
OpenDriveVLA:基于大规模视觉语言行动模型的端到端自动驾驶研究
论文信息
- 标题:OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
- 作者:Xingcheng Zhou*, Xuyuan Han, Feng Yang, Yunpu Ma, Alois C. Knoll
- 单位:慕尼黑工业大学等
- 项目地址:https://drivevla.github.io/
摘要
本文提出OpenDriveVLA——专为端到端自动驾驶设计的视觉语言行动(VLA)模型。该系统基于开源预训练大规模视觉语言模型(VLMs),通过三维环境感知、自车状态和驾驶员指令的多模态输入生成可靠驾驶动作。为弥合驾驶视觉表征与语言嵌入的模态差异,我们提出分层视觉语言对齐方法,将2D和3D结构化视觉标记投影至统一语义空间。此外,OpenDriveVLA通过自回归的智能体-环境-自车交互过程建模动态关系,确保空间与行为双重认知的轨迹规划。在nuScenes数据集上的大量实验表明,该系统在开环轨迹规划和驾驶问答任务中均达到最先进水平。定性分析进一步验证了OpenDriveVLA执行高级驾驶指令的能力,以及在复杂场景下稳健生成轨迹的优越性,彰显了其在新一代端到端自动驾驶中的应用潜力。
算法框架与部分实验
算法框架
OpenDriveVLA的整体架构如图所示,其多阶段训练流程在图中进一步详述。该系统始于预训练的视觉编码器,该编码器从多视角图像中提取出符号化的环境表征。这些视觉符号随后通过跨模态学习对齐到文本域。对齐完成后,OpenDriveVLA依次进行驾驶指令微调、智能体-自我-环境交互建模,最终通过端到端训练预测自车未来轨迹,整个过程由对齐的视觉-语言符号和驾驶指令共同指导。
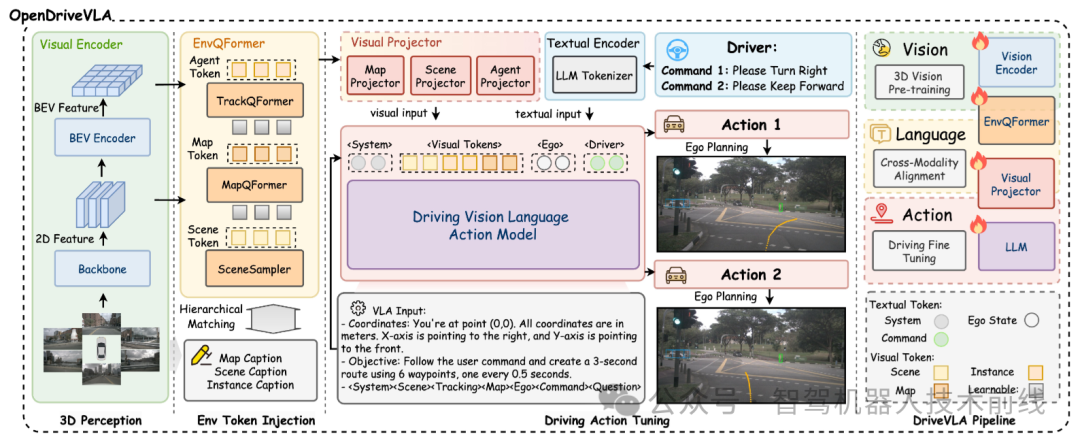
The overall architecture of OpenDriveVLA
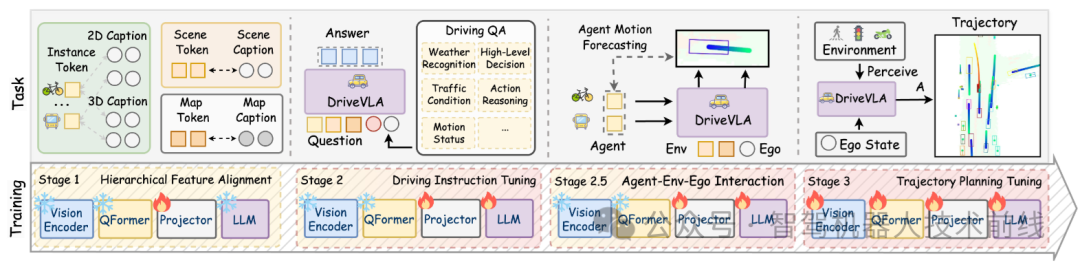
Illustration of main training stages on OpenDriveVLA, including the hierarchical cross-modality alignment, driving instruction tuning, agent-env-ego interaction, and trajectory planning tuning.
