
在我们深入探索产品及相关技术应用的过程中,大家针对诸多关键环节产生了一系列疑问。针对这些疑问我们经过收集与系统整理,将高频问题及精准解答汇总呈现,该FAQ旨在为您扫清知识障碍,助力您高效使用产品或技术。另外,我们会根据用户的反馈情况持续进行FAQ的整理和迭代并分期分享给用户。当你遇到困难,不妨来此查找看看,也是这里有与你“志同道合”的伙伴。
1. 开发环境
- Q:J5 镜像拉取失败或中途自动停止导致下载包不可用怎么解决?
A:1. docker pull 是从服务器上拉取,目前OE工具链没有上传到外网docker服务器,所以 docker pull 拉取 镜像的方式是不可以的.- 通过网页或命令的方式下载J5 镜像后通过docker load -i xxxx 将镜像加载到docker中,然后 执行docker run -it xx构建容器就可以使用可,如果存在问题,请检查 镜像的完整性。
- 通过docker images查看一下目前镜像的情况,如果load的镜像在 docker images 的列表中经证明OK了,就可以使用 docker run -it 构建contianer和使用了,记得-v映射一下OE包哈,另外最好在 docker run 中加入 --privileged=true
- 目前论坛的套件下载功能存在一些问题,正在修复。如果在本论坛中下载工具链套件失败,可以临时用此链接下载。
- **Q**:j6_OE包下载不了,怎样才能下载? **A**:获取J6工具链开发包需要在NDA签署完成后由客户通过地平线接口人申请释放。
# 2. 模型转换 ## **2.1 PTQ** - **Q**:J6 PTQ量化怎么指定gpu id? **A**:hb_compile在calibration阶段会尝试使用GPU执行模型的forward推理, 推理过程使用的就是onnxruntime的 InferenceSession, 所以推理规程如果要用到GPU,也是通过 onnxruntime的 InferenceSession 进行设置的。所以: 1. 从常规onnx执行的过程看,可以通过设置环境变量 CUDA_VISIBLE_DEVICES设置 InferenceSession推理时所用的gpu id。 2. 如果1确实尝试过了不行,那你可以通过修改一下工具链的脚本文件(/usr/local/lib/python3.10/dist-packages/hmct/executor/ort2.py)进行设置和测试,修改的文件和方式如下: 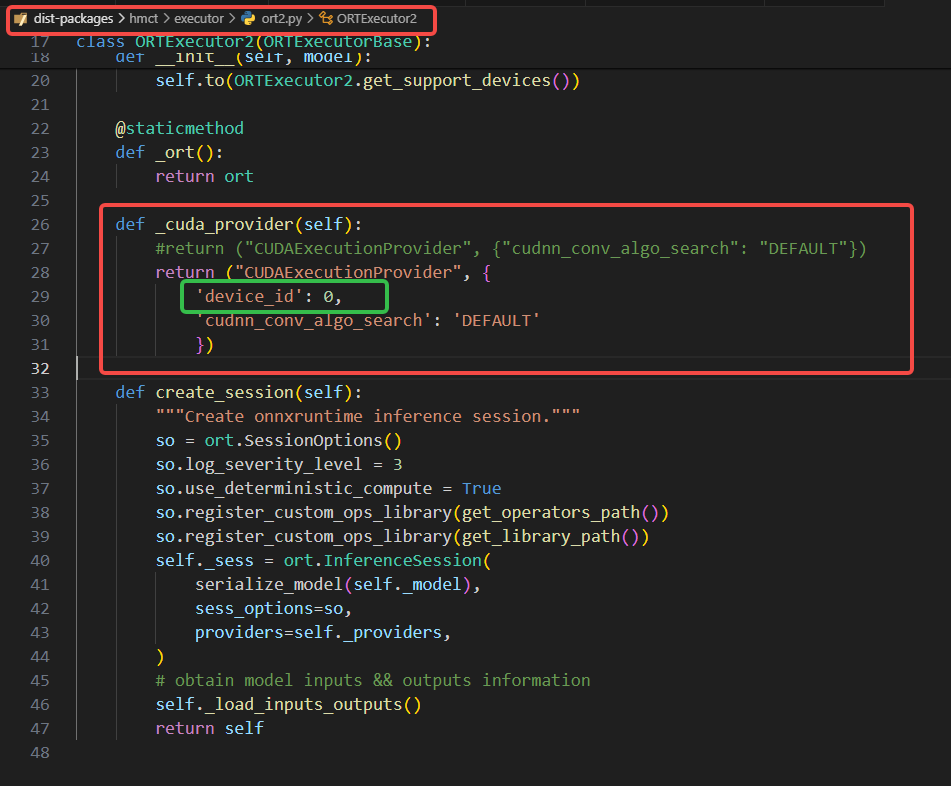
- **Q**:transformer模型适合做PTQ吗? **A**:对于 QAT和PTQ 两种量化,不同模型的量化友好性是不同的,不能一概而论的,但整体来说, QAT是相对精度更有保障,必须要说明的是,Transformer类型的模型既可以使用PTQ,也可以使用QAT(量化感知训练),具体取决于多种因素: - 数据方面: 如果没有足够的带标签数据用于进一步训练,因为PTQ仅执行小型统计数据收集来确定量化参数,无需带标签的数据,所以PTQ更合适 - 精度方面: 通常情况下,PTQ可能会导致一定的精度下降,虽然一些改进的方法可以提升精度,但总体上在复杂的Transformer模型上可能仍不如QAT。 - 模型规模和计算资源方面: PTQ不需要重新训练模型,在计算资源和时间消耗上相对QAT较少,对部署时间比较急迫情况下PTQ更有优势,而QAT需要进行重新训练,计算成本和算法复杂性较高,需要计算资源和时间也更多。 - 量化难度方面:Transformer模型中Softmax、GELU等特殊函数激活值分布复杂,传统PTQ方法通过量化参数变得困难,可能导致较大量化误差。
- **Q**:模型量化过程,如何指定输出结果的数据类型? **A**: 1). 原始onnx模型的输出是什么类型的,工具链默认会将量化后模型的输出对齐到 原始模型。 2) . 如果原始就是 S64,而你希望是S8的,同时后处理也能很好适配,请检查一下S64的具体来源吧,如果输出的尾部存在CAST节点将S8等转成了S64,那么通过配置文件的 remove_node_type:Cast项可以将CAST移除。
- **Q**:使用hb_verifer验证两个模型的一致性时存在量化warning: Different shape, skip this tensor calculation。 **A**:问题原因是参与对比的两个模型的同名输出shape不一致所致。对于参与对比的两个模型,同名输出结果对比时: 1. 两个模型中name和name + "_quantized"可以认为是同名。 2. 对于同名输出如果一个模型的输出是[1, sub_shape],另一个模型是[n, sub_shape]的情况,对比之前会先进行数据扩展 [1, sub_shape] ->[n, sub_shape] ,然后再进行对比。 3. 对于同名输出如果存在layout不一致的情况,工具会先进行layout的变换在进行比较,工具是支持的。
- **Q**:【J3】量化配置中通过input_type_rt配置项将nv12转换为yuv444,转换后OE-1.16.6比OE-1.16.2精度好。 **A**:不同配置下对校准数据的处理策略存在差异,下图是对不同版本工具链的对比. 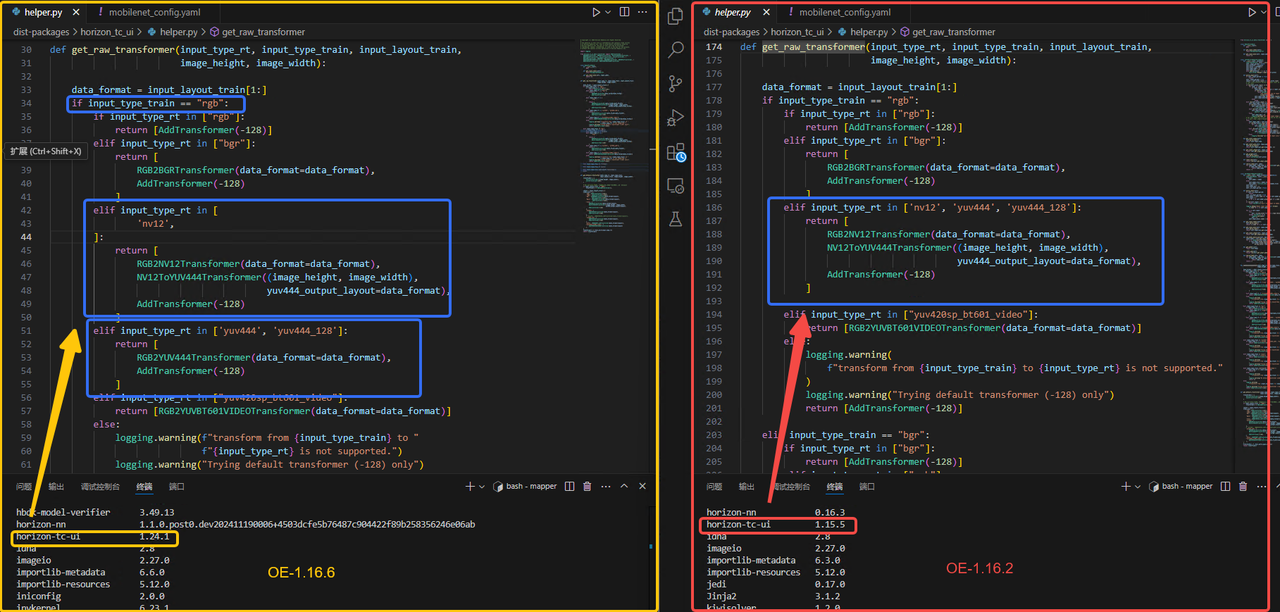
- **Q**:解释`hb_mapper checker`阶段各生成文件的作用,bin文件是否可以直接用来推理? **A**:`hb_mapper checker`的设计目的为快速检查用户模型在地平线平台的支持情况,其本质是对模型进行了一次编译,所以`checker`过程生成的过程文件与编译工程生成的过程文件类型和作用是一样的,文件作用和类型可以参考用户手册之编译结果解读部分;`checker`过程生成的模型是可以推理的, 但是因为`checker`过程主要目的是检测模型的支持情况,该过程没有校准数据集的参与,精度是完全没有保障的。
