
在我们深入探索产品及相关技术应用的过程中,大家针对诸多关键环节产生了一系列疑问。针对这些疑问我们经过收集与系统整理,将高频问题及精准解答汇总呈现,该FAQ旨在为您扫清知识障碍,助力您高效使用产品或技术。另外,我们会根据用户的反馈情况持续进行FAQ的整理和迭代并分期分享给用户。当你遇到困难,不妨来此查找看看,也是这里有与你“志同道合”的伙伴。
1. 模型转换
1.1 PTQ
- Q:acrtan函数不支持 qtensor 如何解决?
A:pytorch里虽然有torch.arctan这个API,但是和torch.atan、包括onnx里面它也没有arctan的api,只有atan;部署过程中建议尽量保持op的统一。优先使用torch.atan,部署到onnx、量化等都统一用atan,onnx标准op支持atan,便于模型转换。 - Q:后处理部分想用int8怎么处理?
A:默认输出是S64的,可以在模型输出配置中设置batch为1,但后处理需要你自己做相应适配。 - Q:J5 v1.1.740 OE包汉化过程中calibration阶段精度下降?
A:这个版本默认打开了随机数种子,可能会有少量浮动精度影响,但在replace_function, wind_model_exec中使用--disable_softmax_checklevel参数可解决。 - Q:使用模型是docker版本的问题,是否建议用docker镜像?
A:建议,量化和部署都更容易一致,资源也配套。 - Q:模型结构中输入含空分支,怎么处理?
A:空分支也会生成一个节点,但ptq过程中需要量化所有节点,如果你的模型中有些分支在某些batch或阶段根本不会被调用,会影响转换结果,建议使用--keep_featuremap保留所有featuremap。 - Q:运行perf,报错unknown element type: bool8?