部分实验结果
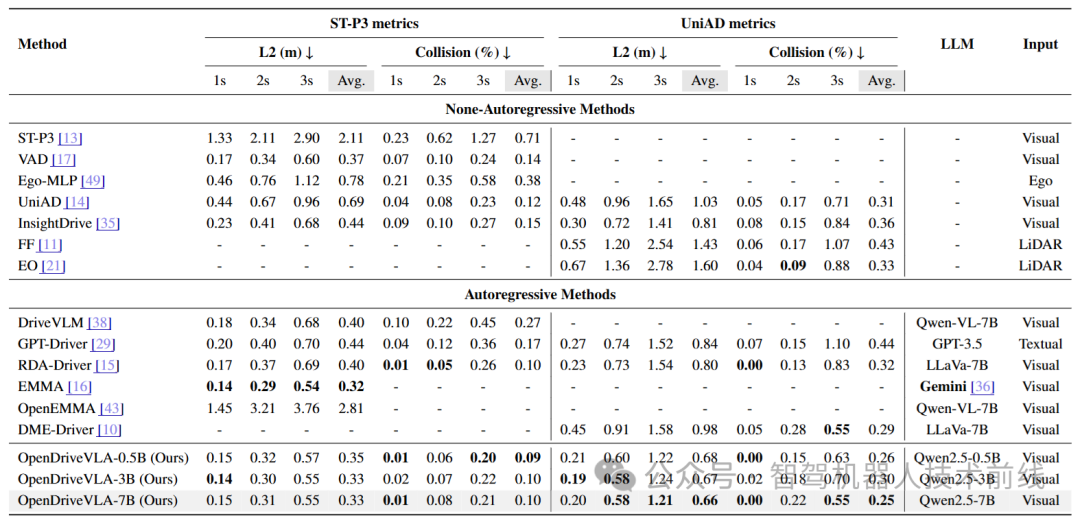
不同驾驶模型的开环规划性能对比,包含自回归与非自回归方法。OpenDriveVLA展现出强大的规划能力,在开源模型中取得最佳性能,即便是0.5B版本亦如此。数据引用自[15,23,29,35]的研究成果汇总。
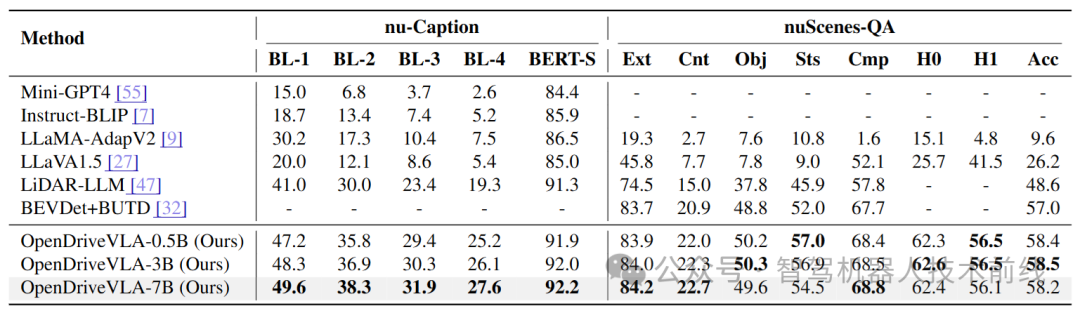
nuCaption[46]与nuScenes-QA[32]综合性能对比。BL-1/2/3/4对应不同n元语法BLEU分数,BERT-S指BERT-Score,nuScenes-QA下指标对应问题类型:Ext(存在性)、Cnt(计数)、Obj(物体)、Sts(状态)、Cmp(比较),Acc代表总体准确率。
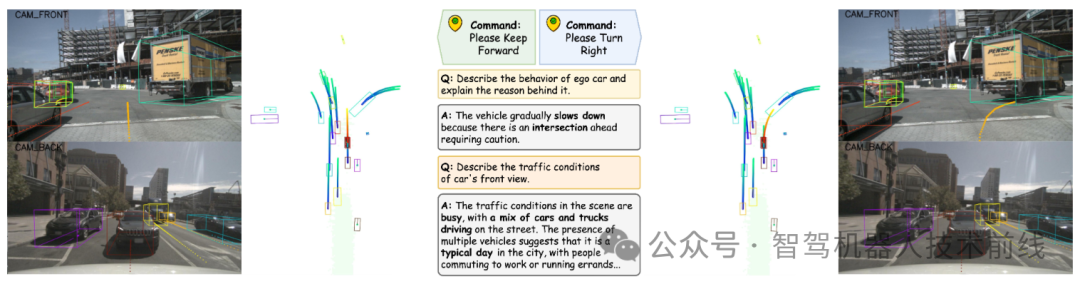
OpenDriveVLA-7B在不同驾驶指令下的规划动作可视化及视觉问答结果,智能体运动预测经agent-env-ego交互阶段生成,问答示例来自表3、4数据。
总结
本研究提出OpenDriveVLA(一种可扩展的视觉语言动作模型),专为端到端自动驾驶设计。通过利用预训练大型语言模型,OpenDriveVLA能生成可靠的驾驶动作。我们提出分层视觉语言特征对齐流程和智能体-环境-本体交互机制,以增强空间推理与轨迹预测能力。采用多阶段训练范式后,该模型在开环规划和驾驶相关问答任务中达到最先进性能。基于nuScenes数据集的广泛评估表明,相比现有自回归和端到端驾驶模型,OpenDriveVLA具有更优越的轨迹规划能力。本工作验证了可扩展视觉语言驱动方法在自动驾驶中的可行性,并凸显了大型语言模型作为端到端驾驶动作系统基础架构的潜力。
RAD:自动驾驶中基于视觉语言模型的元动作检索增强决策方法