- **Q**:PTQ常见问题中"tensor不能为全0,0是非法阈值"的原因是什么? **A**:校准过程统计计算得到的阈值最终是为了计算量化参数scale值,而量化`scale=阈值 /(qmax-qmin)`,得到的scale是推理量化时: `qx = clamp(round(x / scale) + zero_point, -128, 127)`。如果 阈值 为0就会导致除数为0。
- **Q**:DOCKER容器中,执行`build` 和 `cmake`后生成的可执行文件无法运行如何处理? **A**:1)DOCKER 是在服务器端(X86)的服务器,生成的X86指令集的程序是可以运行的和执行推理任务的,推理使用的是仿真环境;2)如果生成的是arm程序,在x86端是无法运行的,可以部署到板端运行。
- **Q**:J6中,PTQ 非fast模式怎么配置可以强制让算子运行在bpu上? **A**:不用特别的指定,BPU支持的算子,工具链会优先选择通过BPU支持的;对于临输出尾部算子,考虑高精度输出,链路可能会提前反量化后将一些算子运行在CPU上,对于这种如果确实需要跑回到BPU的,可以在量化配置中的node_config中配置中指定类型为int8/int16,如下 ```JSON "node_config": { // 配置某个节点的输入数据类型 "node_name1": {"qtype": "int8"/"int16"} } ``` 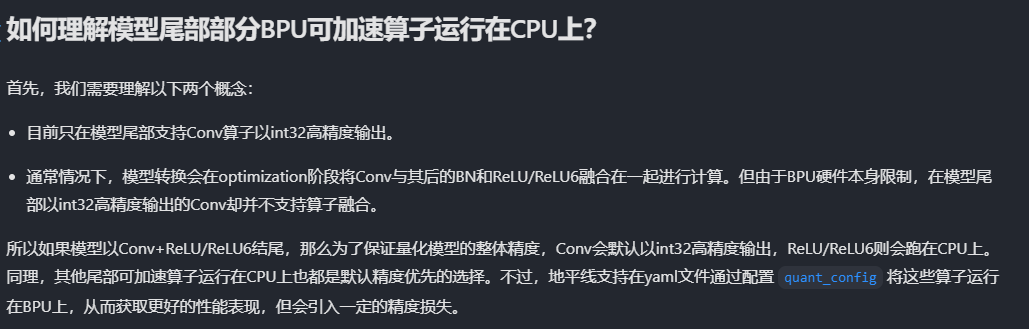 - **Q**:模型推理不慢,但是PTQ量化和编译过程比较慢,这个怎么理解? **A**:1. 校准过程和推理过程是不一样的,推理只是forward计算,校准要先尝试不同的策略过滤和统计收集数据,收集完了还要有不同策略计算scale这些。另外除了这个模型,模型也要压缩优化这些。 2. 编译过程也类似,编译是一个动态规划的过程,需要大量的遍历动作,随模型规模的增加,编译速度影响很大,至少不是线性的。 3. 不管如何,校准过程都和服务器的CPU,GPU,MEG有关,如果CPU/GPU的速度足够快,这个过程就能缩短。
- **Q**:J6M中对于多batch RGB图片输入的模型,如何设置输入nv12进行量化? **A**:1) nv12输入源是Pyramid,目前PTQ⽅案batchn Pyramid的⽀持⽅案还在设计中,暂时⽆法通过配置yaml⽂件中的相关 参数直接编译出可上板推理的batchn Pyramid模型。