A:scatterND部署转成量化模型出现unknown element type: bool8问题,是OE docker环境中scatterND类型不支持。使用hrt_model_exec工具运行量化模型,不是在EOE docker中还是在量化模型会出现unknown element type: bool8 - Q:如何计算量化模型中pool耗时?
A:你好,通过分析,你可以将该层连接的某些量连接成以pool作为输出,自己推理后统计耗时。相比直接在硬件上说,计算量不算很大,不会太影响推理时间。下图的图像为某量干输入修改以pool输出统计时间,性能足够:
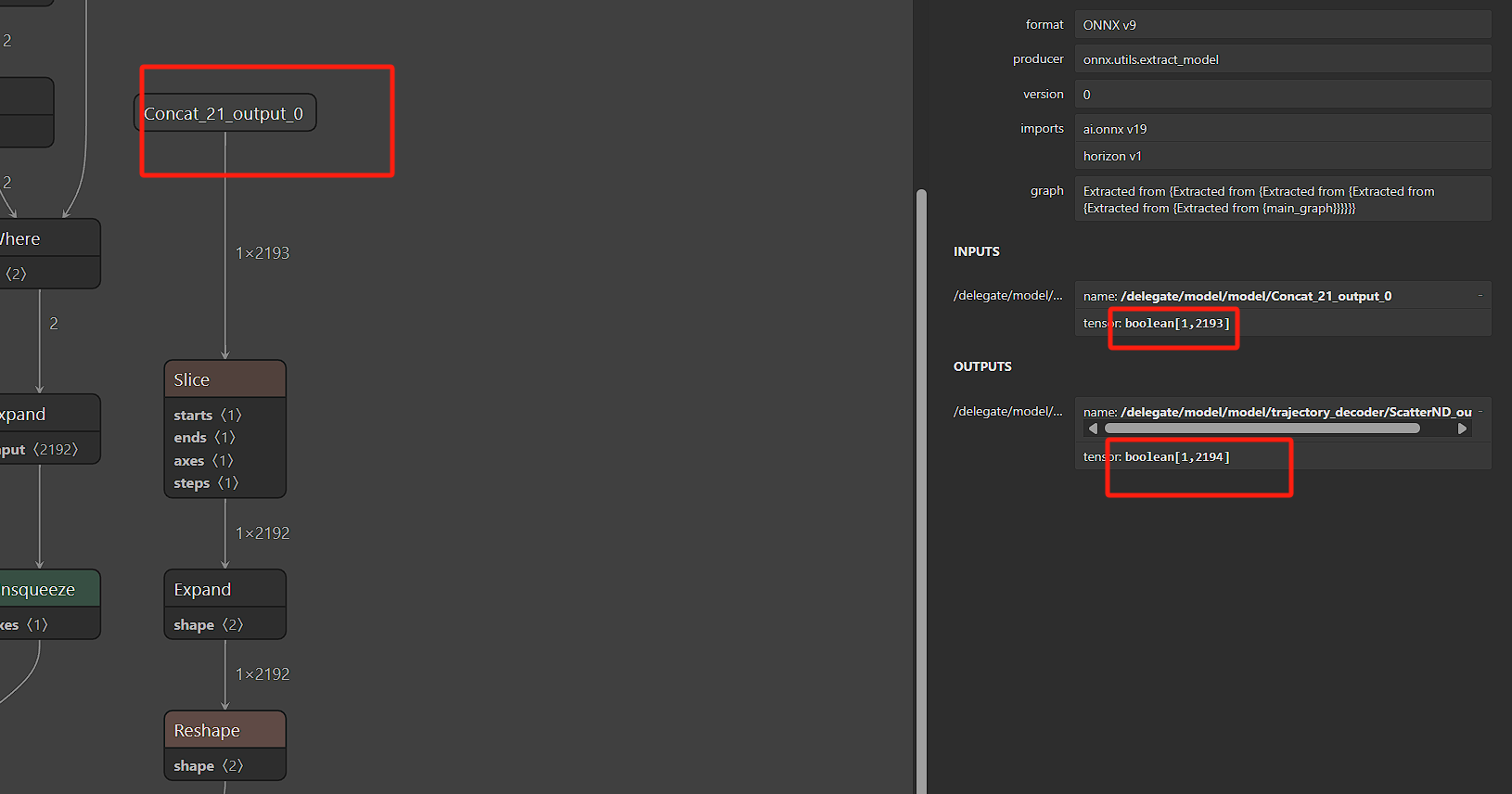
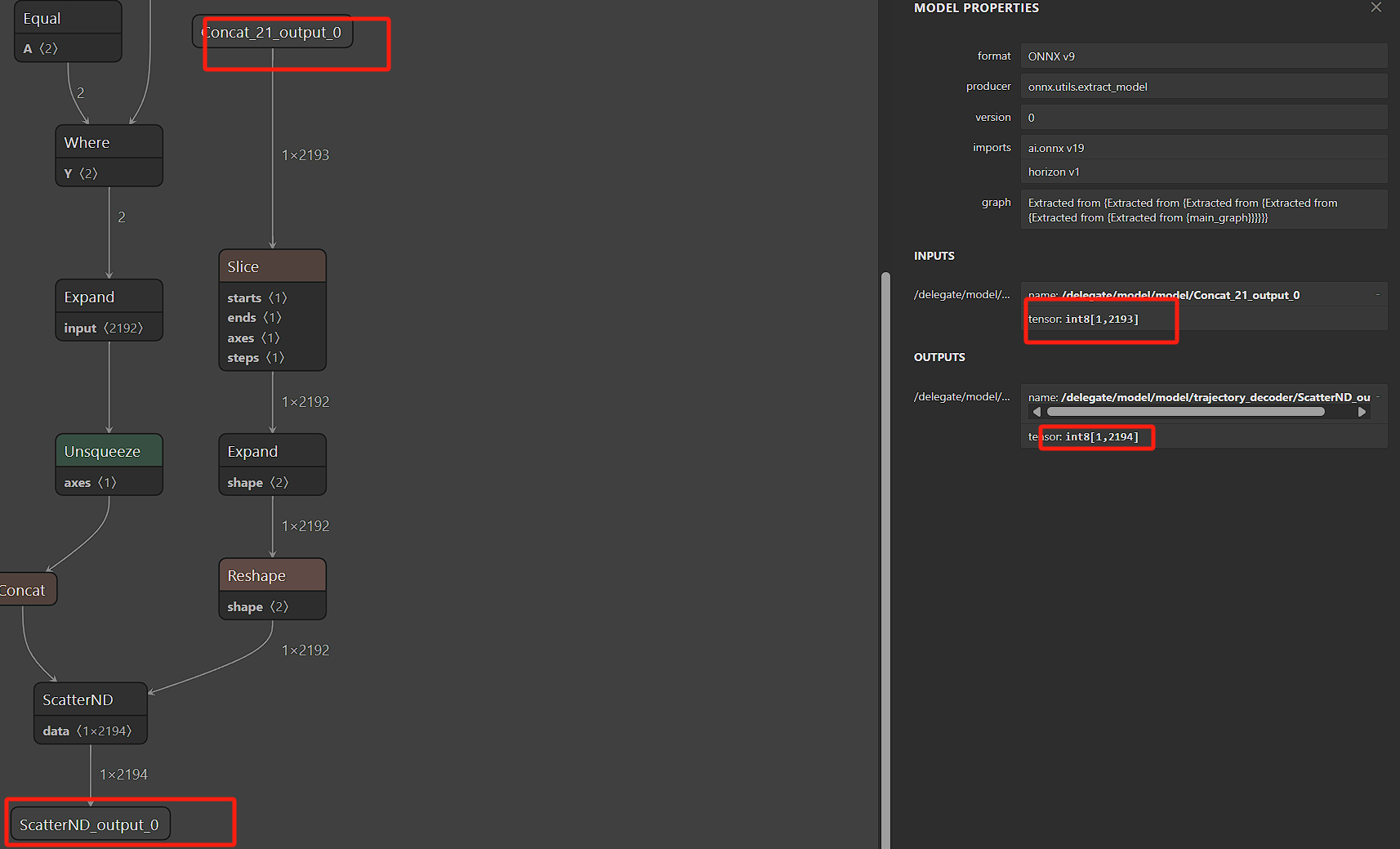
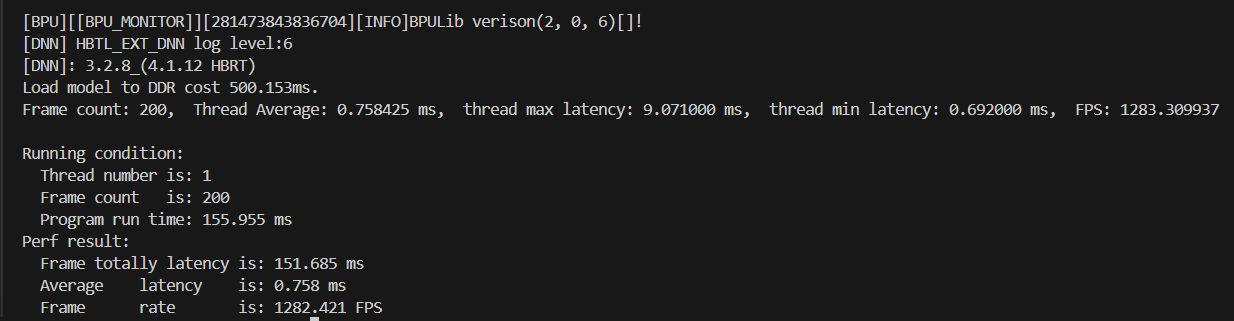
- Q:J6E ArgMax算子优化问题,OE3.0.31版本,在输出量需要与argmax和concat共享内存,torch.max输出的int64被转为int16会不准或者从板端看ints16,而与工具生成结果不符。
A:op.config配置模型是否开启的类型可根据类型描述信息配置,配置是否量化配置的是对量化模型生效,输出类型是工具转换后上下文支持判断,是否能下方给。 - Q:在fpn-like模块中,涉及三级分支处理:preprocess里的软连接拷贝处理、preprocess里的infer数据及temp输出、transformers和yaml文件的mm_type关联需要配套配置,量化结果如何保证正常结构和精度保留?
A:模型消除结构后同一化操作,例如在FPN中的yaml文件中添加多个不同的网络段,或者统一映射后重新接入主干结构,输出的数据结构可保留。涉及softmax类型不对齐中间层会产生中间推理结果,影响整体精度。可以根据模型结构在yaml中重新定义路径,新增相应的softmax节点并映射输入。量化过程需合理设置softmax及其量化参数,建议查看每层对应的quant_info与preprocess.py或模型转换过程输出日志。