论文信息
- 标题:RAD: Retrieval-Augmented Decision-Making of Meta-Actions with Vision-Language Models in Autonomous Driving
- 作者:Yujin Wang, Quanfeng Liu, Zhengxin Jiang, Tianyi Wang, Junfeng Jiao, Hongqing Chu∗, Bingzhao Gao, Hong Chen
- 单位:同济大学,耶鲁大学等
摘要
准确理解并决策高层元动作对确保自动驾驶系统可靠安全至关重要。尽管视觉语言模型(VLMs)在各类自动驾驶任务中展现出巨大潜力,但其存在空间感知不足和幻觉生成等缺陷,降低了在复杂驾驶场景中的有效性。为此,我们提出检索增强决策(RAD)框架——一种通过三阶段流程(嵌入流、检索流、生成流)动态提升决策精度的新型架构。该框架基于NuScenes数据集构建专用训练集对VLMs进行微调,显著增强了空间感知与鸟瞰图理解能力。在定制化NuScenes数据集上的实验表明,RAD在匹配准确率、F1分数及自定义综合评分等关键指标上均超越基线方法,验证了其在提升自动驾驶元动作决策效能方面的优越性。
算法框架与部分实验
算法框架
该框架包含四个工作流:嵌入流、检索流、微调流和生成流。嵌入流将前视图像和鸟瞰图(BEV)编码至向量数据库;给定查询场景时,检索流从数据库中检索最相似场景;微调流通过对VLMs进行微调来增强空间感知和BEV图像理解能力;生成流则引导VLMs根据查询场景、检索场景、其真实元动作及适当提示,生成符合上下文的元动作。
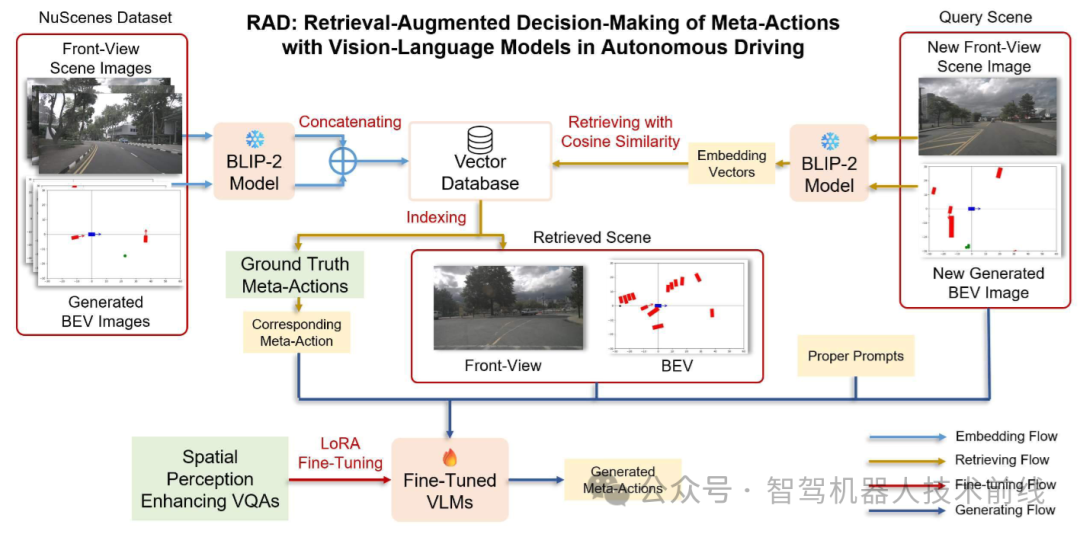
The overview of our RAD method.
