
 论文:https://arxiv.org/abs/2501.14729
论文:https://arxiv.org/abs/2501.14729仓库:https://github.com/LMD0311/HERMES
主页:https://lmd0311.github.io/HERMES/
背景在自动驾驶领域,世界模型(Driving World Models, DWMs)旨在预测未来场景演变、提升系统感知与决策能力,并成为近期业界的热点。然而,当前的DWM主要专注于场景生成任务,尽管能够预测环境未来的变化,却在场景理解能力上表现不足,难以全面解释驾驶环境。这种割裂使得模型在动态驾驶场景中的信息处理与预测能力大打折扣。
与此同时,视觉语言模型(Vision-Language Models, VLMs)在场景理解任务中展现了强大的潜力,能够处理复杂的视觉问答和场景描述。然而,它们缺乏对未来场景的建模能力,难以为自动驾驶系统提供前瞻性的预测。这一现状凸显出一个关键挑战:如何在单一框架内同时实现对驾驶环境的深刻理解与未来场景的精准预测?
针对这一挑战,本文提出了HERMES,一个统一驾驶世界模型。HERMES实现了场景理解与生成的一体化建模,通过将多视角场景的几何与语义信息整合到统一的表示中,同时利用世界查询机制促进了当前三维环境文本理解与未来场景生成之间的高效信息流动。HERMES的提出不仅打破了场景理解与生成任务的边界,也为世界模型的研究提供了全新的视角。
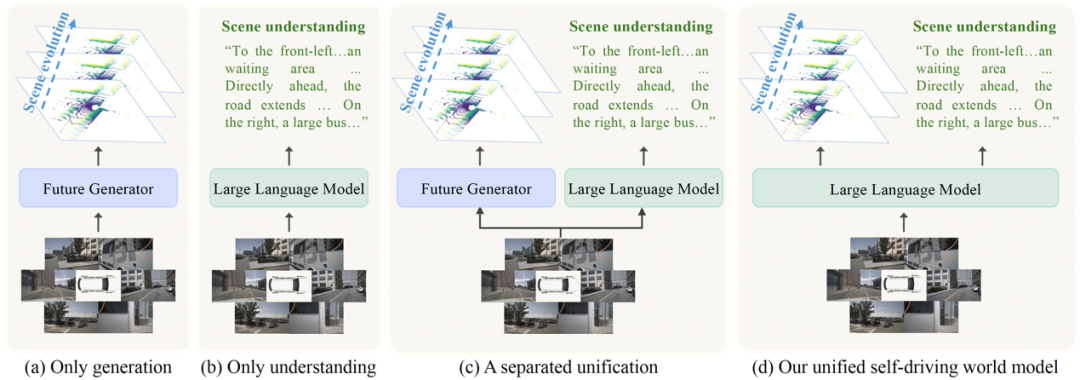
名字的来源:HERMES

1) 鸟瞰视图 (BEV) 表示
2) 世界查询 (World Queries) 机制
为实现理解与生成任务的深度结合,HERMES提出了世界查询机制,使用Flattened BEV以池化的方式初始化一系列World Queries,利用LLM的因果注意力机制,从这些queries从文本token中提取世界知识。为了将World Queries的信息注入进对应的未来帧,使用跨时间链接模块(current to the future link),将当前场景BEV特征与未来场景特征连接,通过多个跨注意力块,捕获场景演化的时空关系,并得到一系列未来帧BEV特征()。将生成的未来BEV特征转换为点云表示,以生成未来场景。
3) 多任务联合优化
HERMES 同时优化理解与生成任务,通过以下目标函数实现两者的协同训练:
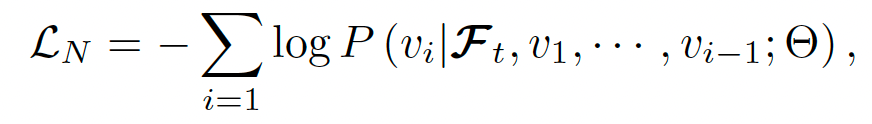 生成目标:通过监督未来点云的生成过程,同时用当前帧点云作为辅助任务,优化模型的几何生成能力。
生成目标:通过监督未来点云的生成过程,同时用当前帧点云作为辅助任务,优化模型的几何生成能力。
结果
HERMES 在多个数据集上的实验表明:
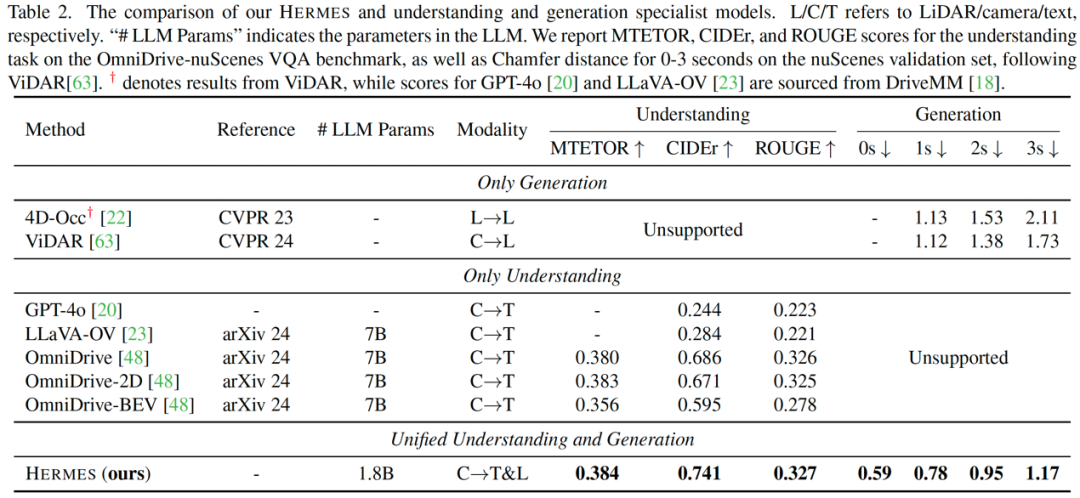
总结
HERMES 作为首个统一的3D场景理解与生成模型,通过统一的BEV表示和世界查询机制,为自动驾驶的感知与预测任务提供了强有力的工具。
文章转载自公众号:我爱计算机视觉
原文链接:https://mp.weixin.qq.com/s/7HFdXDpBXJg9l679uEtGWQ

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)