若要在PTQ⽅案下依然希望部署时每个batch的数据可以来源于不同的内存地址,可先使⽤ `hb_compile`⼯具⽣成 `*ptq_model.onnx` 之后通过如下代码将模型输⼊沿batch维度拆开,并插⼊ 前处理节点和格式转换节点: ``` Python import onnx from hbdk4.compiler.onnx import export from hbdk4.compiler import convert, compile, visualize, save model_path = "mobilenetv1_224x224_nv12_ptq_model.onnx" onnx_model = onnx.load(model_path) model = export(onnx_model)
func = model.functions[0]
func.input[0].insert_split(dim=0)
func.input[0].insert_split(dim=0)
为拆分后的每个输⼊节点插⼊pyramid节点和前处理节点
for input in func.inputs[::-1]:
# pyramid & resizer 节点只⽀持 NHWC 的输⼊layout,若原模型输⼊为NCHW则需要插⼊transpose
node = input.insert_transpose(permutes=[0, 3, 1, 2])
# 插⼊前处理节点
node = node.insert_image_preprocess(mode="yuvbt601full2rgb", divisor=255, mean=[123.675, 116.28, 103.53], std=[0.01712475, 0.017507, 0.01742919])
node.insert_image_convert("nv12")
# pyramid & resizer 节点只⽀持 NHWC 的输⼊layout,若原模型输⼊为NCHW则需要插⼊transpose
node = input.insert_transpose(permutes=[0, 3, 1, 2])
# 插⼊前处理节点
node = node.insert_image_preprocess(mode="yuvbt601full2rgb", divisor=255, mean=[123.675, 116.28, 103.53], std=[0.01712475, 0.017507, 0.01742919])
node.insert_image_convert("nv12")
quantized_model = convert(model, march="nash-m")
save(quantized_model, "mobilenetv1_224x224_nv12_quantized.bc")
save(quantized_model, "mobilenetv1_224x224_nv12_quantized.bc")
- Q:为什么会出现伪量化模型和板端部署的定点模型精度不一致?