部分实验结果
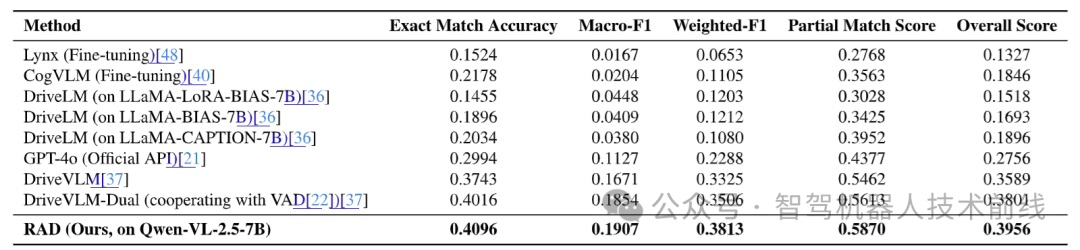
不同基线方法与RAD方法的对比
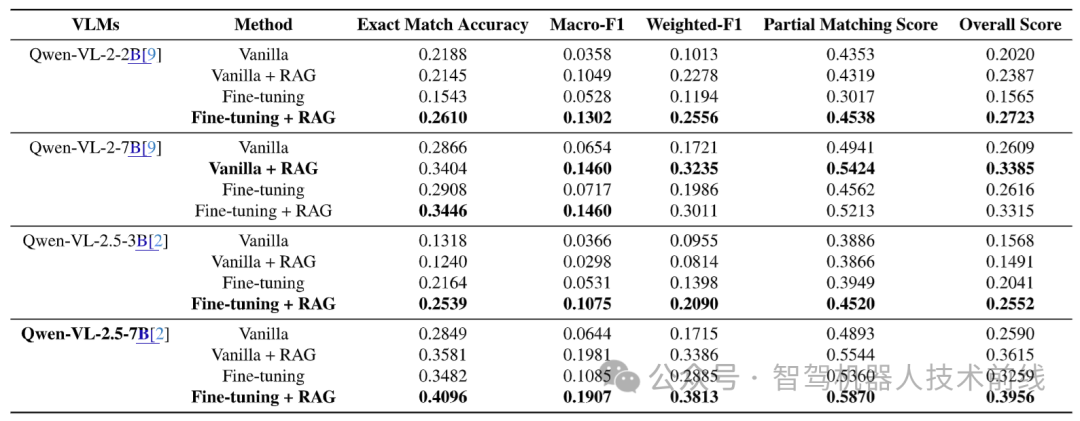
VLM微调与RAG流程的消融研究
总结
本研究提出的RAD框架是一种新型检索增强架构,旨在提升自动驾驶视觉语言模型的元动作决策能力。通过整合空间感知增强的VLM微调与鸟瞰图(BEV)图像理解,RAD显著提高了元动作决策的准确性,大量实验评估中关键指标的显著提升验证了该框架的有效性。
未来工作将围绕三个方向拓展:首先,计划引入超越NuScenes数据集的多样化细粒度数据,涵盖更具挑战性的极端案例和真实场景以增强模型鲁棒性;其次,致力于将RAD框架推广至轨迹规划与运动控制等驾驶任务;最后,在框架中整合思维链与强化学习对提升决策深度和适应性至关重要。虽然微调与RAG仍是增强VLM泛化能力的核心手段,但通过RAG方法处理复杂现实任务,这些进展将强化自动驾驶系统的稳健性与可靠性。
SimLingo:基于纯视觉与语言动作对齐的闭环自动驾驶系统
论文信息
- 标题:SimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment
- 作者:Katrin Renz∗, Long Chen, Elahe Arani, Oleg Sinavski
- 单位:Wayve, 蒂宾根大学
摘要
将大语言模型(LLM)整合到自动驾驶系统有望提升泛化能力和可解释 性,但现有方法往往仅关注驾驶或视觉语言理解,难以同时实现高性能驾驶与广泛语言理解。当前主流的视觉语言理解方法采用视觉问答(VQA),但这对自动驾驶只有在其与动作空间对齐时才有价值——否则模型的回答可能与其行为矛盾。