1.2 QAT
- Q:模型中含自定义op实现,想要示例使用hb_mapper模型可视化或转换量化支持,含bn层、torch.op注册,如何将c++自定义op实现注册入*.bin文件?
A:- 需要提供c层,实现op注册,量化前需完成自定义op实现并注册入C代码逻辑。
修改CMakeLists.txt配置自定义op的实现文件路径,然后配合模型转换工具完成注册,注册指令如下所示:
- Q:不同分支量化精度差异大,部分节点卡住,转成qat后整体精度下降?
A:量化前尽可能保证网络结构一致性,转成qat前应检查模型输入输出一致性,注意张量尺寸对齐。精度下降多因量化前网络未训练充分,推荐以float模型为基准,转换后再训练优化。 - Q:qat方式量化得到的hb模型有什么方法可以看到模型的各个算子是在cpu还是bpu上运行的么?
A:可以在部署前的docker里面用hrt_model_info查看,里面各层含示意、板端各运算芯片信息。
2. 模型部署
- Q:BEV模型上板后输出问题。
A:参考官方文档或论坛输入数据准备和映射信息文档:参考链接。
BEV模型部署需同步输出字段,参考TcpUDP示例完成数据发布,排查主要模块:模型量化、模型转换、运行时配置、输入输出标记与映射信息。必要时可检查数据包头一致性与数据长度等。
3. 其他
- Q:hbDNNTensorProperties中内存统计怎么看算子粒度?
A:在模型转换过程中,板子环境可通过内核接口方式访问芯片功耗- /sys/devices/system/bpu/bpu0/ratio 或 读取hrt_ucp_monitor可查看bpu和npu信息,板端共享功耗数据对齐。
- Q:tmp_models文件夹需要自己创建吗?
A:在oe阶段一级目录下,5data、tmp_data等一级目录目录下。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)