A:定点模型 QBC 和伪量化模型 FBC 之间无法做到完全数值一致。 如果他们存在一定的误差,可以尝试更多数据进行训练,另外,如果 QBC是OK的,HBM存在问题,有可能是编译问题。
# 3. 模型部署 - **Q**:J5中,ptq之后得到的.bin文件,如何在板端加载模型进行推理,该去看那些实例代码? **A**:得到.bin文件后,需要使用工具链的的libdnn部署C++编程接口进行C++编码完成模型的部署。 - 文档可以参考用户手册中的  - 代码可以参考:`/open_explorer/ddk/samples/ai_toolchain/horizon_runtime_sample/code/00_quick_start`
- **Q**:hbm模型推理输出结果的类型类型是什么,量化后的结果还是保持f32吗? **A**:1. hbm模型的输入输出相关信息通过`hrt_model_exec model_info --model_file model`就可以看具体输入输出的个数,shape以及数据类型等信息,这些信息可以为模型的输入准备,输出处理提供依据。 2. 影响模型输入输出类型的配置是由模型转换过程决定的,PTQ流程中配置项 `remove_node_type` 以及QAT过程脚本`scripts/tools/compile_perf_hbir.py`中的 `remove_quant_dequant` 都会对hbm模型的输入输出产生影响。
- **Q**:J6E 直接执行vp算子示例会运行失败? **A**:常见原因:未把DSP的image通过 `dsp_deploy.sh` 脚本 load上。问题修复参考代码[链接](https://pan.baidu.com/s/1wJjDEXhAHvk13G_GXSrPjQ?pwd=nkap):
- **Q**:如何用dsp把一张正常彩色图做旋转呢? **A**:dsp对图像进行旋转,实际上是对图像进行仿射变换,在工具链里面,DSP提供了 Warp Affine 方法。可以对图像进行旋转。 另外,帖子[【J6】VP简介与单算子实操](https://developer.horizon.auto/blog/12886)中提供了图像旋转的示例程序,可供参考。
- **Q**:从pym拿到虚拟和物理的y地址和uv地址,必须拷贝到src_mem的addr里才可以用么? **A**:不需要,参考[链接](https://pan.baidu.com/s/1yicG8Z0R63gvH6ehoJ0LOA?pwd=xzga).
- **Q**:基于J6 DSP执行int8->fp32的反量化中,从分析图中看到`DSPPluginTask::Wait`时间很长是怎么理解? **A**:调度逻辑:
- 用户界面:`SubmitTask` -> `wait` -> `ReleaseTask` - UCP框架调度:`SubmitOp` -> `OpInfer` -> `OpFinish` -> `TaskSetDone` 需要注意的是,DSP调用并不总是有收益,尤其在数据处理量小的情况下,RPC机制的调度开销可能会大于实际计算的收益,导致负收益。#