为此,我们提出能同时处理三项任务的模型:(1)闭环驾驶 (2)视觉语言理解 (3)语言动作对齐。基于视觉语言模型(VLM)的SimLingo仅需摄像头,无需昂贵激光雷达。在Bench2Drive基准测试中,SimLingo在CARLA模拟器上取得最先进性能,并赢得2024年CARLA挑战赛冠军。在保持高驾驶性能的同时,该模型在各类语言相关任务中也表现优异。
算法框架与部分实验
算法框架
对图像、导航条件及语言提示进行编码处理。针对高分辨率图像,采用分块编码策略以复用预训练的448x448分辨率图像编码器。所有嵌入向量由经LoRA微调的大语言模型处理,用于预测语言输出和动作指令。动作输出采用解耦表征方式,同时包含时序速度航点和几何路径航点,以提升横向控制精度。

Overview: SimLingo is a vision-language-action model unifying the tasks of autonomous driving, vision-language understanding and language-action alignment. It is state of the art on the official CARLA Leaderboard 2.0 and Bench2Drive using only camera images. We introduce the task of Action Dreaming, a form of instruction following, to improve the alignment of language and action.
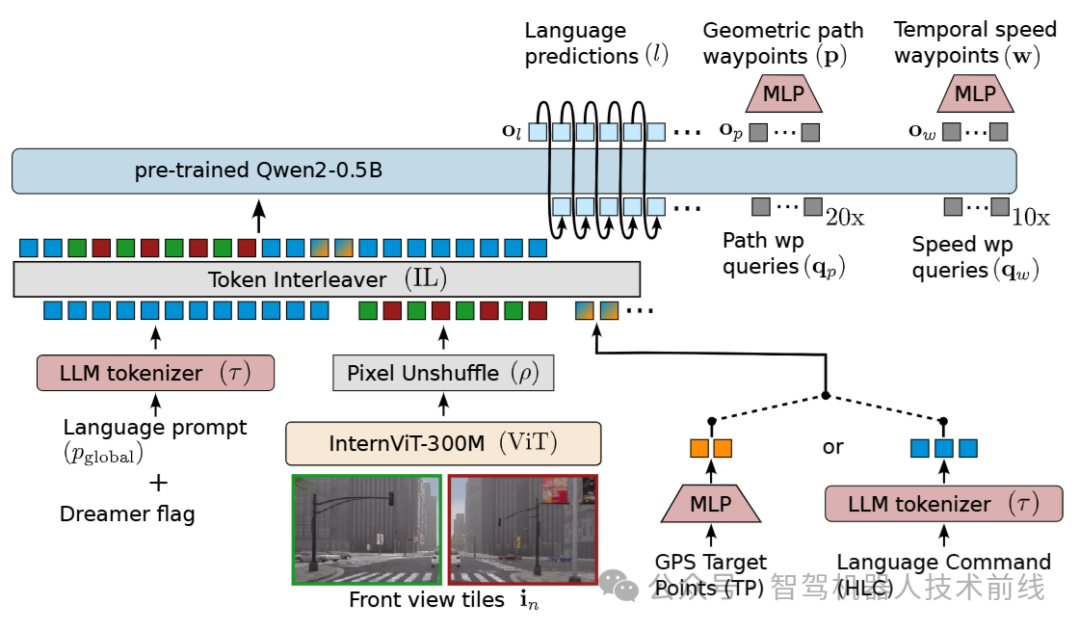
SimLingo architecture.
