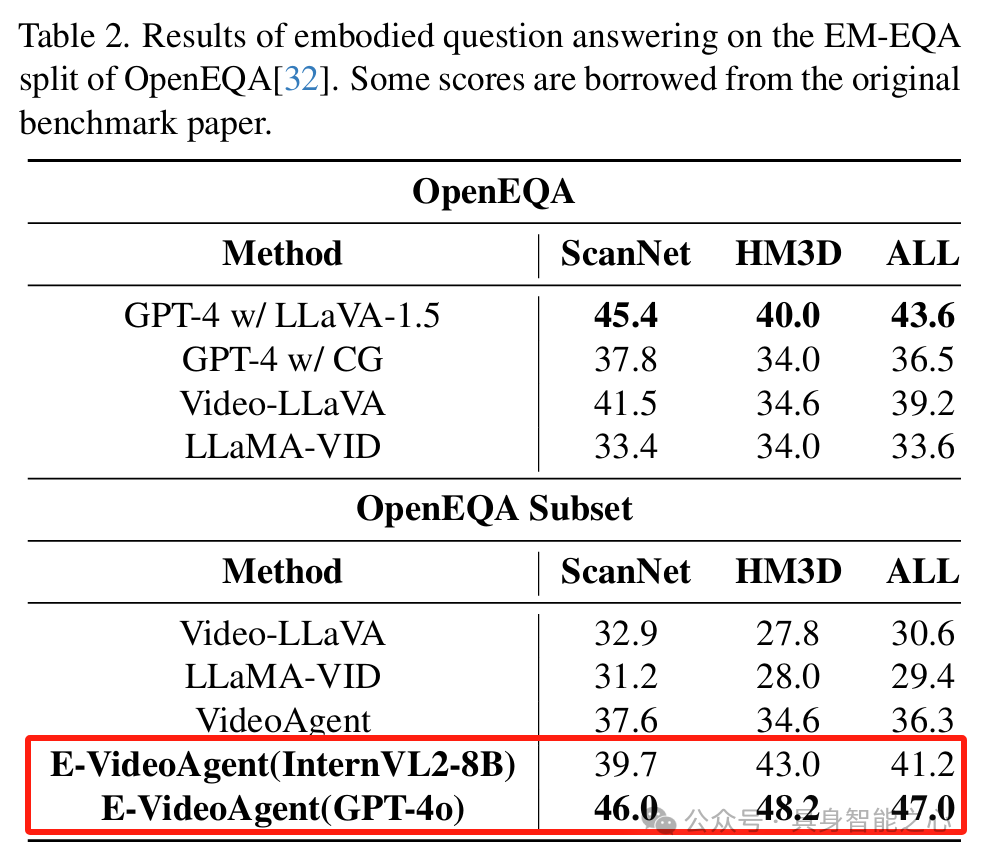
具身问答(OpenEQA 和 EnvQA):OpenEQA:在子集上测试,Embodied VideoAgent 的两个变体表现良好,优于部分基线方法。其优势在于时间定位 + vqa 工具比场景图更能有效解决具身问题,且代理系统优于端到端 VLM,精确的帧定位和全面的对象记忆有助于提高答题准确性。
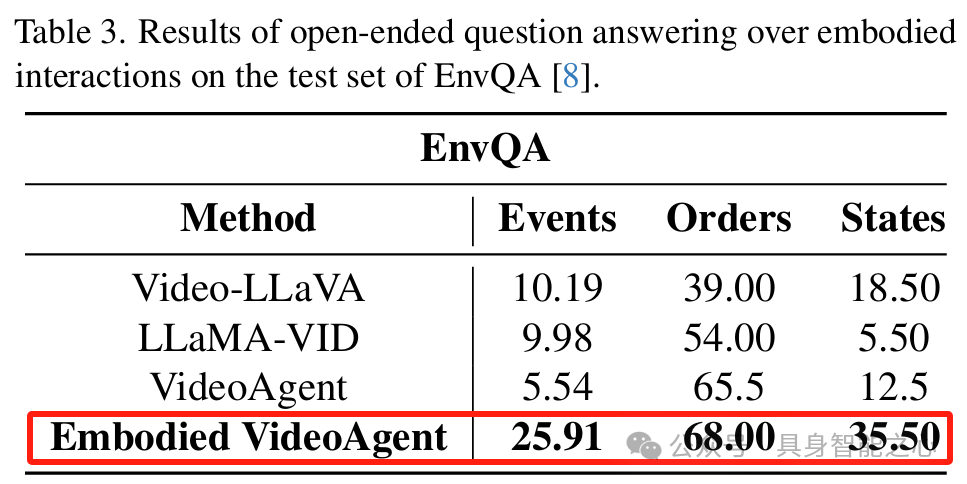
EnvQA:相比其他方法有显著性能提升。基于 VLM 的记忆更新有助于事件理解,对象关系检测有助于解决状态问题。
在具身 AI 任务中的更多应用:展示了在用户 - 助手交互和机器人感知任务中的应用,在交互任务中能准确理解场景对象并完成任务,在机器人感知任务中可在动态场景中成功完成物体抓取任务。
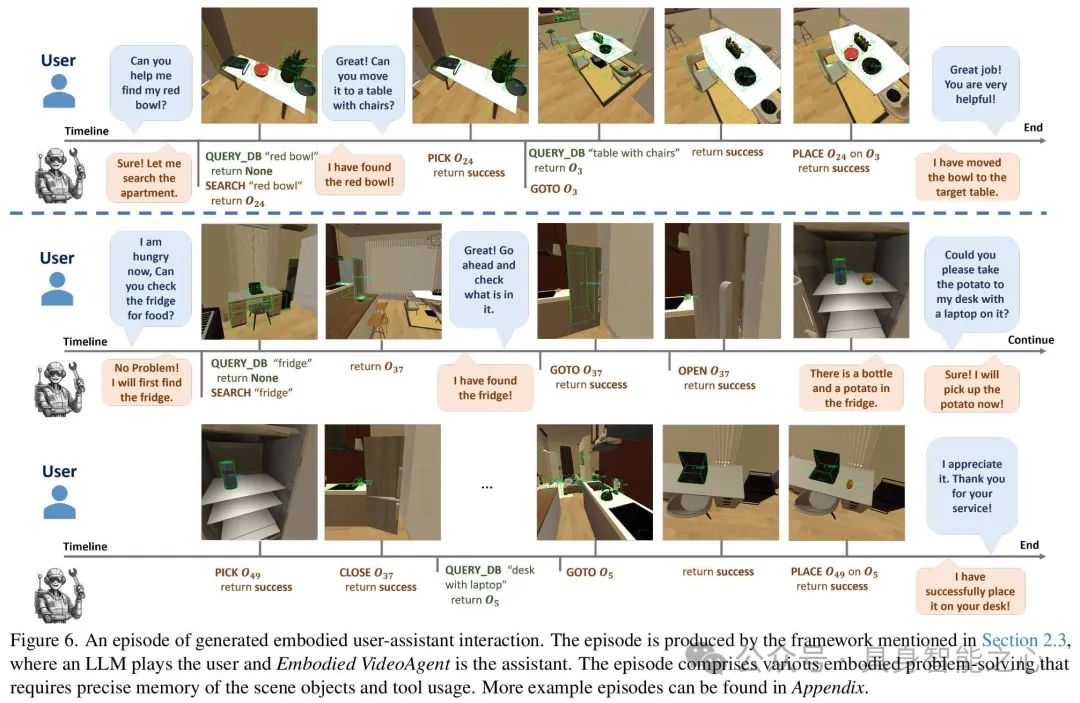
图 6:展示了一个由双智能体框架生成的具身用户 - 助手交互示例,包含各种需要精确场景对象记忆和工具使用的问题解决过程,体现了 Embodied VideoAgent 的功能。

图 7:表明持久对象记忆在机器人实际操作中的有效性,机器人利用该记忆在动态操作场景中成功完成抓取苹果的任务,即使苹果被遮挡也能找回其位置。
相关工作
视频和动态场景理解:现有 3D 场景理解方法在动态场景处理上存在不足,动态场景理解因视频能捕捉动态变化而受关注,但面临任务复杂和计算需求高等问题。用于感知的多模态智能体:利用 LLMs 分解感知任务,由工具模型完成子任务后汇总结果。在多种感知任务中表现有前景,但在动态场景理解等复杂任务中面临挑战。
总结与展望
提出持久对象记忆和基于 VLM 的自动记忆更新方法,构建并维护动态 3D 场景的精确记忆。开发基于 LLM 的多智能体框架,产生具身用户 - 助手交互。通过实验验证了 Embodied VideoAgent 在多种具身场景理解任务中的有效性。未来可将机器人部署在更具挑战性的环境中。Embodied VideoAgent: Persistent Memory from Egocentric Videos and Embodied Sensors Enables Dynamic Scene Understanding
https://arxiv.org/pdf/2501.00358
https://arxiv.org/pdf/2501.00358