# 4. 其他 - **Q**:怎么查看板子上cpu到bpu之间的吞吐量? **A**:CPU和BPU是两个分开的计算器件,CPU准备好数据给给BPU使用,BPU反馈计算结果给CPU处理,就是这样,如果因要看内存占用的话,可以参考[内存占用与监控方式介绍](https://developer.horizon.auto/blog/12887),如果要看bpu使用带宽,可以使用hrut_ddr -t bpu查看
- **Q**:J6E可以查看某个进程的bpu占用率吗? **A**:J6E上的BPU占用率并不能直接按进程进行统计。如果在某段时间内只有一个进程在执行推理任务,那么统计到的BPU使用率就等于该进程的占用率。可通过这种方法单进程地统计BPU占用率,进而绘制相关的曲线图。
- **Q**:非对称量化方法中关于zeropoint的具体作用是什么? **A**:**作用:** zeropoint 在非对称量化方法中主要用于确定量化的基准点。它将量化区间进行合理的划分,使得量化后的数值能够更好地保留原始数据的分布特征。通过调整 zeropoint 的位置,可以使量化结果更符合数据的实际情况,减少量化误差。 **引入原因:** 实际数据的分布往往是不对称的,可能存在偏态或非均匀分布的情况。为了更准确地对这类数据进行量化,引入 zeropoint 可以根据数据的特点灵活地调整量化区间,提高量化的精度和效果。 **优劣:** 对称量化可以说是非对称量化的特例, 非对称量化适应性强, 量化结果更接近原始数据的真实分布,量化误差小。但是 非对称量化方法 计算复杂度高,另外不同的模型数据分布可能需要不同的可能需要不同的 zeropoint 设置,通用性也相对比较差。相反,对称量化简单, 通用性好,但是 相同量化位数下可能无法达到与非对称量化相同的精度。
- **Q**:在非对称量化中,权重校准是否需要校准数据?权重校准是否直接通过权重的 min 和 max 确定 thresholds? **A**:**激活校准**:需要校准数据,通过输入数据的 min 和 max 计算 scale 和 zeropoint。 **权重校准**: - 不需要校准数据,直接通过权重的 min 和 max 确定 thresholds。 - 工具链可能会将激活校准的参数转嫁到权重中,因此权重的量化参数可能受激活参数影响。 - 工具链内部会进行偏差矫正,因此 scale 可能会有微小调整。
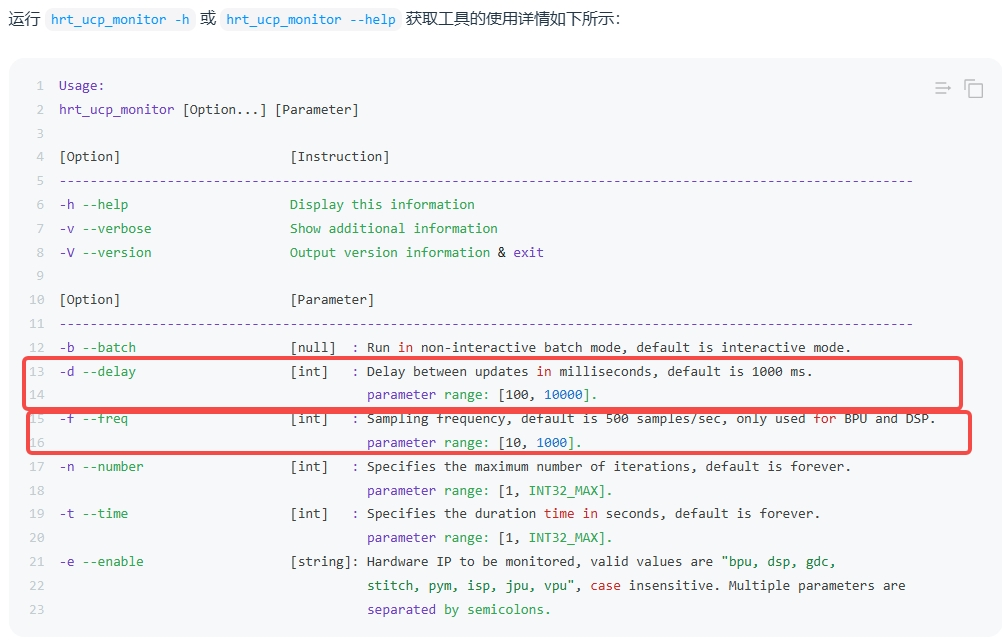
- **Q**:j6e的bpu的占用率的统计周期是多长? **A**:BPU 默认采样频率为每秒采样 1000 次,占用率统计周期默认1000 毫秒。具体在使用时可以通过工具链提供的 hrt_ucp_monitor 工具 灵活设置。
- Q:hrut_ddr 这个工具怎么装?在板端装吗?
A:这个工具属于底软工具的一部分,不需要特殊安装,刷完系统,底软自带的。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)