部分实验结果
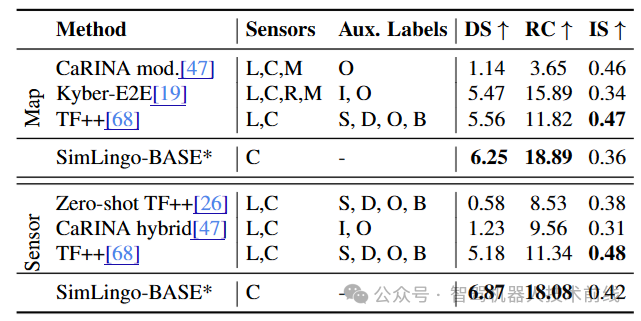
排行榜2.0结果。SimLingo-BASE在官方排行榜2.0上达到最先进性能。图例:L-激光雷达 C-摄像头 R-雷达 M-地图 priv-特权信息 O-3D物体检测 I-实例分割 S-语义分割 D-深度图 B-BEV语义 *为保持一致性,模型名称从CarLLaVA变更为SimLingo-BASE。
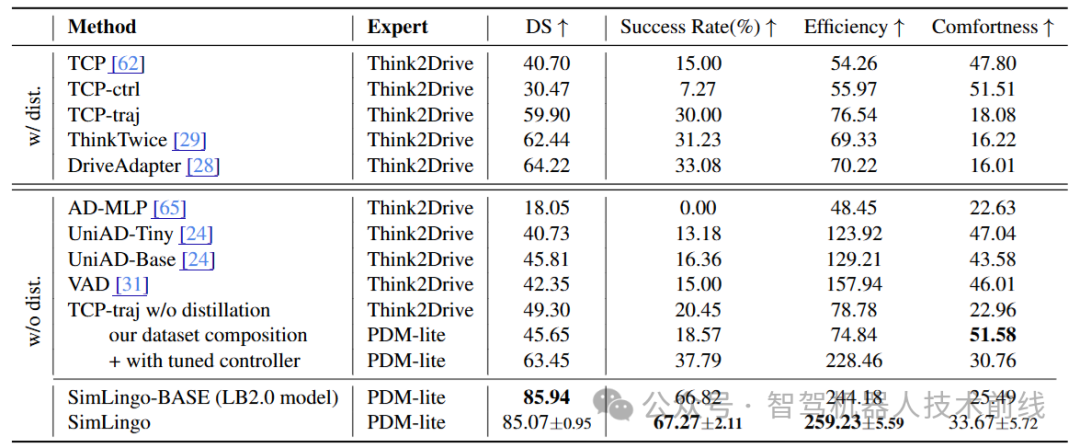
Bench2Drive闭环测试结果。我们的SimLingo-BASE基础模型与完整版SimLingo模型均大幅超越先前最优水平。特别指出,SimLingo在保留纯驾驶模型SimLingo-BASE性能的同时,整合了多项语言相关能力。
总结
我们提出SimLingo:基于视觉语言模型(VLM)的自动驾驶系统,在CARLA 2.0官方排行榜与Bench2Drive创下最优成绩,同时展现语言理解能力。通过驾驶解说与视觉问答测试,证明基础通用VLM(InternVL2)经微调后可胜任专业驾驶领域。为对齐视觉语言理解与动作空间,我们引入动作幻想任务,该模型对多样化语言指令的动作预测成功率显著。
局限。本研究存在若干限制:因技术及组织原因(排行榜于2024年6月关闭),我们仅测试了SimLingo-BASE在CARLA 2.0官方排行榜的表现,完整模型验证留待后续工作。但在Bench2Drive本地基准测试中,我们严格验证了SimLingo及其基础版的闭环驾驶性能。尽管采用思维链(CoT)技术(即通过中间解说词调节驾驶动作),尚未观测到统计学显著的驾驶改进(附录C.3),推测需特定CoT训练数据与方法才能发挥其优势。当前实验仅限模拟环境,实际部署视觉语言模型会增加推理延迟,但我们相信小型VLM的进展及工程优化(如[3,4])将推动车载实时测试。
本文仅用于学术交流,如有侵权,请联系删文!

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)