文章第一作者Yue Fan,个人主页:https://yuefan1014.github.io/。文章第一作者Yue Fan,目前是北京通用人工智能研究院的研究工程师。研究兴趣包括具身人工智能、视频理解和机器人技术,之前从事过生物信息学和图表示学习,业余时间对量化交易也感兴趣。其他成果:与 Xiaojian Ma 等人共同发表《VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding》(ECCV 2024),构建了能理解长视频且性能接近 Gemini 1.5 Pro 的 VideoAgent,正在构建实时 VideoAgent。与 Jun Guo 等人发表《Semantic Gaussians: Open-Vocabulary Scene Understanding with 3D Gaussian Splatting》(arxiv 2024),使用高斯溅射重建 3D 场景并保留语义信息。与 Tianxu Wang 等人发表《Attention Based Models for Cell Type Classification on Single-Cell RNA-Seq Data》(ECAI 2023),构建了两种基于注意力的模型来预测细胞类型,该论文被评为 AI 在社会公益方面的优秀论文。与 Xiuli Ma 发表《Multi-vector embedding on networks with taxonomies》(IJCAI 2022),构建了一种在双曲空间中自适应学习每个节点多个表示向量的新图嵌入方法。与 Xiuli Ma 发表《Gene regulatory network inference using 3D convolutional neural network》(AAAI 2021),构建了一个 3D 卷积神经网络作为良好的基因调控网络预测器。与 Junshan Wang 等人发表《Tag2vec: Learning tag representations in tag networks》(WWW 2019),Tag2Vec 学习了双曲空间中节点及其标签的嵌入。
文章转载自公众号:具身智能之心
作者: Yue Fan原文链接:https://mp.weixin.qq.com/s/ondfUzvavRxQ9Xe3dWzktg

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)